#xExcelConvertor
在游戏开发中经常会使用到大量的配置文件,这些配置文件一般是由策划在Excel中配置后,导出给程序使用的,但由于客户端或服务端使用的语言环境比较多样化,因此就搞出了这么个东东,目的是构建一个通用的并且可扩展的Excel导出工具。
#环境
xExcelConvertor使用Python编写,基于2.7.x版本(本人使用的是2.7.11),依赖Excel解析库openpyxl,安装完Python以及openpyxl之后,就可以直接使用xExcelConvertor将Excel中的各个工作表导出成各自想要的格式了。
#特性:
- 支持同时导出多种格式:Lua、PHP、XML、JSON、SQL、INI
- 支持多种格式的Excel文件:xlsx、xlsm、xltx、xltm(具体支持格式由openpyxl决定)
- 支持不同的格式导出到不同的目录
- 支持指定一个输入目录,将需要导出的Excel放入该目录中即可批量导出,该目录也支持递归处理(可关闭递归处理)
- 支持导出数据的格式化与否(仅XML及JSON格式),若对导出的配置文件体积比较敏感的,可以将数据格式化选项关闭
- 支持多语言字段导出(语言代码可以依各位童鞋的项目喜好而定)
- 支持折叠数据,每张数据表(工作表)只需要指定一个折叠的级别数即可支持(SQL、INI格式除外)
- 支持自定义Excel工作簿中每张工作表的导出格式,或关闭某(几)张工作表的导出
- 每张工作表的字段支持设置不同的导出格式,但工作表字段的导出格式受限于该工作表自身的导出格式(举个栗子:工作表Sheet1设置的导出格式为SQL、XML、PHP,因此Sheet1中配置的字段的导出格式最多也仅支持SQL、XML、PHP,多了也会被无视的- -#)
#全局导出配置说明
全局导出配置定义在export_config.ini文件中,其格式及说明如下:
[GLOBAL]
excel_directory = ${SCRIPT_PATH}../examples/ ; 要解析的Excel所在目录
deep_process = true ; 是否递归查找excel_directory配置的目录下的所有支持的文件
export_language = all ; 要导出的语言代码,固定值'all'(不含单引号)表示导出所有类型的语言,默认'all'
format_data = true ; 是否对导出的文件内容进行格式化,默认'false'
[COPYRIGHT]
organization = xLemon ; 版权所有者(例如公司,个人或组织)名称
since_year = 2015 ; 版权所有者(例如公司或组织)的起始年份
[EXPORT_LUA]
export_directory = ${SCRIPT_PATH}../export/lua ; 导出的Lua格式文件要保存的目录
export_language = jpn ; 删除该项则使用[GLOBAL]中的同名配置,否则使用当前section的配置
format_data = yes ; 删除该项则使用[GLOBAL]中的同名配置,否则使用当前section的配置
[EXPORT_XML]
export_directory = ${SCRIPT_PATH}../export/xml ; 导出的XML格式文件要保存的目录
export_language = chs ; 删除该项则使用[GLOBAL]中的同名配置,否则使用当前section的配置
format_data = no ; 删除该项则使用[GLOBAL]中的同名配置,否则使用当前section的配置
[EXPORT_PHP]
export_directory = ${SCRIPT_PATH}../export/php ; 导出JSON格式文件要保存的目录
export_language = eng ; 删除该项则使用[GLOBAL]中的同名配置,否则使用当前section的配置
[EXPORT_SQL]
export_directory = ${SCRIPT_PATH}../export/sql ; 导出的SQL格式文件要保存的目录
export_language = cht ; 删除该项则使用[GLOBAL]中的同名配置,否则使用当前section的配置
[EXPORT_JSON]
export_directory = ${SCRIPT_PATH}../export/json ; 导出的JSON格式文件要保存的目录
export_language = ara ; 删除该项则使用[GLOBAL]中的同名配置,否则使用当前section的配置
[EXPORT_INI]
export_directory = ${SCRIPT_PATH}../export/ini ; 导出的INI格式文件要保存的目录
export_language = kor ; 删除该项则使用[GLOBAL]中的同名配置,否则使用当前section的配置#全局导出配置关键项说明
- ${SCRIPT_PATH} : export_config.ini中唯一的一个占位符,配置文件中所有路径配置(excel_directory、export_directory 噫。。好像也就两个)除了可以配置绝对路径之外,还可以使用该占位符来表示相对路径,即xExcelConvertor入口脚本(即excel_convertor.py)所在路径。
- 布尔值参数赋值 : 所有布尔值参数(deep_process、format_data 噫。。好像也只有两个)的值,开启使用'true'或'yes'表示,关闭使用'false'或'no'表示,其他值均不支持。
- 导出格式配置 : export_config.ini以'EXPORT_'开头的section均表示对应导出格式的配置,但这里配置了某种格式不代表xExcelConvertor就支持了这个格式,具体支持的格式请往上看O_O,若想了解怎样扩展自己想要的格式,请往下看o_o
- export_language : 固定值'all'表示导出所有语言,若配置其它的语言代码(例如chs表示简体中文,cht表示繁体中文,eng表示英文;语言代码可以根据自身项目定义,xExcelConvertor没有做约束,只要同时导出的所有工作簿中保持统一即可)那么只会导出数据表中与配置的语言代码一致的列。当export_language的值配置为'all'时,若工作表的某个字段有配置语言代码,那么导出的实际字段名为'字段名_语言代码',否则导出的字段名为工作表中配置的字段名。
#Excel配置说明
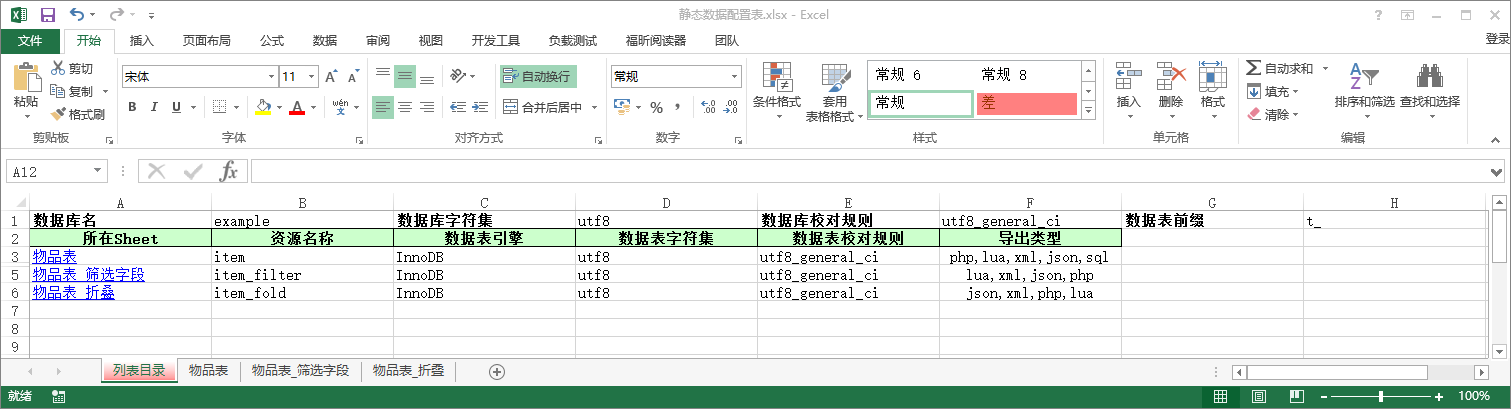
每个Excel工作簿都需要有一张作为索引的工作表来指定这个工作簿中的每个工作表的导出配置(这里暂且称作为**'列表目录'),并且作为索引的工作表必须**是工作簿中的第一个工作表,至于这个工作表的命名嘛,随便,因为取了名字也用不到它:)。
#Excel列表目录配置项
- 数据库 : **配置所在单元格 : B2,**该值将会被用于导出的SQL文件中,其他导出格式会忽略该值。
- 数据库字符集 : 配置所在单元格 : D2,,该值将会被用于导出的SQL文件中,其他导出格式会忽略该值。
- 数据库校对规则 : 配置所在单元格 : F2,,该值将会被用于导出的SQL文件中,其他导出格式会忽略该值。
- 数据表前缀 : 配置所在单元格 : H2,,该值将会被用于导出的SQL文件中,其他导出格式会忽略该值。若配置该值,那么在导出的SQL文件中,所有数据表的名称前面都会加上该前缀。
- 工作表 : 配置所在列 : A3:An,指定要导出的工作表的名称,必须是工作簿中某张存在的工作表的名称,当导出类型列有配置值时生效。
- 资源名称 : 配置所在列 : B3:Bn,实际导出的文件将以该值命名(SQL类型除外,若导出的是SQL文件,文件将以工作簿的名字命名,该列配置的值将作为数据表的名字),当导出类型列有配置值时生效。
- 数据表引擎 : 配置所在列 : C3:Cn,当导出类型列有配置值时(仅SQL导出类型)生效。
- 数据表字符集 : 配置所在列 : D3:Dn,当导出类型列有配置值时(仅SQL导出类型)生效。
- 数据表校对规则 : 配置所在列 : E3:En,当导出类型列有配置值时(仅SQL导出类型)生效。
- 导出类型 : **配置所在列 : F3:Fn,**可配置xExcelConvertor所支持的导出类型,可以配置多个类型,使用英文半角逗号隔开(如sql,xml,lua),若某一行不配置该值,那么在那一行对应的工作表将不会执行导出操作。
由于本人所在项目使用的是MySQL数据库,因此以上与数据库相关的部分均是以MySQL的特性来配置的(包括导出的SQL也是),若要支持其它数据库,请童鞋们自行扩展。
列表目录截图如下,若无法看到截图,那么可以在examples目录下的任意一份Excel工作簿中看到。
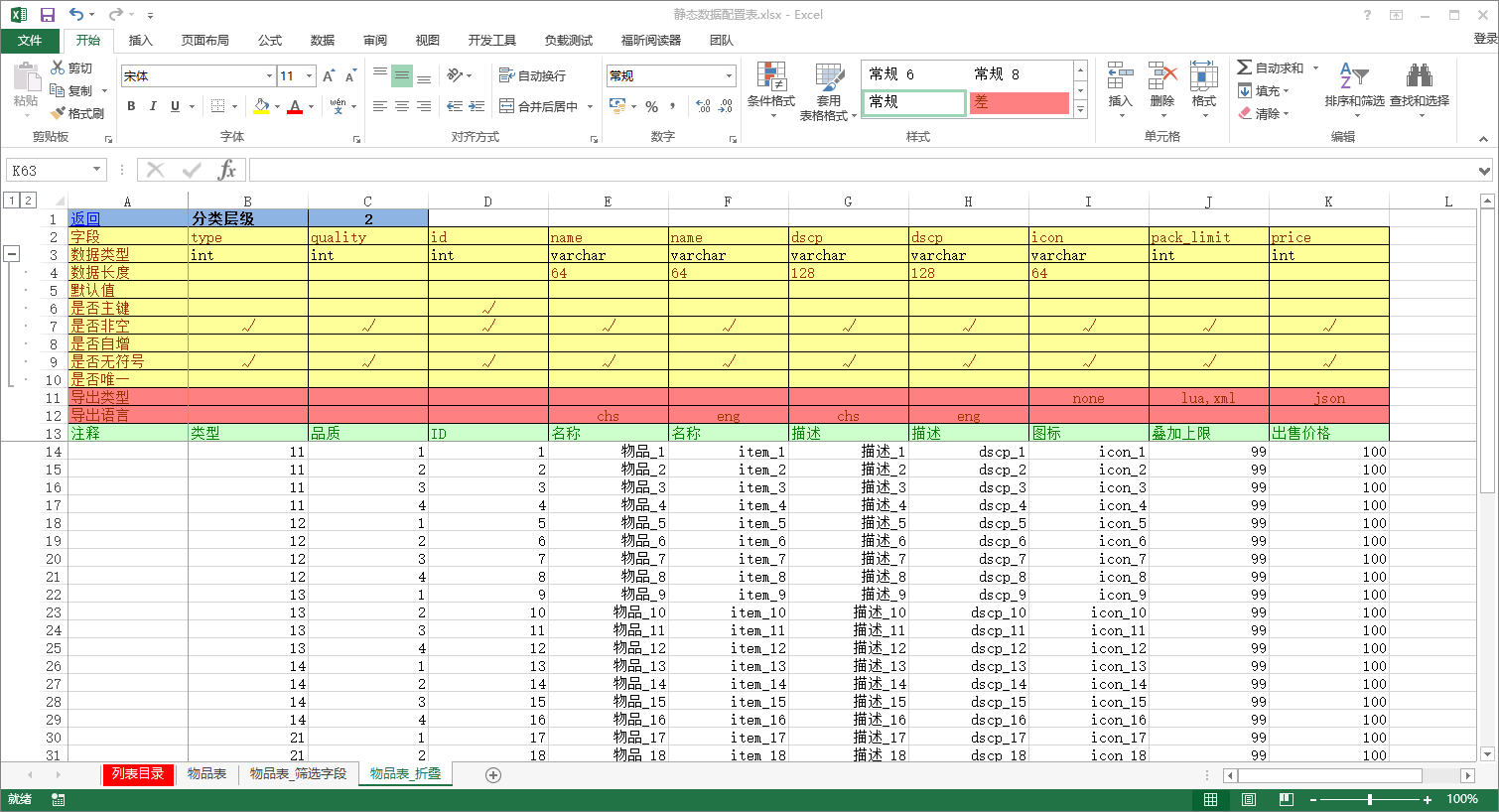
#Excel工作表配置项
工作表的前13行都作为保留行,均为配置项(表头),数据配置从第14行开始配置(第一列固定忽略):
- 行1:导航栏,配置快捷返回列表目录的链接(可选)以及分类层级(即数据折叠)的层次配置(C1单元格)
- 行2:字段名,必填
- 行3:数据类型,必填,目前支持根据MySQL数据类型定义,支持的数据类型有tinyint、smallint、mediumint、int、bigint、char、varchar、tinytext、text、longtext,不同的数据类型决定该列配置的数据是字符串(char、varchar、tinytext、text、longtext)还是数字(tinyint、smallint、mediumint、int、bigint)。
- 行4:数据长度,在导出SQL时使用到的长度(用于建表语句),其中字符串类型的数据必须配置数据长度,数字型的若不配置将按MySQL类型对应的默认长度填充。
- 行5:默认值,可选,若不配置,数字类型的默认值为0,字符串类型的默认值为空字符串''(不是null)。
- 行6:是否主键,可选,若配置将在导出SQL的建表语句中讲该列的字段加入主键索引。
- 行7:是否非空,可选,若配置将在导出SQL的建表语句将该列的字段加上NOT NULL关键字。
- 行8:是否自增,可选,若配置将在导出SQL的建表语句将该列的字段加上AUTO_INCREMENT关键字。
- 行9:是否无符号,可选,若配置将在导出SQL的建表语句将该列的字段加上UNSIGNED关键字。
- 行10:是否唯一,可选,若配置将在导出SQL的建表语句中讲该列的字段加入唯一性约束。
- 行11:导出类型,可选,若不配置或配置了'all',表示导出列表目录中该工作表配置的所有导出类型,填写'none'表示该字段不导出,填写部分导出类型表示仅对填写的这部分类型导出(如:列表目录中配置的导出格式为'sql,xml,lua',那么这里如果不配置任何值,那么默认将该字段导出到sql、xml、lua文件中,若配置'none',则表示该字段不导出,若配置'sql,lua',表示仅在sql和lua中导出、xml中忽略,若配置了'lua',表示仅在lua文件中导出)
- 行12:导出语言,可选,若不配置或配置了'all',默认将导出该字段,若配置了语言代码(仅允许配置一种语言代码),那么将会根据export_config.ini中定义的export_language选项导出该字段,具体参考Excel列表目录配置项中的说明。
- 行13:注释,可选,若配置将在导出SQL时作为字段注释加入建表语句中。
#关于数据折叠
直接描述有点复杂,我们直接来看个栗子,假设我们有一张物品的配置表:
| ID | 名称 | 描述 | 图标 | 类型 | 品质 | 叠加上限 | 出售价格 |
|---|---|---|---|---|---|---|---|
| 1 | 物品_1 | 描述_1 | 图标_1 | 1 | 1 | 99 | 100 |
| 2 | 物品_2 | 描述_2 | 图标_2 | 1 | 2 | 99 | 100 |
| 3 | 物品_3 | 描述_3 | 图标_3 | 2 | 1 | 99 | 100 |
| 4 | 物品_4 | 描述_4 | 图标_4 | 2 | 2 | 99 | 100 |
| 5 | 物品_5 | 描述_5 | 图标_5 | 3 | 1 | 99 | 100 |
| 6 | 物品_6 | 描述_6 | 图标_6 | 3 | 2 | 99 | 100 |
| 7 | 物品_7 | 描述_7 | 图标_7 | 4 | 1 | 99 | 100 |
| 8 | 物品_8 | 描述_8 | 图标_8 | 4 | 2 | 99 | 100 |
当不对数据进行折叠时(分类层级 = 0),是正常的按行导出,以json格式为例,导出结果如下:
{
"datas" : [
{ "id" : 1, "name" : "物品_1", "dscp" : "描述_1", "icon" : "icon_1", "type" : 1, "quality" : 1, "pack_limit" : 99, "price" : 100},
{ "id" : 2, "name" : "物品_2", "dscp" : "描述_2", "icon" : "icon_2", "type" : 1, "quality" : 2, "pack_limit" : 99, "price" : 100},
{ "id" : 3, "name" : "物品_3", "dscp" : "描述_3", "icon" : "icon_3", "type" : 2, "quality" : 1, "pack_limit" : 99, "price" : 100},
{ "id" : 4, "name" : "物品_4", "dscp" : "描述_4", "icon" : "icon_4", "type" : 2, "quality" : 2, "pack_limit" : 99, "price" : 100},
{ "id" : 5, "name" : "物品_5", "dscp" : "描述_5", "icon" : "icon_5", "type" : 3, "quality" : 1, "pack_limit" : 99, "price" : 100},
{ "id" : 6, "name" : "物品_6", "dscp" : "描述_6", "icon" : "icon_6", "type" : 3, "quality" : 2, "pack_limit" : 99, "price" : 100},
{ "id" : 7, "name" : "物品_7", "dscp" : "描述_7", "icon" : "icon_7", "type" : 4, "quality" : 1, "pack_limit" : 99, "price" : 100},
{ "id" : 8, "name" : "物品_8", "dscp" : "描述_8", "icon" : "icon_8", "type" : 4, "quality" : 2, "pack_limit" : 99, "price" : 100}
]
}但假如我们想要在代码中直接获取类型 = 1,并且品质 = 2的物品数据时就不那么方便了,因此我们可以对这张表的数据进行折叠。首先,为了满足这样的要求,需要调整下字段的顺序,将类型和品质字段提到头两个字段,改动后的配置表如下:
| 类型 | 品质 | ID | 名称 | 描述 | 图标 | 叠加上限 | 出售价格 |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 物品_1 | 描述_1 | 图标_1 | 99 | 100 |
| 1 | 2 | 2 | 物品_2 | 描述_2 | 图标_2 | 99 | 100 |
| 2 | 1 | 3 | 物品_3 | 描述_3 | 图标_3 | 99 | 100 |
| 2 | 2 | 4 | 物品_4 | 描述_4 | 图标_4 | 99 | 100 |
| 3 | 1 | 5 | 物品_5 | 描述_5 | 图标_5 | 99 | 100 |
| 3 | 2 | 6 | 物品_6 | 描述_6 | 图标_6 | 99 | 100 |
| 4 | 1 | 7 | 物品_7 | 描述_7 | 图标_7 | 99 | 100 |
| 4 | 2 | 8 | 物品_8 | 描述_8 | 图标_8 | 99 | 100 |
之后我们来看折叠的层次,也就是工作表中的'分类层级',从上面的需求来看,这里我们需要根据物品表的类型和品质进行分类,分类的目的在于:
- 物品数据根据品质进行分类
- 物品的品质根据类型进行分类
因此可以看出,我们的折叠的层次(分类层级)设置成2即可,2表示从有效数据的第一列开始,对多少个有效列进行分类。 什么是有效列呢?简单来说就是实际导出的时候将会被导出的列。接下来再来看这样分类(折叠)之后导出的json格式:
{
"1" : {
"1" : { "type" : 1, "quality" : 1, "id" : 1, "name" : "物品_1", "dscp" : "描述_1", "icon" : "icon_1", "pack_limit" : 99, "price" : 100},
"2" : { "type" : 1, "quality" : 2, "id" : 2, "name" : "物品_2", "dscp" : "描述_2", "icon" : "icon_2", "pack_limit" : 99, "price" : 100}
},
"2" : {
"1" : { "type" : 2, "quality" : 1, "id" : 3, "name" : "物品_3", "dscp" : "描述_3", "icon" : "icon_3", "pack_limit" : 99, "price" : 100},
"2" : { "type" : 2, "quality" : 2, "id" : 4, "name" : "物品_4", "dscp" : "描述_4", "icon" : "icon_4", "pack_limit" : 99, "price" : 100}
},
"3" : {
"1" : { "type" : 3, "quality" : 1, "id" : 5, "name" : "物品_5", "dscp" : "描述_5", "icon" : "icon_5", "pack_limit" : 99, "price" : 100},
"2" : { "type" : 3, "quality" : 2, "id" : 6, "name" : "物品_6", "dscp" : "描述_6", "icon" : "icon_6", "pack_limit" : 99, "price" : 100}
},
"4" : {
"1" : { "type" : 4, "quality" : 1, "id" : 7, "name" : "物品_7", "dscp" : "描述_7", "icon" : "icon_7", "pack_limit" : 99, "price" : 100},
"2" : { "type" : 4, "quality" : 2, "id" : 8, "name" : "物品_8", "dscp" : "描述_8", "icon" : "icon_8", "pack_limit" : 99, "price" : 100}
}
}这样就能达到我们的要求了,实际的栗子可以在example中找到,童鞋们可以亲自动手导出试试。
#导出格式的扩展
xExcelConvertor支持对导出格式的扩展,所有支持的导出格式操作类都存放于excel_convertor/processors/目录下,若要增加某种格式的支持,请按以下步骤操作(这里以新增csv格式为例):
- 在excel_convertor/processors/目录下新增processor_csv.py文件,文件名必须以'processor_'开头。
- 在excel_convertor/processors/init.py中新增一行
from .processor_csv import *- 在excel_convertor/processors/processor_csv.py中创建实现类,实现类必须继承自xBaseProcessor,并以xProcessor + 导出格式类型名称(首字母大写,其余小写)命名,在本例即xProcessorCsv
- 初始化并实现父类接口,一个空的扩展类代码如下,ProcessExport即为每个工作表的导出处理函数。
from __future__ import absolute_import
from __future__ import unicode_literals
from core.base_processor import xBaseProcessor
class xProcessorCsv(xBaseProcessor) :
def __init__(self) :
return super(xProcessorCsv, self).__init__('CSV')
def ProcessExport(self, p_strWorkbookName, p_cWorkbook, p_cWorkSheet, p_mapExportConfigs, p_mapDatabaseConfigs, p_mapIndexSheetConfigs, p_mapDataSheetConfigs, p_mapPreloadDataMaps, p_nCategoryLevel) :
return True- 在export_config.ini中增加CSV导出配置,ini中的section必须以'EXPORT_'开头。
[EXPORT_CSV]
export_directory = ${SCRIPT_PATH}../export/csv ; 导出的CSV格式文件要保存的目录