Python and Common Lisp code for generating the Higher-order Network (HON) from data with higher-order dependencies.
- Input: Trajectories / sequential data, such as ship movements among ports, a person's clickstream of websites, and so on.
- Output: HON edges in triplets [FromNode],[ToNode],[weight] as csv file.
Now parameter-free and magnitudes faster than the previous version!
Import BuildRulesFastParameterFree.py instead of BuildRules.py. More documentation coming soon.
Refer to the paper Detecting Anomalies in Sequential Data with Higher-order Networks.
Before trying out the code, please see demonstrations first at HigherOrderNetwork.com. A video demo will also be available soon on this website.
Algorithm details in paper Representing higher-order dependencies in networks. Related papers, slides, tutorials available in the "papers" folder.
HON currently has implementations in Python (in the folder pyHON) and Common Lisp (in the folder cl-HON), both tested on Linux, Windows and Mac.
The Common Lisp implementation is the initial version used for the Science Advances experiments. It is faster than the Python implementation in most cases (can usually finish processing a network in a few seconds). For large or very complex data sets, it may require additional arguments for the compiler, since the default heap size in Common Lisp compilers are generally small.
The Python implementation should yield identical results to the Common Lisp version. While it might be slower to execute, it is more readable as it is almost a line-by-line conversion from the Pseudocode in the [Xu et al. 2016] paper. It can also scale up for big data without worrying about memory allocation, and can be easily parallelized.
Tested with recent version of Python3, should work with recent version of Python2.
Download Anaconda with Python3; download PyCharm.
Bare Python and run in command line / terminal.
Follow this tutorial to set up Emacs, SBCL, Quicklisp and SLIME.
After installing Quicklisp, call (ql:quickloads :split-sequence) to install the split-sequence package.
Install SBCL and QuickLisp. Call (ql:quickloads :split-sequence) to install the package.
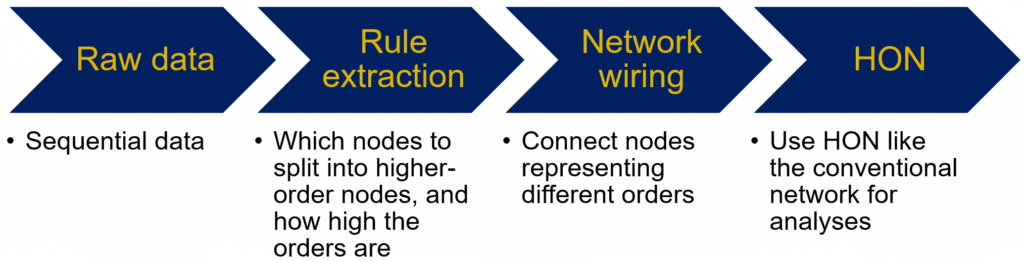
The workflow to construct the higher-order network is as follows: given the raw sequential data, we first decide which nodes need to be split into higher-order nodes, and how high the orders are; then we connect nodes representing different orders of dependency. Finally the output is the higher-order network, which can be used like conventional network for analyses.
Python: run main.py to execute all procedures.
Common Lisp: run build-rules.lisp and build-network.lisp separately.
Extracts higher and variable orders of dependencies from sequential data.
This corresponds to Algorithm 1 in paper.
Python: included when running main.py
Common lisp: Using Emacs and SLIME: open build-rules.lisp, press CTRL+C twice to compile, run (main). Using Minimal environment: run sbcl, run twice (load "build-rules"), run (main).
Trajectories / sequential data. See ./data/traces-simulated-mesh-v100000-t100-mo4.csv for example.
In the context of ship movements, every line is a ship's trajectory, in the format of [ShipID] [Port1] [Port2] [Port3] ...
Notice that the first element of every line is the ship's ID.
ShipID and PortID can be any integer.
Python: can be any character except space.
Common Lisp: Non-integers can be used if function parse-lists-for-integer is removed from (main).
Other types of trajectories or sequential data can be used, such as a person's clickstream of websites, music playing history, sequences of check-ins, and so on.
To process diffusion procedures, treat the whole process as a combination of many SubSequences.
Variable orders of "rules" extracted from the sequential data. See rules-simulated-mesh-v100000-t100-mo4-kl.csv for example.
Every line of record represents a "rule", which is the (normalized) probability of going to [TargetPort] from [PreviousPorts], in the format of ... [PrevPrevPort] [PrevPort] [CurrPort] => [TargetPort] [Probability].
For example, the line 19 29 39 => 49 0.24421781 means if a ship which is currently at port 39, coming from port 29, and one more previous step is 19, the ship's probability of going to port 49 is 0.24421781
If you want to output the number of observations instead of the normalized probability:
Python: Change AddToRules() from adding Distributions{} to adding Count{}
Common Lisp: in function (add-to-rules), change the dictionary of distributions to the length of the source nodes's value in observations, and remove (clrhash observations) in (build-distributions)
Python: Parameters are at the beginning of the file main.py, with naming conventions slightly different than that of Common Lisp.
Common Lisp: Parameters are at the beginning of the file build-rules.lisp, starting with defparameter.
You may want to test the code with the synthetic trajectory first. Remember to use the file in ../data/
For each path, the rule extraction process attempts to increase the order until the maximum order is reached. The default value of 5 should be sufficient for most applications. Setting this value as 1 will yield a conventional first-order network. Discussion of this parameter (how it influences the accuracy of representation and the size of the network) is given in the supporting information of the paper.
Common Lisp: Setting this parameter too large may result in (1) long running time and/or (2) exhausting the heap and die silently (run sbcl with larger dynamic-space-size). Try increasing the value of this parameter progressively: if max-order is 5 but the rules extracted show at most 3rd order, then there is no need to further increase the max-order.
Observations that are less than min-support are discarded during preprocessing.
For example, if the patter [Shanghai, Singapore] -> [Tokyo] appears 500 times and [Zhenjiang, Shanghai, Singapore] -> [Tokyo] happened only 3 times, and min-support is 10, then [Zhenjiang, Shanghai, Singapore] -> [Tokyo] will not be considered as a higher-order rule.
This parameter is useful for filtering out infrequent patterns that might be considered as higher-order rules. Setting a reasonable min-support can (1) considerably decrease the network size and the time needed for computation and (2) potentially improving representation accuracy by filtering out noise. Discussion of this parameter (how it influences the accuracy of representation and the size of the network) is given in the supporting information of the paper.
To skip this filter, set the value as 1.
Python: not implemented
Trajectories shorter than the given value are discarded during preprocessing. Useful for filtering out inactive individuals.
To skip this filter, set the value as 1.
Python: not implemented
Trajectories longer than the given value are discarded during preprocessing. Useful for filtering out abnormally long trajectories that dominate the network construction (generated by bots / faulty sensor data etc).
To skip this filter, set the value as 999999 or larger.
The last given steps in each trajectory are not used to for network construction (reserved for testing).
To use full trajectories, set this value as 0.
max-order + digits-for-testing should be smaller or equal to min-length-of-trajectory.
Python: not implemented
Exclude certain locations that want to be excluded from trajectories. Useful for preprocessing. Default not used. To enable this filter, change the value from nil to t and change the list in function (filter-by-bots).
Python: not implemented. KL divergence is used by default, and uses the auto-adapting threshold in the [Xu et al. 2016] paper.
The method used for comparing different probability distributions of choosing the next step, when extending the knowledge of previous locations. Default is KL-divergence, which is self-adaptable to paths of variable support / orders.
Common Lisp: To use cosine similarity, set the parameter as "cosine" and set the parameter distance-tolerance, which means if the cosine similarity of the two distributions is smaller than 0.9, the two distributions are considered significantly different.
Given the higher-order rules extracted in the last step, convert them to a network representation.
This corresponds to Algorithm 2 in paper.
Python: included when running main.py
Common Lisp: Using Emacs and SLIME: open build-network.lisp, press CTRL+C twice to compile, run (main). Using Minimal environment: run sbcl, run twice (load "build-network"), run (main).
The file containing rules produced by the last step.
HON edges in triplets [FromNode],[ToNode],[weight]
For example, a line 39|29.19,49|39.29.19,0.24421781 means: A node "39|29.19" has an edge pointing to node "49|39.29.19", and the edge weight is 0.24421781
Default weight is the probability of a random walker going from [FromNode] to [ToNode]. If you want to output the number of observations instead of the normalized probability, follow previous instructions.
Every node can be a higher-order node, in the format of [CurrNode]|PrevNode.PrevPrevNode.PrevPrevPrevNode
All nodes (first-order and higher-order) starting with the same [CurrNode]| represent the same physical location.
This representation (as comma deliminated network edges file) is directly compatible with the conventional network representation and analysis tools. The only difference with the conventional network is edge labels. The csv file can be fed into many other network analysis tools (such as Gephi, NetworkX and so on) that are originally designed for first-order networks.
Python: No need to set the parameters. Common Lisp: Parameters are at the beginning of the file build-network.lisp, starting with defparameter.
Use the same value as in build-rules.lisp
The script ./applications/synthesize-trace-mesh.py (run with python or python3) synthesizes trajectories of vessels going certain steps on a 10x10 grid (with wrapping). See details in the methods part of the paper.
Normally a vessel will go either up/down/left/right with the same probability (see function NextStep), (vessel movements are generated almost randomly with the following exceptions).
We add a few higher order rules to control the generation of vessel movements: 2nd order rule: if vessel goes right from X0 to node X1 (X means a number 0-9), then the next step will go right with probability 70%, go down 30% (see function BiasedNextStep). 3rd order rule: if vessel goes right to node X7 then X8, then the next step will go right with probability 70%, go down 30%. 4th order rule: if vessel goes down from 1X to 2X to 3X to 4X, then the next step will go right with probability 70%, go down 30%. There are ten 2nd order rules, ten 3rd order rules, ten 4th order rules, no other rules.
It is not feasible to add rules beyond third order using the same setting in paper, because movements matching multiple previous steps will unlikely happen. However you can use a different setting to generate even higher orders.
Default setting simulates movements of 100,000 vessels, each vessel visits 100 ports following the aforementioned process. Thus 10,000,000 movements will be generated by default.
Data generated using the aforementioned script is provided as traces-simulated-mesh-v100000-t100-mo4.csv
Use HON with a default setting of MaxOrder = 5, MinSupport = 5. It should be able to detect all 30 of these rules of various orders, while not detect "false" dependencies beyond the 4th order. The result is provided as rules-simulated-mesh-v100000-t100-mo5-ms5-t01.csv
note that for illustration here (since we are not going to build a network now), in this file when higher order rules are detected, corresponding lower order rules are not added recursively. If all preceding rules are added, following the algorithm in the paper, the expected result should be rules-simulated-mesh-v100000-t100-mo4-kl.csv.
The whole time to process these 10,000,000 movements should be under 5 seconds (single thread, excluding disk IO time). Can be improved by using parallelization (needs compiler that enables parallelization), see comments in code for details.
Now HON can be used as if it is a first-order network, for applications such as PageRank, clustering and others.
For the result of PageRank, every (higher-order) node will have a PageRank value. For multiple nodes representing the same entity, such as Singapore|Shanghai and Singapore|Tokyo, the PageRank value of "Singapore" is the sum of all higher-order nodes "Singapore|xxx,xxx,...".
We provide the code for post-processing PageRank values, to illustrate how such post-processing of HON analysis results can be written in a few lines of code. The code is "./applications/hon-pagerank.py", written in Python, requires the networkx package for PageRank.
Q: Using Common Lisp, running large data sets gives "scbl exception Heap exhausted during garbage collection" error?
A: Use sbcl --dynamic-space-size 8Gb when running the sbcl lisp interpreter. If you use Emacs, add the "--dynamic-space-size 8Gb" to the inferior lisp command.
A: The whole process should typically finish within 1 minute and in most cases no more than 10 seconds. If no output is produced in a long time, check CPU utilization to see if the program is still running. If you use Emacs+SLIME, check the inferior-lisp buffer to see if heap has been exhausted and the interpreter has failed silently. Apply the tip above to increase the heap size.
A: We are currently working on a visualization and interactive exploration software package which will be available for download soon. Please check back later at HigherOrderNetwork.com.
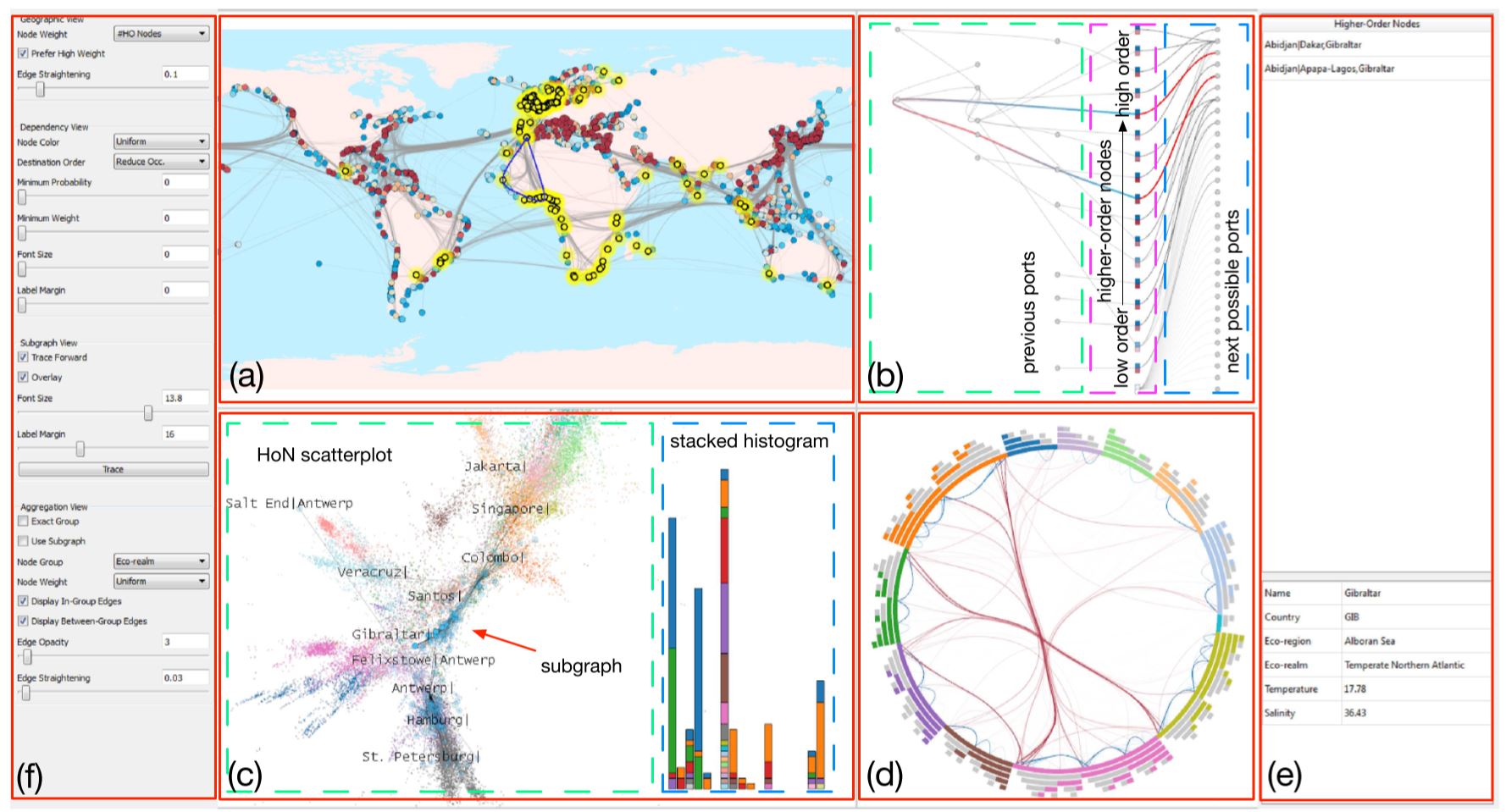
Before that, one can simply use the output csv file of this code for existing software packages such as Gephi.
Jian Xu, Thanuka L. Wickramarathne, and Nitesh V. Chawla. "Representing higher-order dependencies in networks." Science Advances 2, no. 5 (2016): e1600028.
Jian Xu, Mandana Saebi, Bruno Ribeiro, Lance M. Kaplan, and Nitesh V. Chawla. "Detecting Anomalies in Sequential Data with Higher-order Networks." arXiv preprint arXiv:1712.09658 (2017).
Please contact Jian Xu (jxu5 at nd dot edu) for technical questions.