本教程是教程是介绍如何使用Tensorflow实现的MTCNN和MobileFaceNet实现的人脸识别,并不介绍如何训练模型。关于如何训练MTCNN和MobileFaceNet,请阅读这两篇教程 MTCNN-Tensorflow 和 MobileFaceNet_TF ,这两个模型都是比较轻量的模型,所以就算这两个模型在CPU环境下也有比较好的预测速度,众所周知,笔者比较喜欢轻量级的模型,如何让我从准确率和预测速度上选择,我会更倾向于速度,因本人主要是研究深度学习在移动设备等嵌入式设备上的的部署。好了,下面就来介绍如何实现这两个模型实现三种人脸识别,使用路径进行人脸注册和人脸识别,使用摄像头实现人脸注册和人脸识别,通过HTTP实现人脸注册和人脸识别。
本教程源码:https://github.com/yeyupiaoling/Tensorflow-FaceRecognition
使用Anaconda创建虚拟环境:
conda create -n face_rg python = 3.10
激活刚刚配置好的环境
activate face_rg
从requirements.txt 下载需要的库
pip install -r requirements.txt
直接使用命令
python camera_infer.py
本地人脸图像识别就是要通过路径读取本地的图像进行人脸注册或者人脸识别,对应的代码为path_infer.py。首先要加载好人脸识别的两个模型,一个是人脸检测和关键点检测模型MTCNN和人脸识别模型MobileFaceNet,加载这两个模型已经封装在一个工具中了,方便加载。
然后add_faces()这个函数是从temp路径中读取手动添加的图片的人脸库中,具体来说,例如你有100张已经用人脸中对应人名字来命名图片文件名,但是你不能直接添加到人脸库face_db中,因为人脸库中是存放经过MTCNN模型处理过的图片,所以大规模添加人脸图片需要通过暂存在temp文件夹中的方式来然程序自动添加。最后是读取人脸库中图像,通过MobileFaceNet预测获取每张人脸的特征值存放在到一个列表中,等着之后的人脸对比识别。
# 检测人脸检测模型
mtcnn_detector = load_mtcnn()
# 加载人脸识别模型
face_sess, inputs_placeholder, embeddings = load_mobilefacenet()
# 添加人脸
add_faces(mtcnn_detector)
# 加载已经注册的人脸
faces_db = load_faces(face_sess, inputs_placeholder, embeddings)人脸注册是通过图像路径读取人脸图像,然后使用MTCNN检测图像中的人脸,并通过人脸关键点进行人脸对齐,最后裁剪并缩放成112*112的图片,并以注册名命名文件存储在人脸库中。
def face_register(img_path, name):
image = cv2.imdecode(np.fromfile(img_path, dtype=np.uint8), 1)
faces, landmarks = mtcnn_detector.detect(image)
if faces.shape[0] is not 0:
faces_sum = 0
bbox = []
points = []
for i, face in enumerate(faces):
if round(faces[i, 4], 6) > 0.95:
bbox = faces[i, 0:4]
points = landmarks[i, :].reshape((5, 2))
faces_sum += 1
if faces_sum == 1:
nimg = face_preprocess.preprocess(image, bbox, points, image_size='112,112')
cv2.imencode('.png', nimg)[1].tofile('face_db/%s.png' % name)
print("注册成功!")
else:
print('注册图片有错,图片中有且只有一个人脸')
else:
print('注册图片有错,图片中有且只有一个人脸')人脸识别是通过图像路径读取将要识别的人脸,通过经过MTCNN的检测人脸和对其,在使用MobileFaceNet预测人脸的特征,最终得到特征和人脸库中的特征值比较相似度,最终得到阈值超过0.6的最高相似度结果,对应的名称就是该人脸识别的结果。最后把结果在图像中画框和标记上名称并显示出来。
def face_recognition(img_path):
image = cv2.imdecode(np.fromfile(img_path, dtype=np.uint8), 1)
faces, landmarks = mtcnn_detector.detect(image)
if faces.shape[0] is not 0:
faces_sum = 0
for i, face in enumerate(faces):
if round(faces[i, 4], 6) > 0.95:
faces_sum += 1
if faces_sum > 0:
# 人脸信息
info_location = np.zeros(faces_sum)
info_location[0] = 1
info_name = []
probs = []
# 提取图像中的人脸
input_images = np.zeros((faces.shape[0], 112, 112, 3))
for i, face in enumerate(faces):
if round(faces[i, 4], 6) > 0.95:
bbox = faces[i, 0:4]
points = landmarks[i, :].reshape((5, 2))
nimg = face_preprocess.preprocess(image, bbox, points, image_size='112,112')
nimg = nimg - 127.5
nimg = nimg * 0.0078125
input_images[i, :] = nimg
# 进行人脸识别
feed_dict = {inputs_placeholder: input_images}
emb_arrays = face_sess.run(embeddings, feed_dict=feed_dict)
emb_arrays = sklearn.preprocessing.normalize(emb_arrays)
for i, embedding in enumerate(emb_arrays):
embedding = embedding.flatten()
temp_dict = {}
# 比较已经存在的人脸数据库
for com_face in faces_db:
ret, sim = feature_compare(embedding, com_face["feature"], 0.70)
temp_dict[com_face["name"]] = sim
dict = sorted(temp_dict.items(), key=lambda d: d[1], reverse=True)
if dict[0][1] > VERIFICATION_THRESHOLD:
name = dict[0][0]
probs.append(dict[0][1])
info_name.append(name)
else:
probs.append(dict[0][1])
info_name.append("unknown")
for k in range(faces_sum):
# 写上人脸信息
x1, y1, x2, y2 = faces[k][0], faces[k][1], faces[k][2], faces[k][3]
x1 = max(int(x1), 0)
y1 = max(int(y1), 0)
x2 = min(int(x2), image.shape[1])
y2 = min(int(y2), image.shape[0])
prob = '%.2f' % probs[k]
label = "{}, {}".format(info_name[k], prob)
cv2img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
pilimg = Image.fromarray(cv2img)
draw = ImageDraw.Draw(pilimg)
font = ImageFont.truetype('font/simfang.ttf', 18, encoding="utf-8")
draw.text((x1, y1 - 18), label, (255, 0, 0), font=font)
image = cv2.cvtColor(np.array(pilimg), cv2.COLOR_RGB2BGR)
cv2.rectangle(image, (x1, y1), (x2, y2), (255, 0, 0), 2)
cv2.imshow('image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()最后的动时选择是人脸注册还是人脸识别。
if __name__ == '__main__':
i = int(input("请选择功能,1为注册人脸,2为识别人脸:"))
image_path = input("请输入图片路径:")
if i == 1:
user_name = input("请输入注册名:")
face_register(image_path, user_name)
elif i == 2:
face_recognition(image_path)
else:
print("功能选择错误")日志输出如下:
loaded face: 张伟.png
loaded face: 迪丽热巴.png
请选择功能,1为注册人脸,2为识别人脸:1
请输入图片路径:test.png
请输入注册名:夜雨飘零
注册成功!
识别效果图:
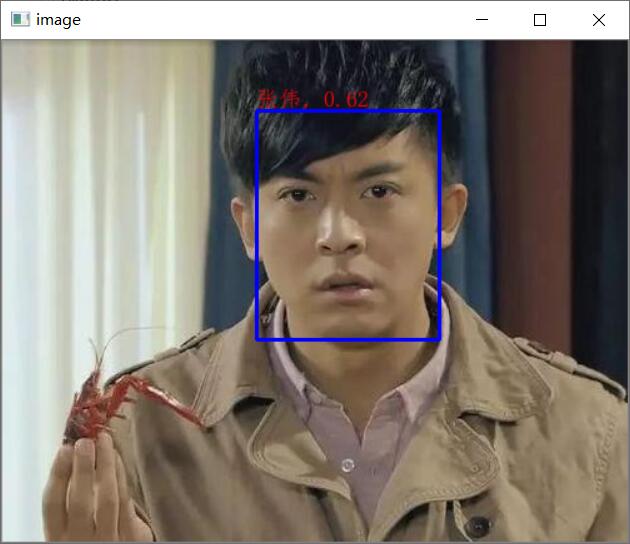
在camera_infer.py实现使用相机的人脸识别,通过调用相机获取图像,进行人脸注册和人脸识别,在使用人脸注册或者人脸识别之前,同样先加载人脸检测模型MTCNN和MobileFaceNet,并将临时temp文件夹中的人脸经过MTCNN处理添加到人脸库中,最后把人脸库中的人脸使用MobileFaceNet预测得到特征值,并报特征值和对应的人脸名称存放在列表中。
# 检测人脸检测模型
mtcnn_detector = load_mtcnn()
# 加载人脸识别模型
face_sess, inputs_placeholder, embeddings = load_mobilefacenet()
# 添加人脸
add_faces(mtcnn_detector)
# 加载已经注册的人脸
faces_db = load_faces(face_sess, inputs_placeholder, embeddings)通过使用摄像头实时获取图像,在人脸注册这里当摄像头拍摄到人脸之后,可以点击y键拍照,拍照获得到图片之后,需要经过MTCNN检测判断是否存在人脸,检测成功之后,会对人脸进行裁剪并以注册名直接存储在人脸库中face_db。
def face_register():
print("点击y确认拍照!")
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if ret:
cv2.imshow('image', frame)
if cv2.waitKey(1) & 0xFF == ord('y'):
faces, landmarks = mtcnn_detector.detect(frame)
if faces.shape[0] is not 0:
faces_sum = 0
bbox = []
points = []
for i, face in enumerate(faces):
if round(faces[i, 4], 6) > 0.95:
bbox = faces[i, 0:4]
points = landmarks[i, :].reshape((5, 2))
faces_sum += 1
if faces_sum == 1:
nimg = face_preprocess.preprocess(frame, bbox, points, image_size='112,112')
user_name = input("请输入注册名:")
cv2.imencode('.png', nimg)[1].tofile('face_db/%s.png' % user_name)
print("注册成功!")
else:
print('注册图片有错,图片中有且只有一个人脸')
else:
print('注册图片有错,图片中有且只有一个人脸')
break在人脸识别中,通过调用摄像头实时获取图像,通过使用MTCNN检测人脸的位置,并使用MobileFaceNet进行识别,最终在图像上画框并写上识别的名字,结果会跟着摄像头获取的图像实时识别的。
def face_recognition():
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if ret:
faces, landmarks = mtcnn_detector.detect(frame)
if faces.shape[0] is not 0:
faces_sum = 0
for i, face in enumerate(faces):
if round(faces[i, 4], 6) > 0.95:
faces_sum += 1
if faces_sum == 0:
continue
# 人脸信息
info_location = np.zeros(faces_sum)
info_location[0] = 1
info_name = []
probs = []
# 提取图像中的人脸
input_images = np.zeros((faces.shape[0], 112, 112, 3))
for i, face in enumerate(faces):
if round(faces[i, 4], 6) > 0.95:
bbox = faces[i, 0:4]
points = landmarks[i, :].reshape((5, 2))
nimg = face_preprocess.preprocess(frame, bbox, points, image_size='112,112')
nimg = nimg - 127.5
nimg = nimg * 0.0078125
input_images[i, :] = nimg
# 进行人脸识别
feed_dict = {inputs_placeholder: input_images}
emb_arrays = face_sess.run(embeddings, feed_dict=feed_dict)
emb_arrays = sklearn.preprocessing.normalize(emb_arrays)
for i, embedding in enumerate(emb_arrays):
embedding = embedding.flatten()
temp_dict = {}
# 比较已经存在的人脸数据库
for com_face in faces_db:
ret, sim = feature_compare(embedding, com_face["feature"], 0.70)
temp_dict[com_face["name"]] = sim
dict = sorted(temp_dict.items(), key=lambda d: d[1], reverse=True)
if dict[0][1] > VERIFICATION_THRESHOLD:
name = dict[0][0]
probs.append(dict[0][1])
info_name.append(name)
else:
probs.append(dict[0][1])
info_name.append("unknown")
for k in range(faces_sum):
# 写上人脸信息
x1, y1, x2, y2 = faces[k][0], faces[k][1], faces[k][2], faces[k][3]
x1 = max(int(x1), 0)
y1 = max(int(y1), 0)
x2 = min(int(x2), frame.shape[1])
y2 = min(int(y2), frame.shape[0])
prob = '%.2f' % probs[k]
label = "{}, {}".format(info_name[k], prob)
cv2img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
pilimg = Image.fromarray(cv2img)
draw = ImageDraw.Draw(pilimg)
font = ImageFont.truetype('font/simfang.ttf', 18, encoding="utf-8")
draw.text((x1, y1 - 18), label, (255, 0, 0), font=font)
frame = cv2.cvtColor(np.array(pilimg), cv2.COLOR_RGB2BGR)
cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 0), 2)
cv2.imshow('image', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break在启动程序中,通过选择功能,选择注册人脸或者是识别人脸。
if __name__ == '__main__':
i = int(input("请选择功能,1为注册人脸,2为识别人脸:"))
if i == 1:
face_register()
elif i == 2:
face_recognition()
else:
print("功能选择错误")日志输出如下:
loaded face: 张伟.png
loaded face: 迪丽热巴.png
请选择功能,1为注册人脸,2为识别人脸:1
点击y确认拍照!
请输入注册名:夜雨飘零
注册成功!
识别效果图:
程序在server_main.py中实现,通过使用Flask提供网络服务接口,如果要允许跨域访问需要设置CORS(app),本程序虽然是默认开启跨域访问,但是为了可以在浏览器上调用摄像头,启动的host设置为localhost。另外还要加载MTCNN模型和MobileFaceNet模型,并报人脸库的图像加载到程序中。
app = Flask(__name__)
# 允许跨越访问
CORS(app)
# 人脸识别阈值
VERIFICATION_THRESHOLD = config.VERIFICATION_THRESHOLD
# 检测人脸检测模型
mtcnn_detector = load_mtcnn()
# 加载人脸识别模型
face_sess, inputs_placeholder, embeddings = load_mobilefacenet()
# 加载已经注册的人脸
faces_db = load_faces(face_sess, inputs_placeholder, embeddings)提供一个/register的人脸注册接口,通过表单上传的图像和注册名,经过MTCNN检测,是否包含人脸,如果注册成功,将会把图像裁剪并储存在人脸库中face_db。并更新已经加载的人脸库,注意这是全部重新读取更新。
@app.route("/register", methods=['POST'])
def register():
global faces_db
upload_file = request.files['image']
user_name = request.values.get("name")
if upload_file:
try:
image = cv2.imdecode(np.frombuffer(upload_file.read(), np.uint8), cv2.IMREAD_UNCHANGED)
faces, landmarks = mtcnn_detector.detect(image)
if faces.shape[0] is not 0:
faces_sum = 0
bbox = []
points = []
for i, face in enumerate(faces):
if round(faces[i, 4], 6) > 0.95:
bbox = faces[i, 0:4]
points = landmarks[i, :].reshape((5, 2))
faces_sum += 1
if faces_sum == 1:
nimg = face_preprocess.preprocess(image, bbox, points, image_size='112,112')
cv2.imencode('.png', nimg)[1].tofile('face_db/%s.png' % user_name)
# 更新人脸库
faces_db = load_faces(face_sess, inputs_placeholder, embeddings)
return str({"code": 0, "msg": "success"})
return str({"code": 3, "msg": "image not or much face"})
except:
return str({"code": 2, "msg": "this file is not image or not face"})
else:
return str({"code": 1, "msg": "file is None"})提供/recognition人脸识别接口,通过上传图片进行人脸识别,把识别的结果返回给用户,返回的结果不仅包括的识别的名字,还包括人脸框和关键点。因为也提供了一个is_chrome_camera参数,这个是方便在浏览器上调用摄像头获取图像进行预测,因为如果直接把浏览器拍摄到的图像直接预测会出现错误,所以如果是浏览器拍照识别,需要先存储起来,然后重新读取。
@app.route("/recognition", methods=['POST'])
def recognition():
start_time1 = time.time()
upload_file = request.files['image']
is_chrome_camera = request.values.get("is_chrome_camera")
if upload_file:
try:
img = cv2.imdecode(np.frombuffer(upload_file.read(), np.uint8), cv2.IMREAD_UNCHANGED)
# 兼容浏览器摄像头拍照识别
if is_chrome_camera == "True":
cv2.imwrite('test.png', img)
img = cv2.imdecode(np.fromfile('test.png', dtype=np.uint8), 1)
except:
return str({"error": 2, "msg": "this file is not image"})
try:
info_name, probs, info_bbox, info_landmarks = recognition_face(img)
if info_name is None:
return str({"error": 3, "msg": "image not have face"})
except:
return str({"error": 3, "msg": "image not have face"})
# 封装识别结果
data_faces = []
for i in range(len(info_name)):
data_faces.append(
{"name": info_name[i], "probability": probs[i],
"bbox": list_to_json(np.around(info_bbox[i], decimals=2).tolist()),
"landmarks": list_to_json(np.around(info_landmarks[i], decimals=2).tolist())})
data = str({"code": 0, "msg": "success", "data": data_faces}).replace("'", '"')
print('duration:[%.0fms]' % ((time.time() - start_time1) * 1000), data)
return data
else:
return str({"error": 1, "msg": "file is None"})在templates目录下创建index.html文件,主要是以下两个表单和一个拍摄实时显示的video,拍照的图像在canvas 显示,最后上传。
<form action="/register" enctype="multipart/form-data" method="post">
注册人脸:<input type="file" required accept="image/*" name="image"><br>
注册名称:<input type="text" name="name"><br>
<input type="submit" value="上传">
</form>
<br/><br/><br/>
<form action="/recognition" enctype="multipart/form-data" method="post">
预测人脸:<input type="file" required accept="image/*" name="image"><br>
<input type="submit" value="上传">
</form>
<br/><br/><br/>
<video id="video" width="640" height="480" autoplay></video>
<button id="snap">拍照</button>
<br/><br/>
<canvas id="canvas" width="640" height="480"></canvas>
<button id="upload">上传</button>通过下面启动整个服务。
@app.route('/')
def home():
return render_template("index.html")
if __name__ == '__main__':
app.run(host=config.HOST, port=config.POST)日志输出如下:
loaded face: 张伟.png
loaded face: 迪丽热巴.png
* Serving Flask app "server_main" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://localhost:5000/ (Press CTRL+C to quit)
页面图:

识别返回结果:
