改进方案:
- 自动写入房源经纬度数据到地图可视化代码中,
- 修改地图可视化中代码中的范围参数为置信度参数
- 代码文件优化,写入方法优化
文件说明:
- add.txt:房源经纬度数据
- fake_useragent,json:随机ua列表
- readme.md:说明文件
- thermalMap.html:热力图网页
- toTxt.py:将MongDB的房源地址数据转换成经纬度,并存入add.txt中
- 可视化.py:将MongDB的房源数据进行数据分析,并可视化为武汉各类型房源占比饼状图、武汉地区房价水平柱形图
- png:结果图片文件
- 爬取数据.py:爬取武汉链家房源数据,共729个房源数据
自行准备好运行环境,如下:
- 启动MongDB服务以及Redis服务
- 安装依赖
- 运行 proxy_pool 开源库:jhao104/proxy_pool: Python爬虫代理IP池(proxy pool) (github.com) 获取随机ip
运行顺序:
- 爬取数据(爬取数据.py):共729个武汉房源数据
- 可视化(可视化.py):武汉各类型房源占比饼状图、武汉地区房价水平柱形图
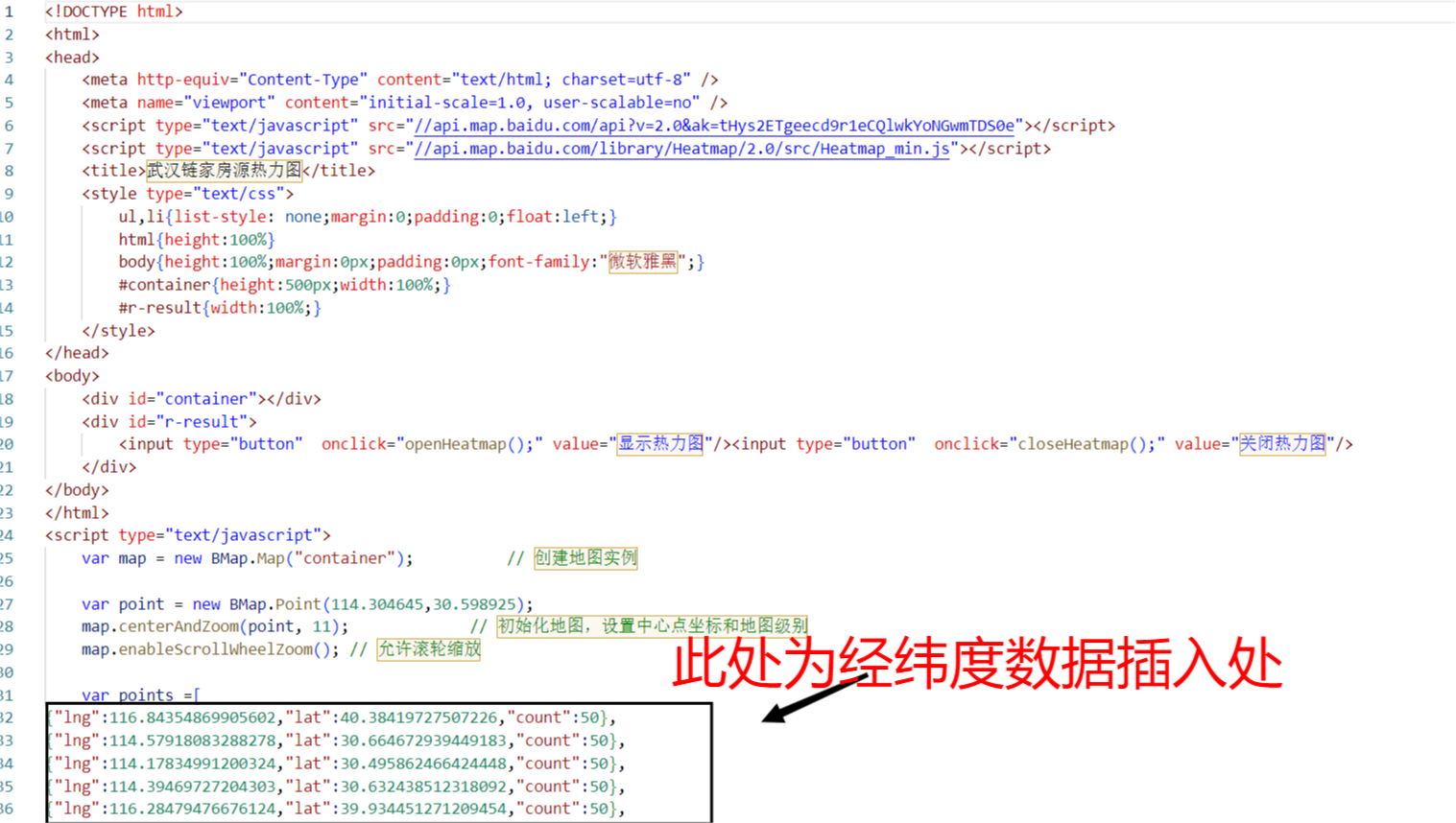
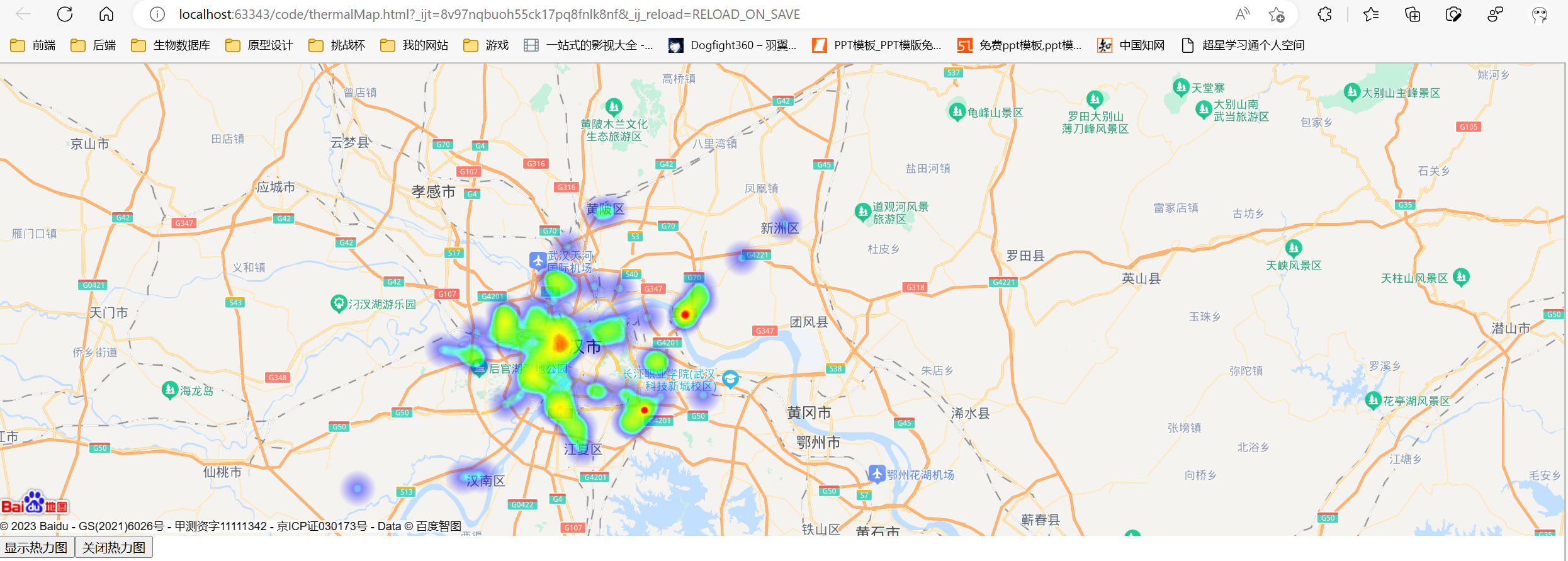
- 热力图(toTxt.py):往add.txt写入所有房源经纬度,自行写入到thermalMap.html要求位置,运行该html即可获得热力图


随着时代的发展,人们的生活水平越来越高,但与之对应房价也在逐渐上涨,为了追求高质量的生活,有的人选择了租房的形式来避开高额的房贷压力。面对网上形形色色的租房信息和无法得知其中是否有黑心中介,许多人都在为无法找到一个很好的房源而烦恼。
链家网站就提供了这样一个平台,它是集房源信息搜索、产品研发、大数据处理、服务标准建立为一体的国内领先且重度垂直的全产业链房产服务平台。链家网线上房源已覆盖北京、上海、广州、深圳、天津、成都、青岛、重庆、大连等42个城市,旨在通过不断提高服务效率、提升服务体验,为用户提供更安全、更便捷、更舒心的综合房产服务。
本项目利用爬虫技术架爬取链家网站的房源信息,解析并存储到MongoDB中,再对这些数据进行处理并可视化。
爬虫的本质为模拟浏览器打开网页,获取浏览器的数据(爬虫者想要的数据);浏览器打开网页的过程:当你在通过浏览器访问一个链接后,经过DNS服务器找到服务器IP,向服务器发送一个request;服务器经过解析后,给出一个response解析渲染后,显示网页内容;四步基础流程:1.请求目标链接;2.获取响应内容;3.解析内容;4.存储数据;下面分别进行简单描述:
1.请求目标链接
发起一个带有header、请求参数等信息的Request,等待服务器响应;
2.获取响应内容
服务器正常响应后,Response的内容即包含所有页面内容(可以是HTML、JSON字符串、二进制数据(图片、视频)等等)
3.解析内容
得到的内容可能是HTML,可以用正则表达式,页面解析库进行解析;可能是Json字符串,可以直接转换为Json对象解析,可能是二进制数据,可以做保存或者进一步的处理……
4.存储数据
存储形式多样,可以存为文本,也可以存储到数据库,或者存为特定格式的文件;
通过上述可以基本了解爬虫的流程,本项目的实现步骤大致如下:
- 对爬取的网页标签进行分析
- 使用python进行网页爬取
- 将爬取的数据存储进MongoDB
- 对爬取的数据进行聚合管道处理并可视化
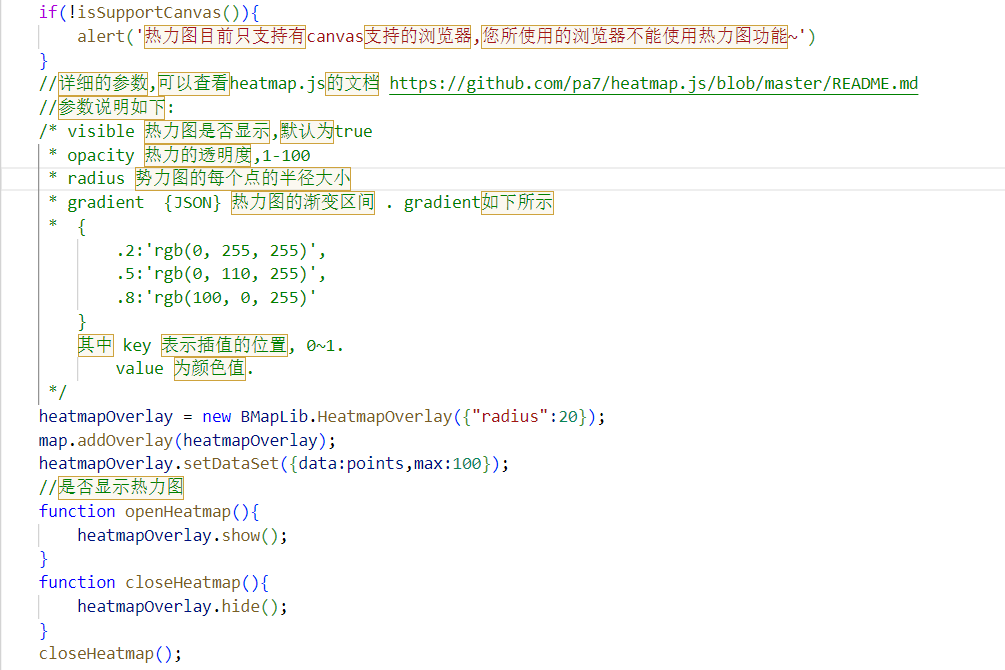
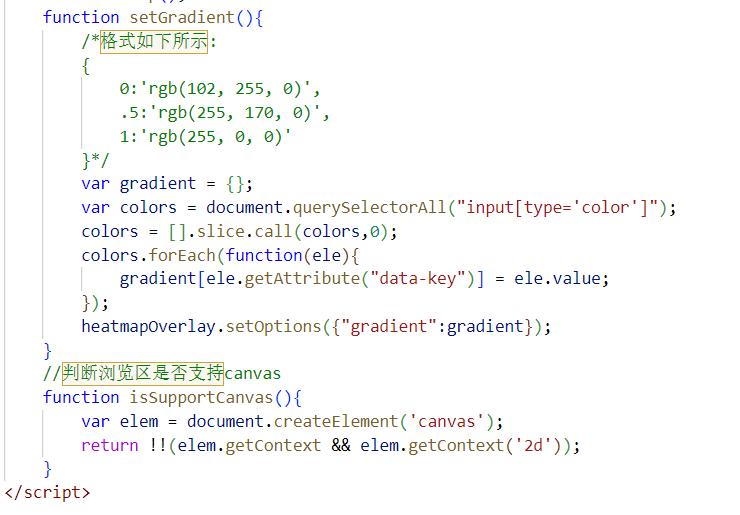
- 利用百度地图api生成武汉房源的热力图
本项目将使用到Python,pymongodb等编程技术,利用requests爬虫,re正则,proxy_pool(代理ip池)和fake useragent(虚假请求头)防反爬对网页进行爬取,再通过聚合管道方法和百度地图api对数据进行处理并可视化。
PC、MongoDB、Python3、redis
Pycharm、MongoDB Compass
Redis:Redis(Remote Directory Server,远程字典服务器),是一个用C语言编写的、开源的、基于内存运行并支持持久化的(redis中的数据大部分时间都是存储在内存中的,访问效率高,适合存储简单、少量、经常访问的数据)、高性能的NoSQL数据库,也是当前热门的NoSQL数据库之一。Redis又被当成“缓存数据库”,但会定期持久化。本项目在ip代理池中使用到redis存储数据。
MongoDB Compass:在使用MongoDB过程中,如果单单依靠命令行操作MongoDB数据库,效率不高而且查看不方便。因此MongoDB官网提供的一个可视化管理工具,叫MongoDB Compass,它集创建数据库、管理集合和文档、运行临时查询、评估和优化查询、性能图表、构建地理查询等功能为一体,很方便。
requests 库是用Python语言编写,用于访问网络资源的第三方库,它基于urllib,虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更简洁方便。requests库可以帮助实现自动爬取HTML网页页面以及模拟人类访问服务器自动提交网络请求。
Requests 继承了urllib2的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。
Requests的文档非常完备,中文文档也相当不错。Requests能完全满足当前网络的需求,支持Python 2.6—3.5,而且能在PyPy下完美运行。
做爬虫的时候,经常会遇到对于一个网页,使用同一个IP多次会被禁掉IP的问题,我们可以自己手动更换代理IP再继续这个问题但多少会有点麻烦,对于一个懒人来说,手动更换IP太麻烦,而且也不符合程序员懒惰的美德,于是便有了下面的故事。
proxy_pool 是一个开源的代理池,聚合了各大免费的 ip 代理池。当自己的爬虫因为爬的太快了 ip 被封了的时候,代理池就可以派上用场啦
爬虫代理IP池项目,主要功能为定时采集网上发布的免费代理验证入库,定时验证入库的代理保证代理的可用性,提供API和CLI两种使用方式。同时你也可以扩展代理源以增加代理池IP的质量和数量。
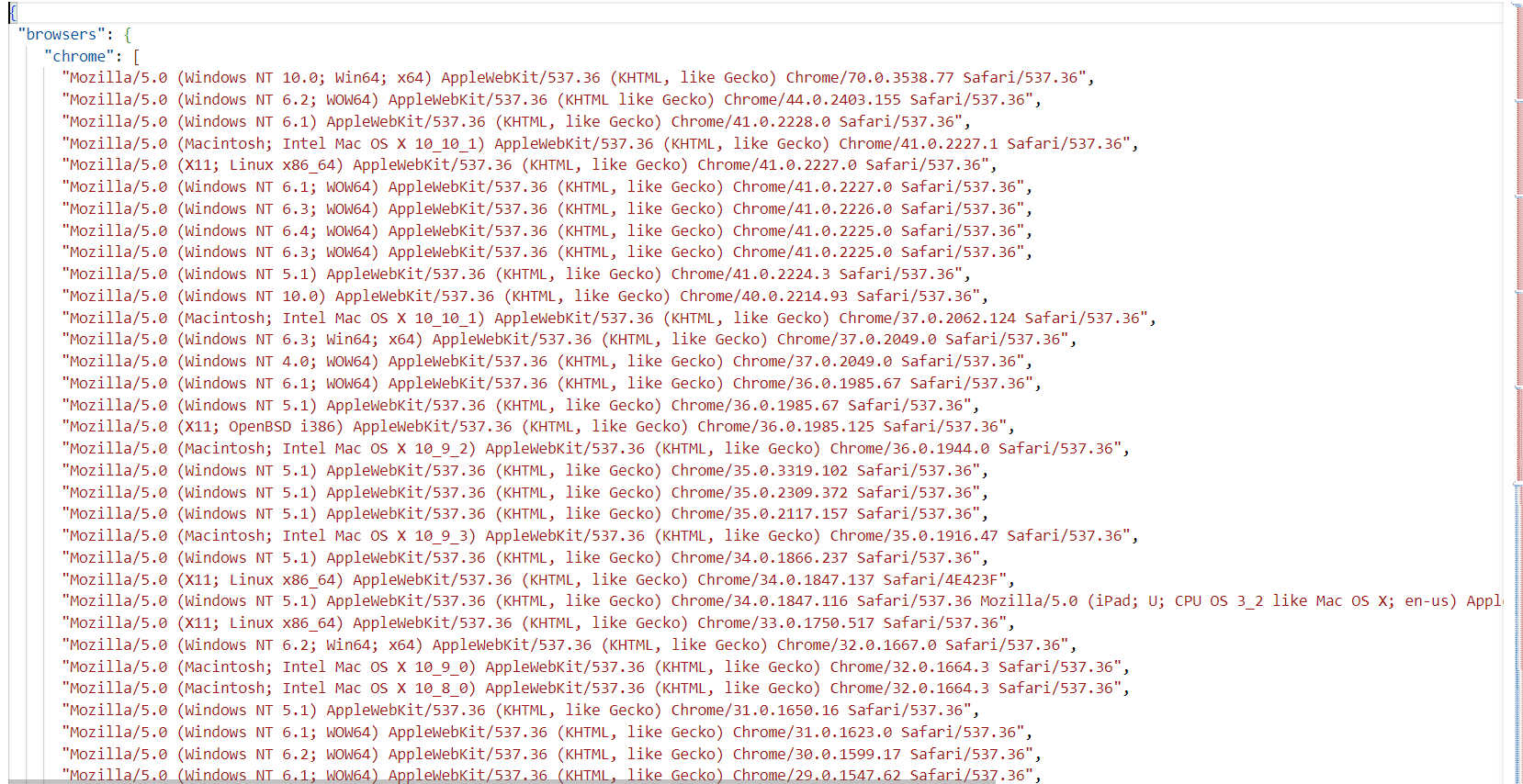
User Agent 中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
在爬虫中进行request请求,很多时候,都需要添加请求头,不然服务器会认为是非法的请求,从而拒绝你的访问。在添加请求头中最常用的就是添加user-agent来讲本次请求伪装成浏览器。
而fake-useragent库中就多种浏览器的请求头,当我们需要爬虫的时候,仅仅只需要调用一下这个库就可以使用了。
本次项目所使用的请求头库如图所示:
MongoDB是一个文档数据库(以 JSON 为数据模型),由C++语言编写,旨在为WEB应用提供可扩展的高性能数据存储解决方案。文档来自于“JSON Document”,并非我们一般理解的 PDF,WORD 文档。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,数据格式是BSON,一种类似JSON的二进制形式的存储格式,简称Binary JSON ,和JSON一样支持内嵌的文档对象和数组对象,因此可以存储比较复杂的数据类型。MongoDB最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。原则上 Oracle 和MySQL 能做的事情,MongoDB 都能做(包括 ACID 事务)。
主要特点:
1.MongoDB的提供了一个面向文档存储,操作起来比较简单和容易。
2.你可以在MongoDB记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Gandhi Road")来实现更快的排序。
3.你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
4.如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
5.Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
6.MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
7.Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
8.Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
9.Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
10.GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
11.MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
12.MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
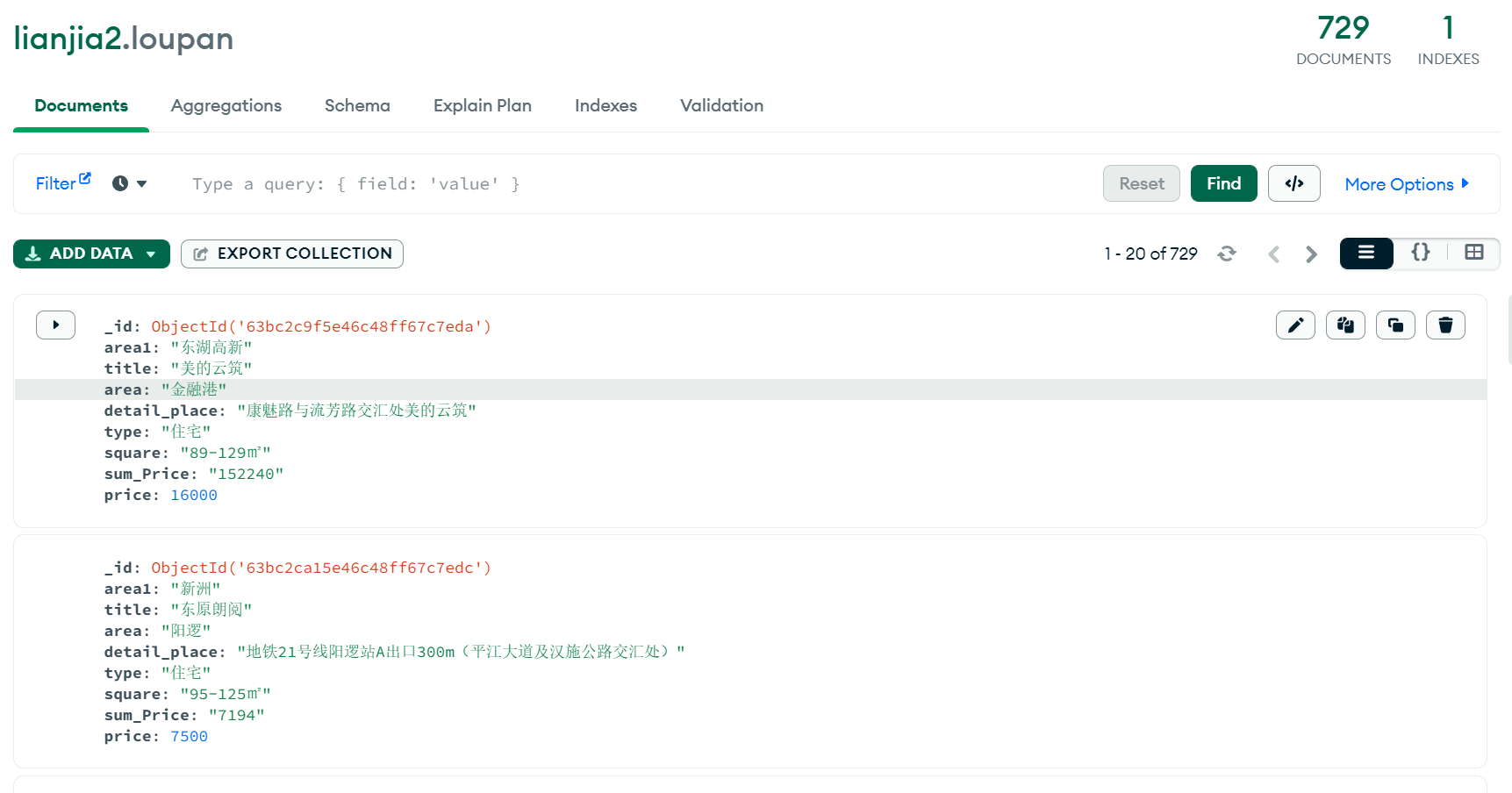
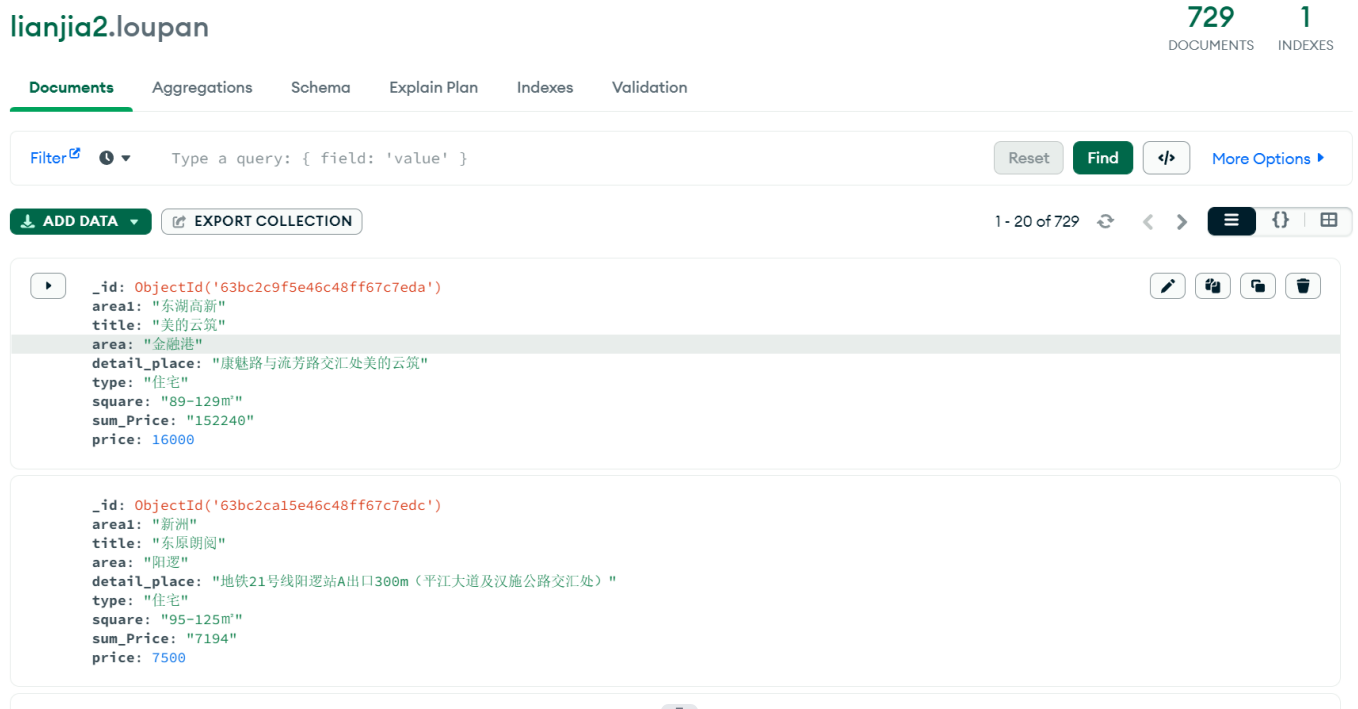
该网站显示有729个房源
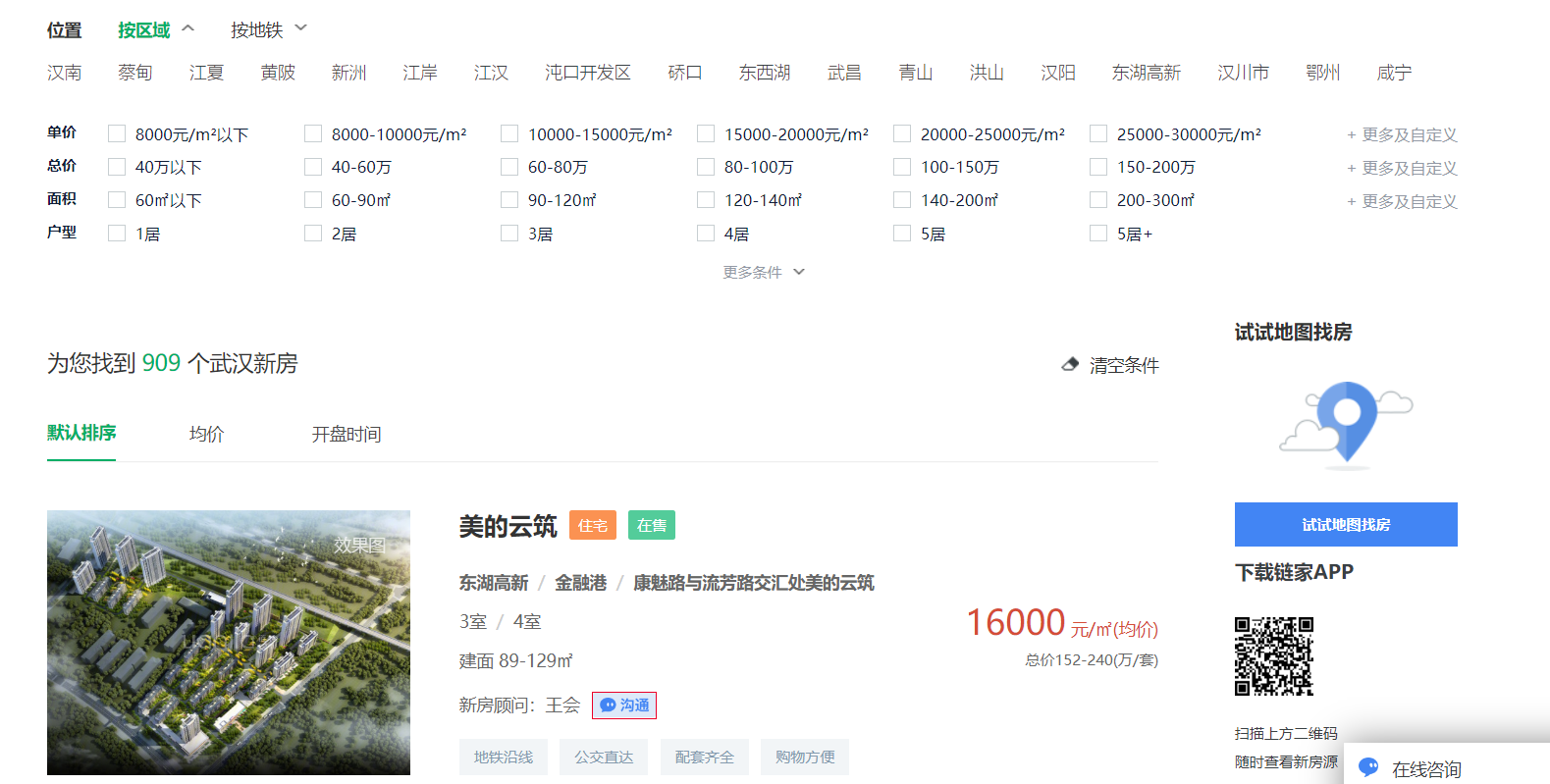
实则在第47页已查询不到新房
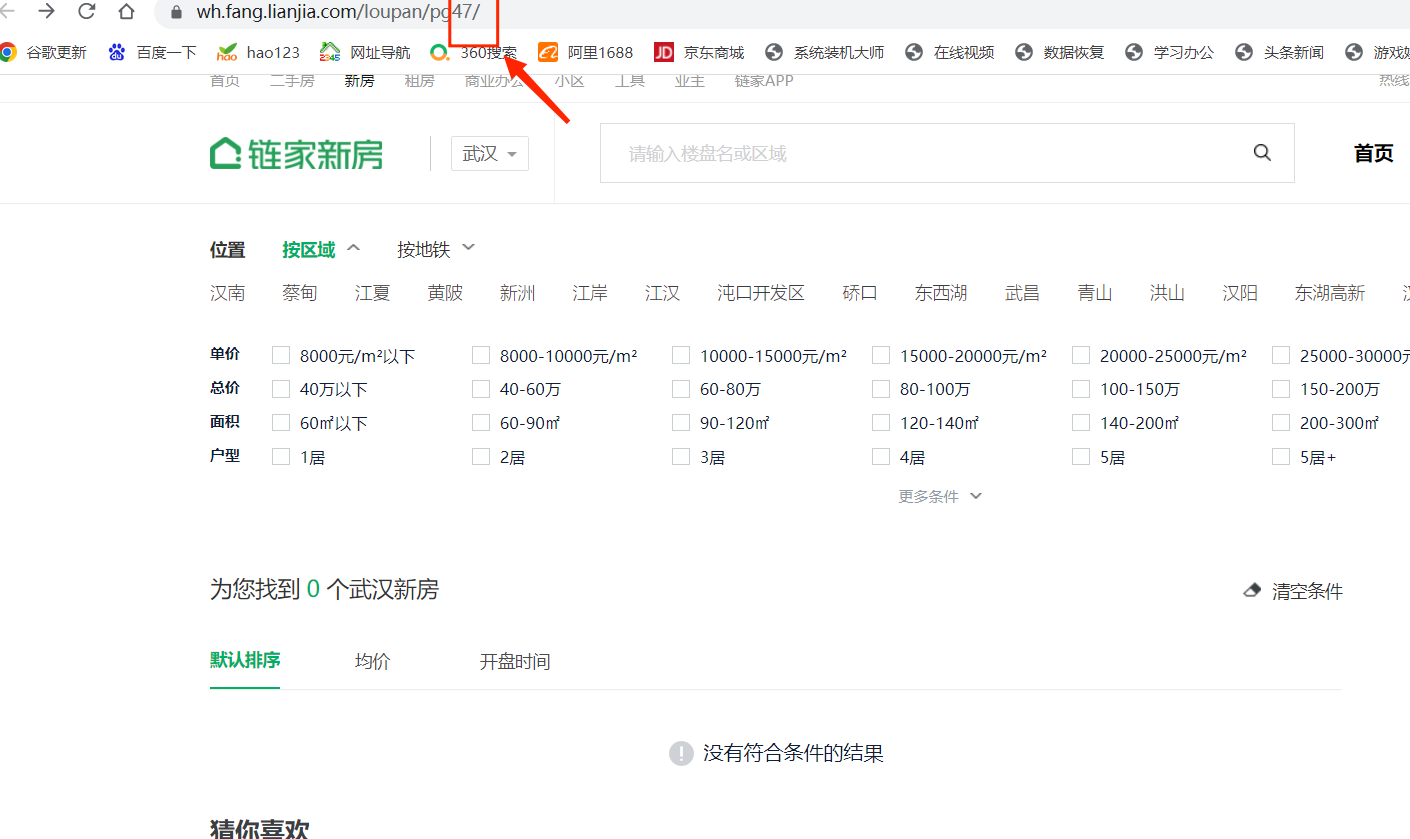
故在爬取过程中,只爬取47页

本次爬取网站为武汉的链家网站,我们可以利用浏览器的开发者工具来帮助我们快速找到要爬取的信息所在标签,只需按f12,点击箭头所指的按钮,选择想要获取的信息,浏览器就能快速找到信息所在标签
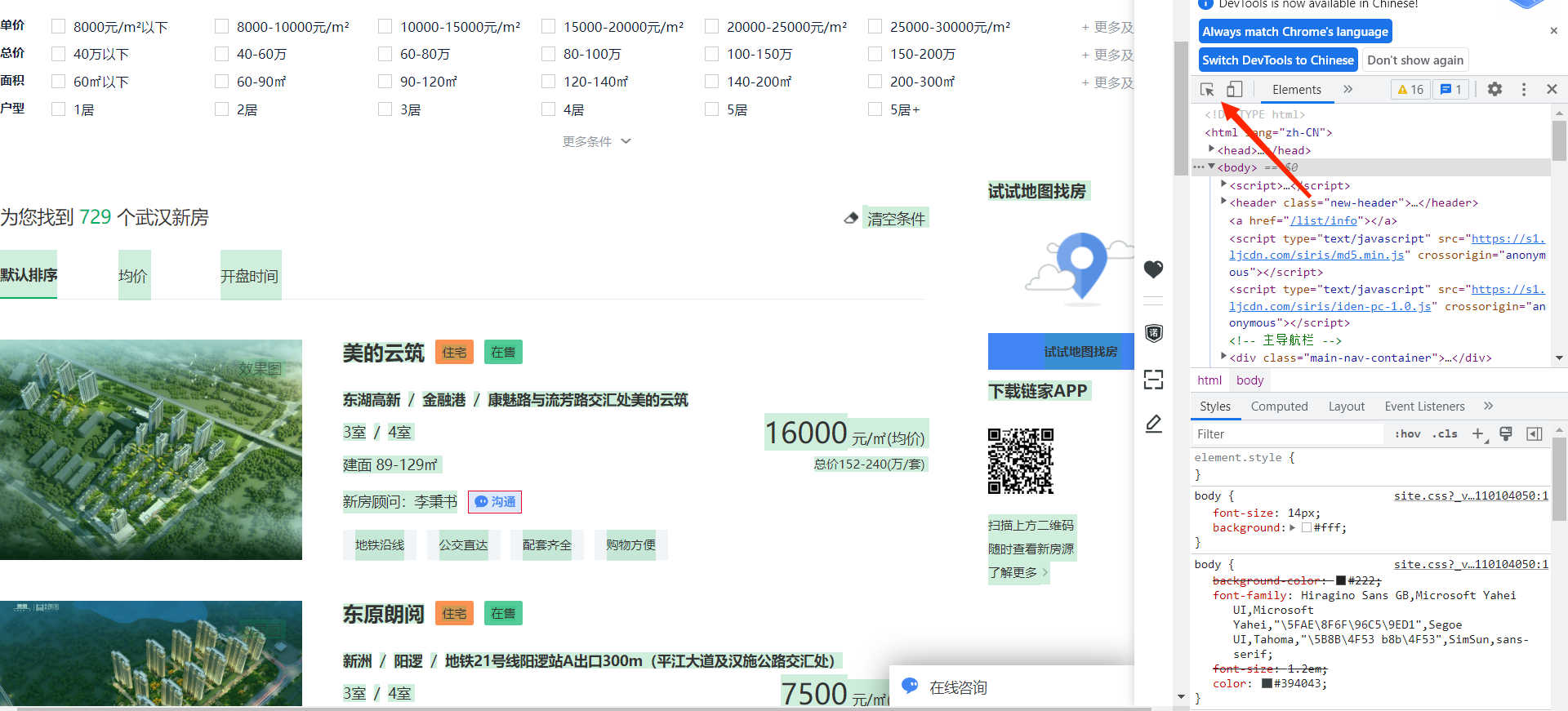
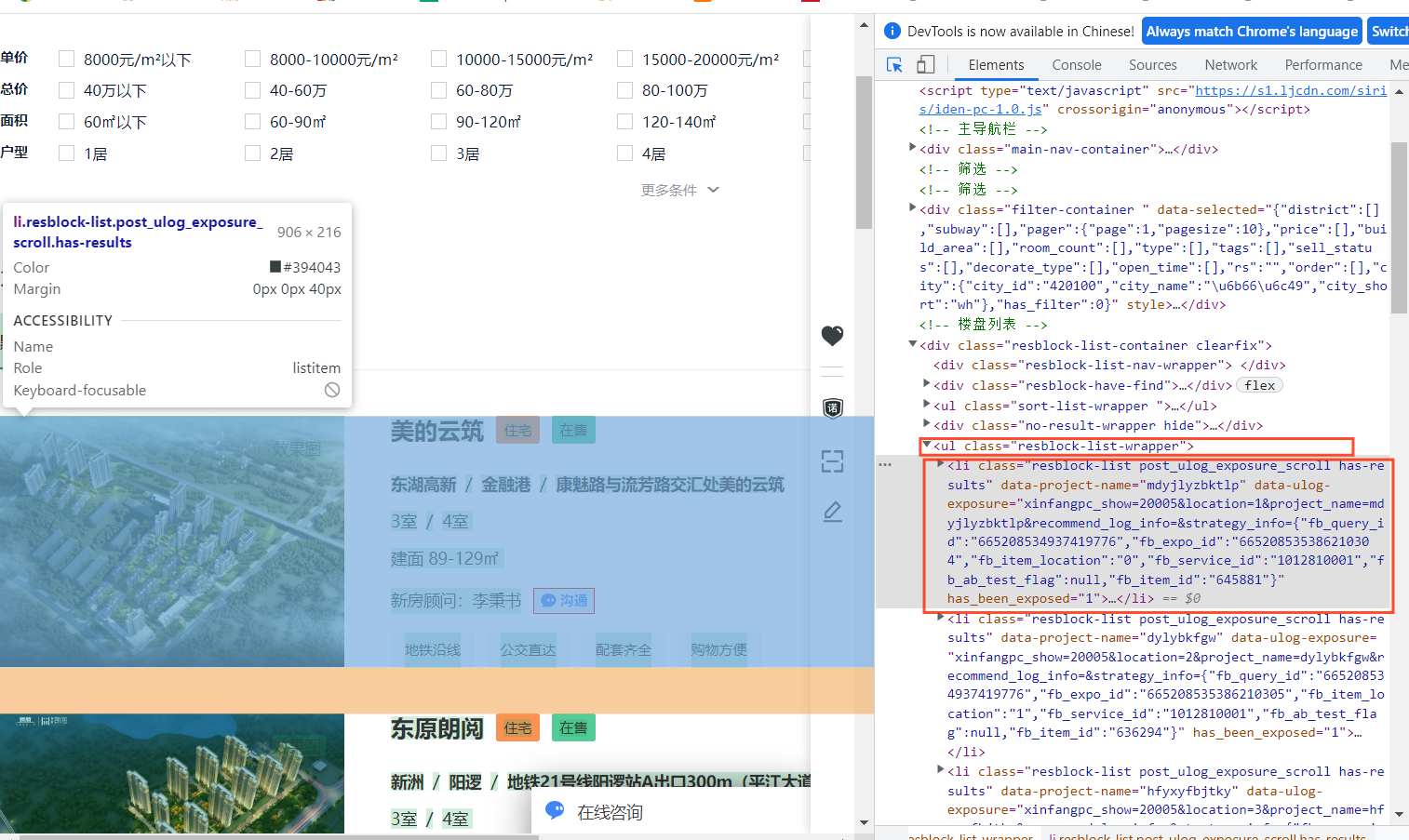
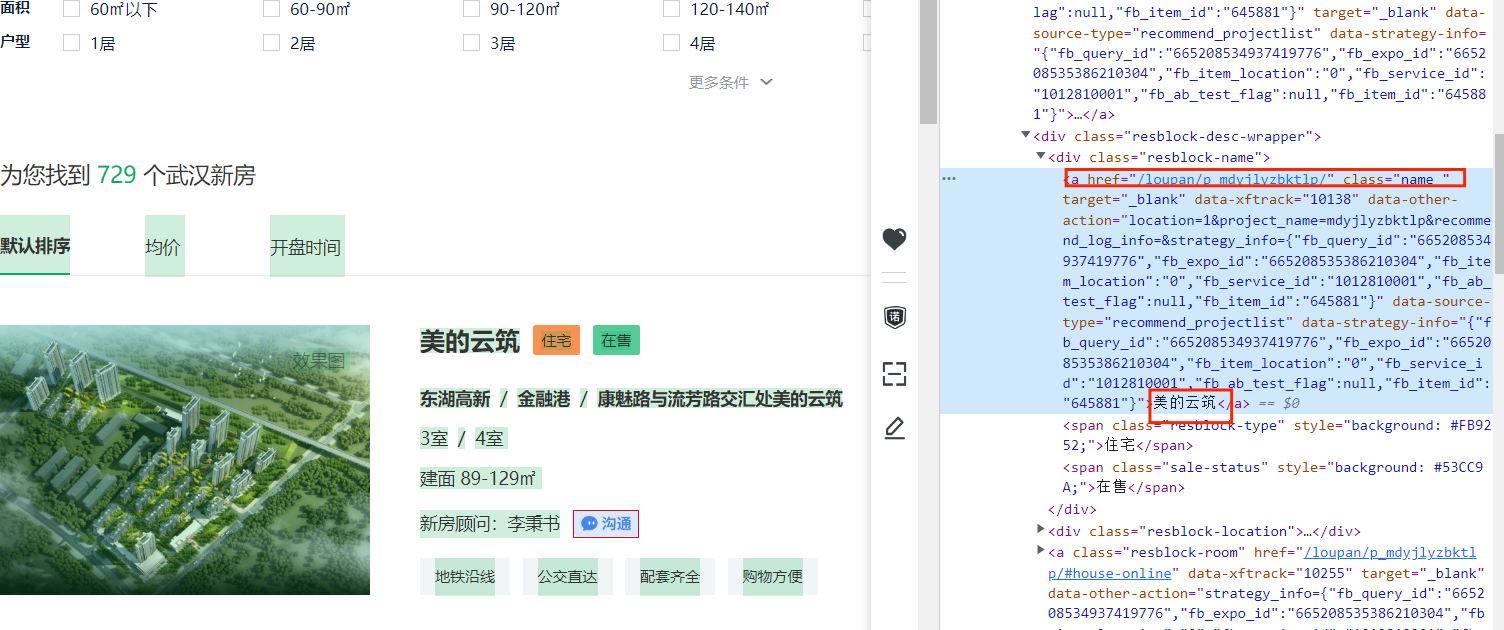
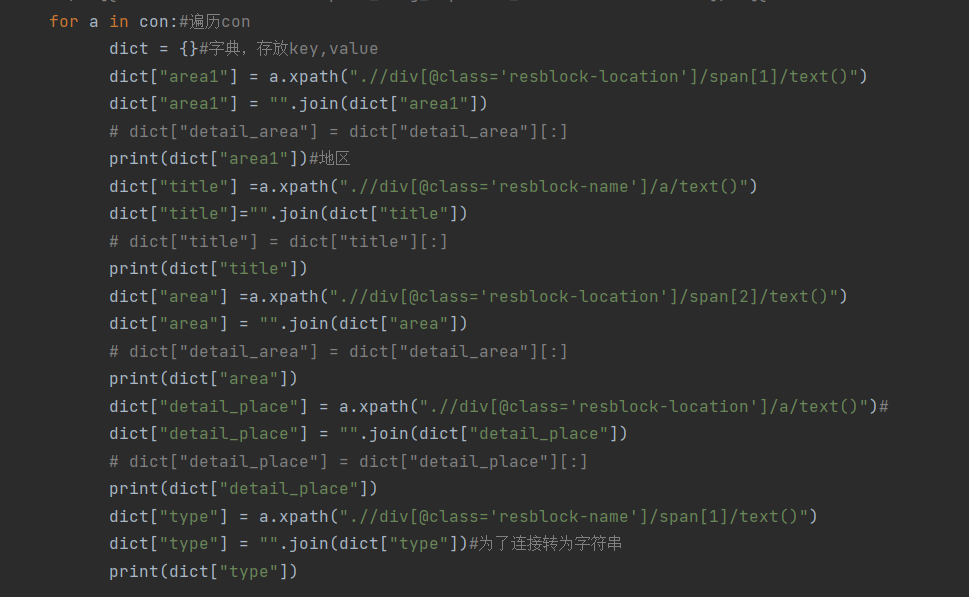
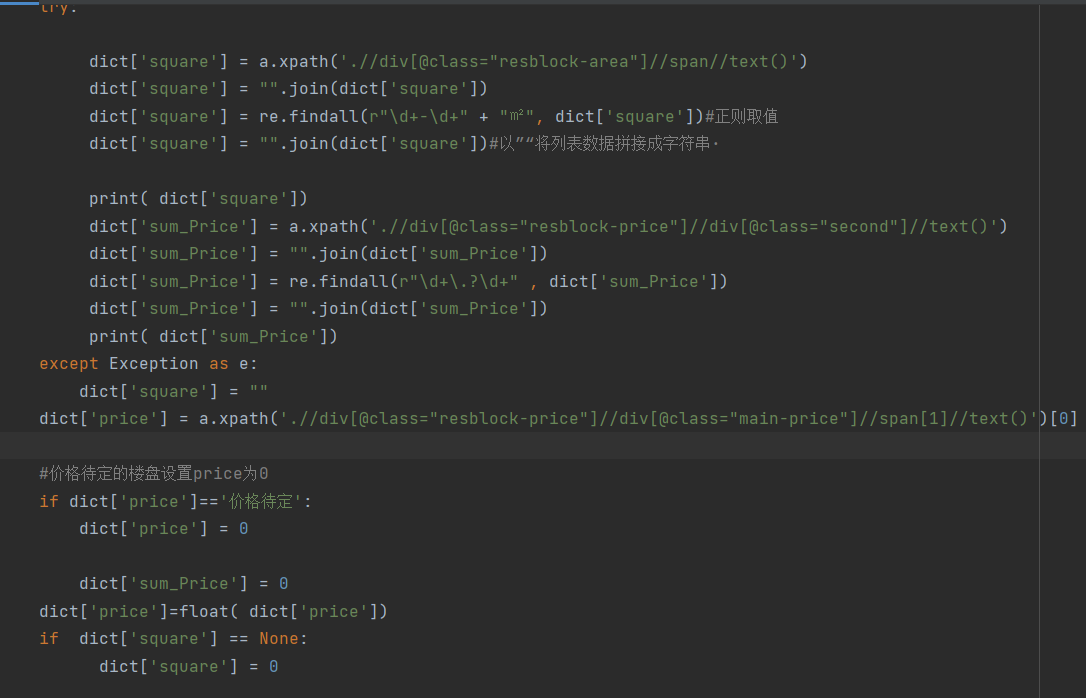
我们需要的数据有地区名,房子平米数,房源价格等信息,通过网页检查可以看到相关的网页标签,从检查中,我们可以知道,所有的房源数据都在一个ul标签里面,属性是“class=resblock-list-wrapper”,那么接着往下可以找到想要获取的楼盘区域,需要获取ul下li里面的a标签内容,如下:

同理,我们可以找到其他所需要的房源信息所在的标签,这样就可以通过相关代码爬取所需要的信息了。
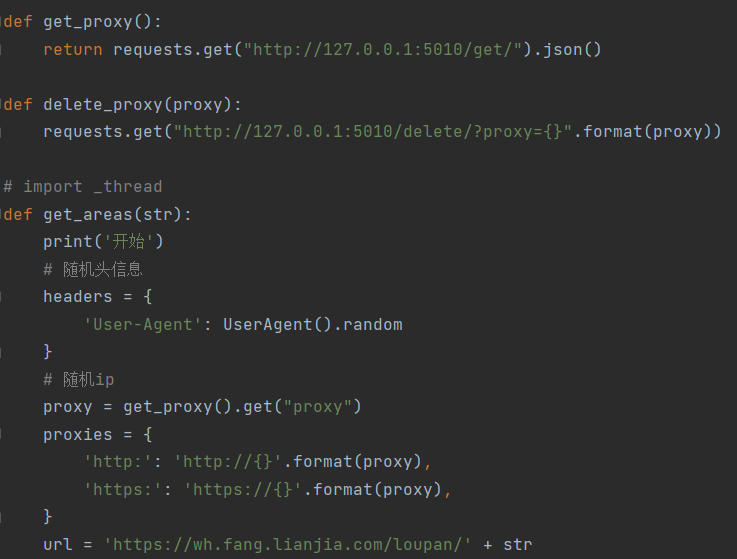
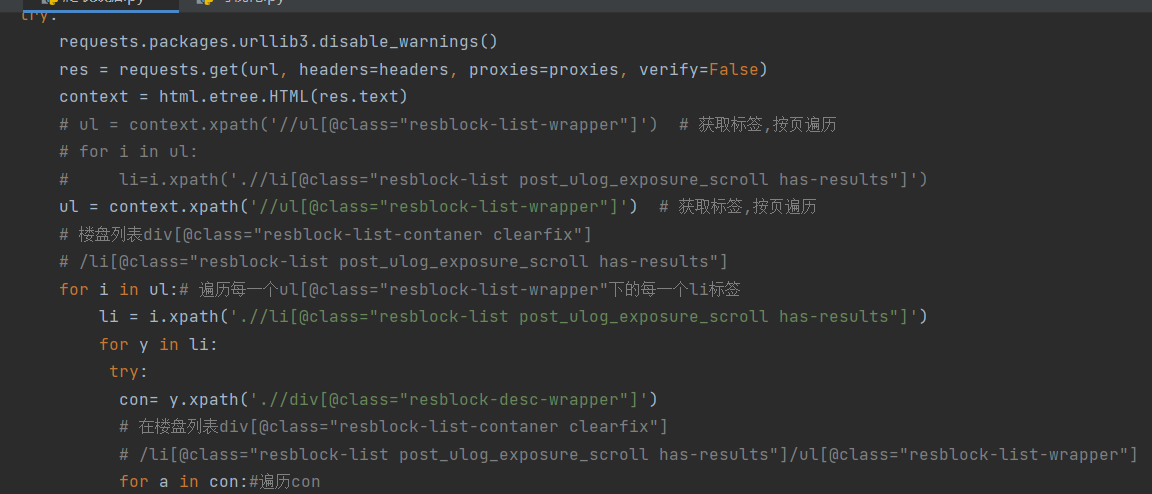
- 导库
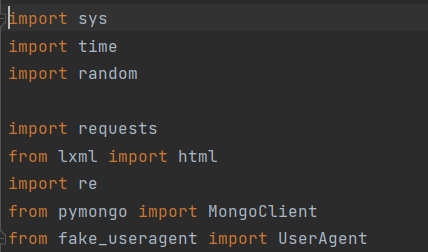
- 设置随机请求头和ip遍历网页数据,利用xpath技术和正则表达爬取所需要的数据
- 其中利用到一点防反爬,每个分页睡眠30-35秒,每次页内遍历一次睡眠0-5秒
- 将爬取的数据存储在mongodb中

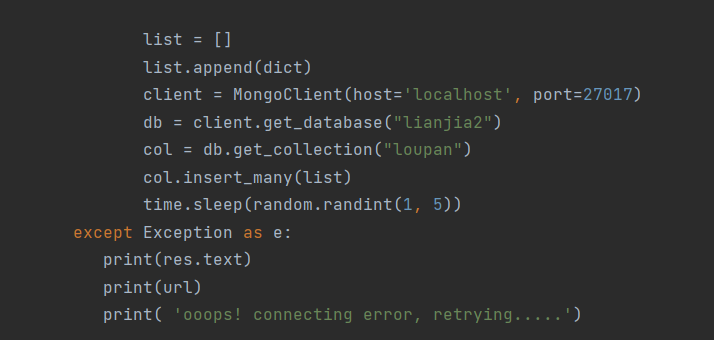
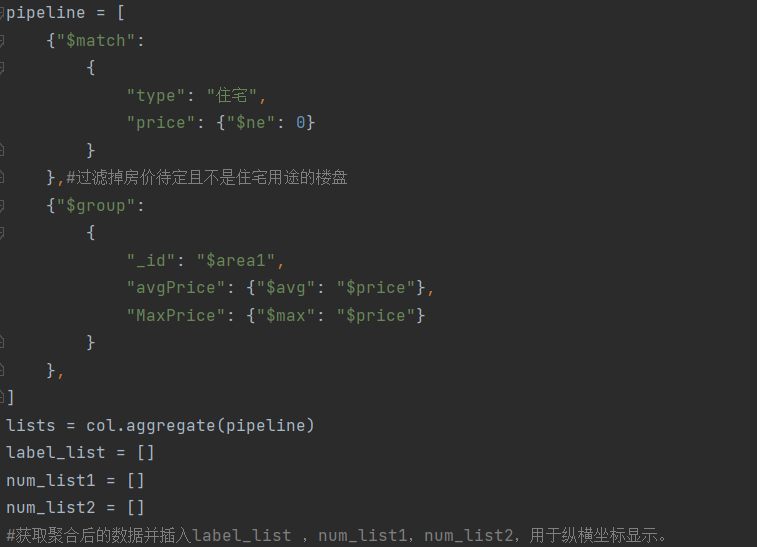
代码如下
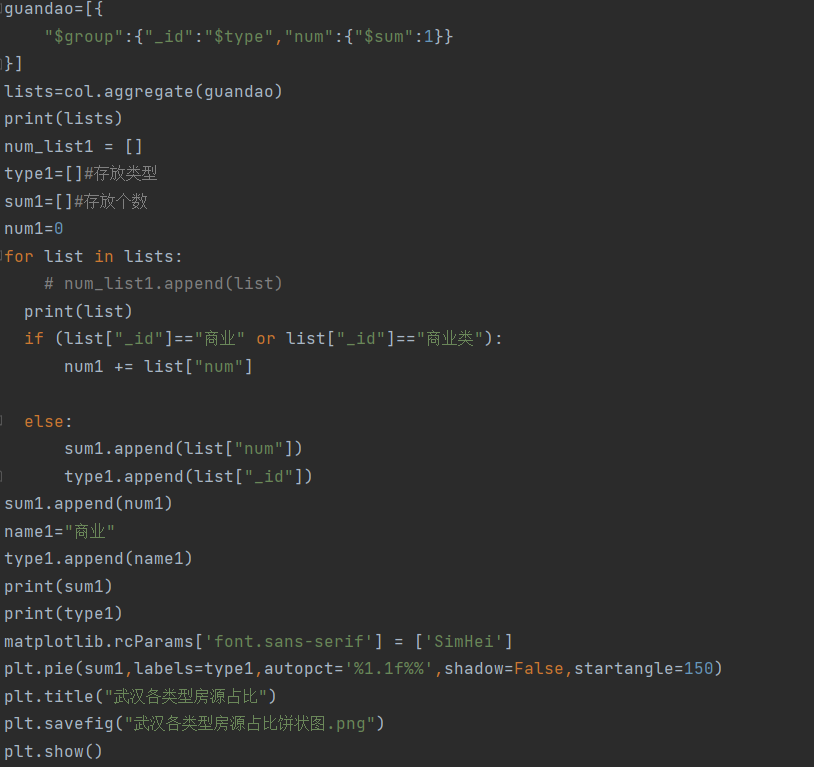
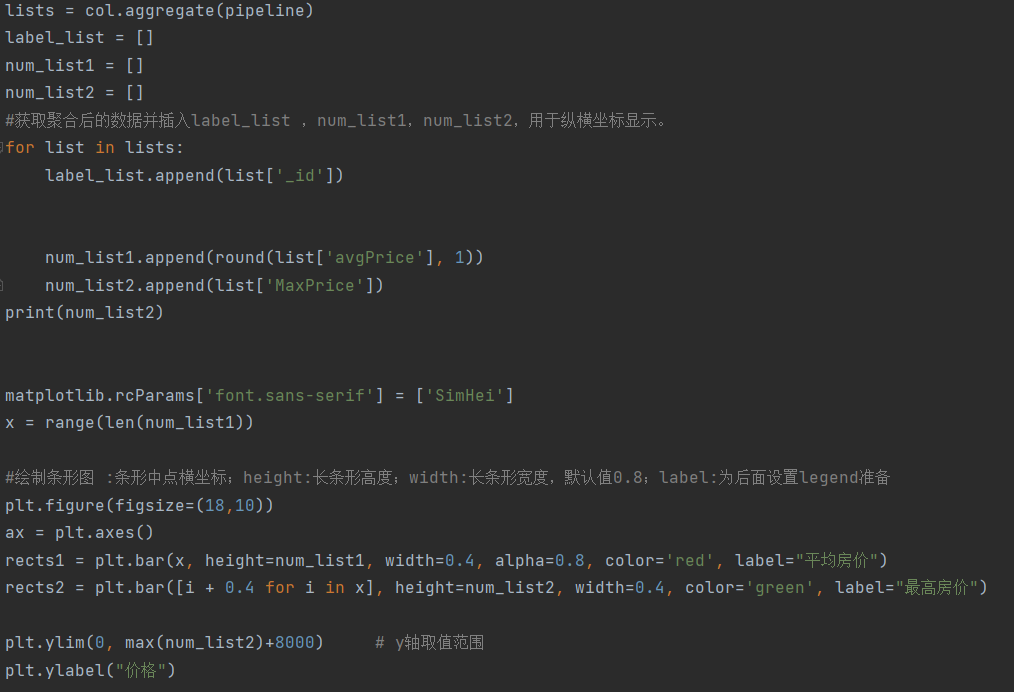
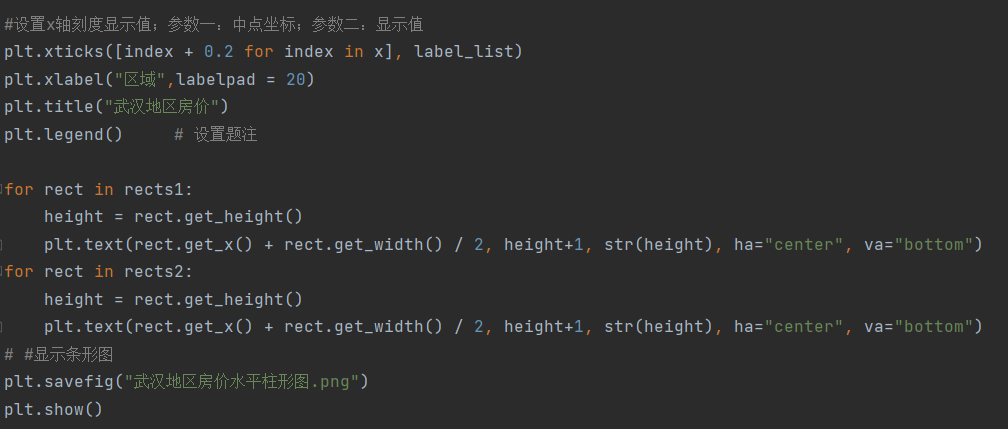
武汉各类型房源占比饼状图:

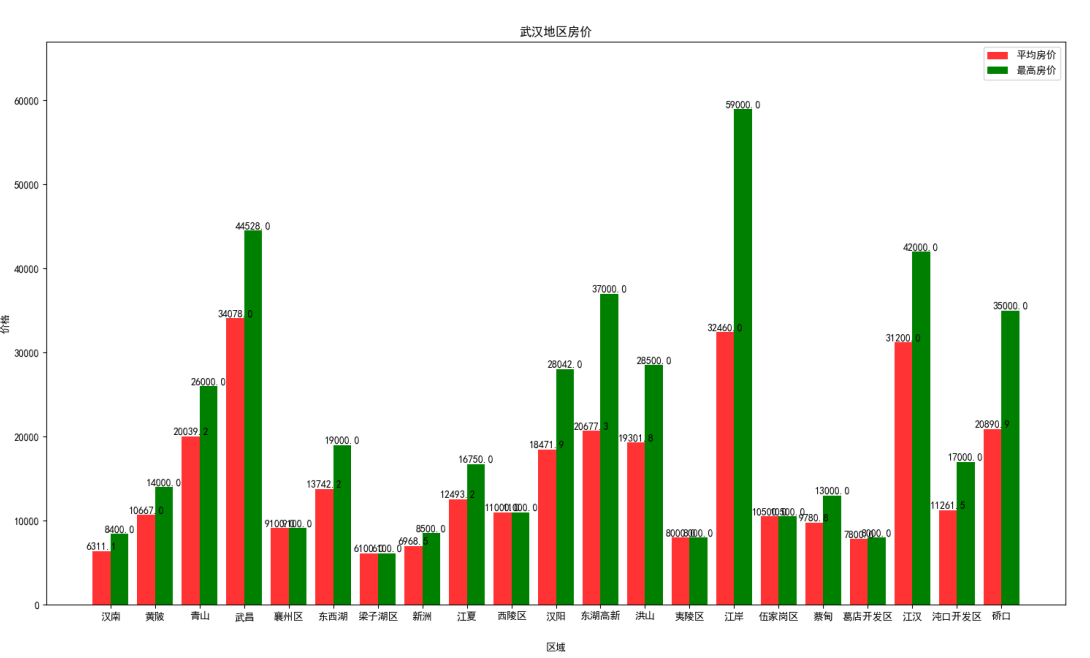
武汉地区房价水平柱形图:

4.3.2对数据进行聚合处理并将经纬度存储在txt文档中
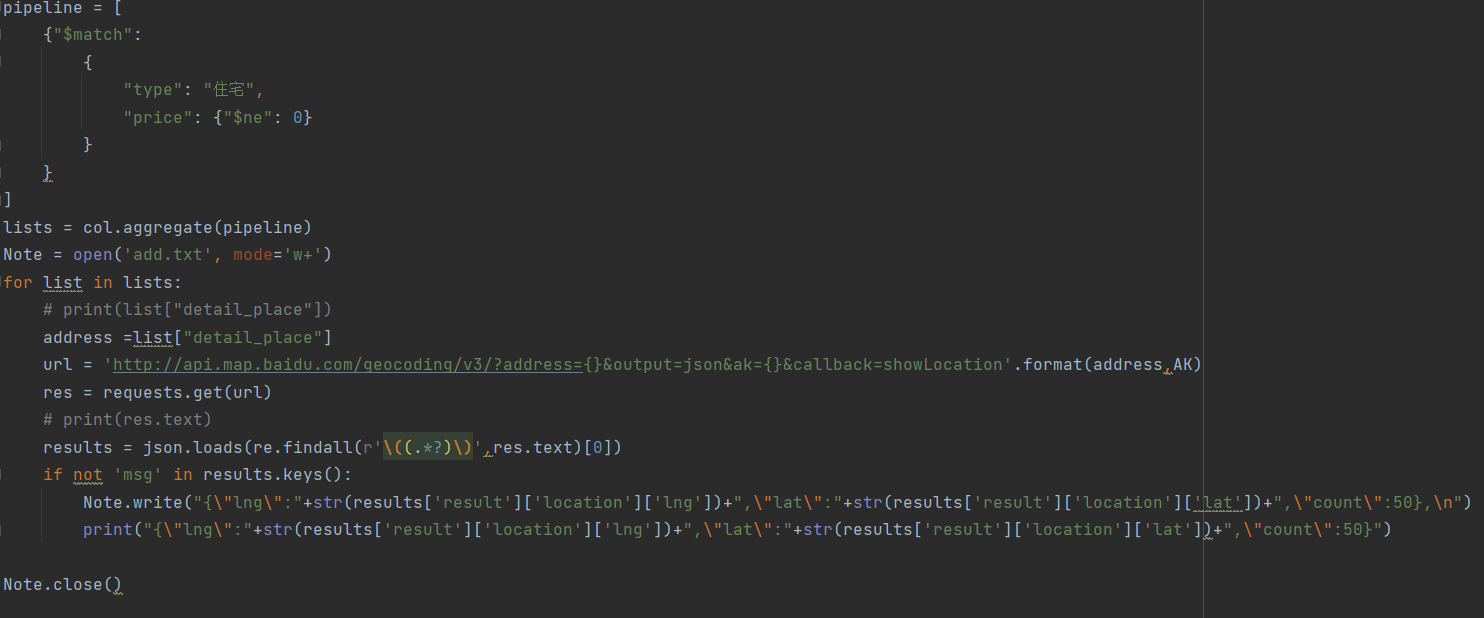
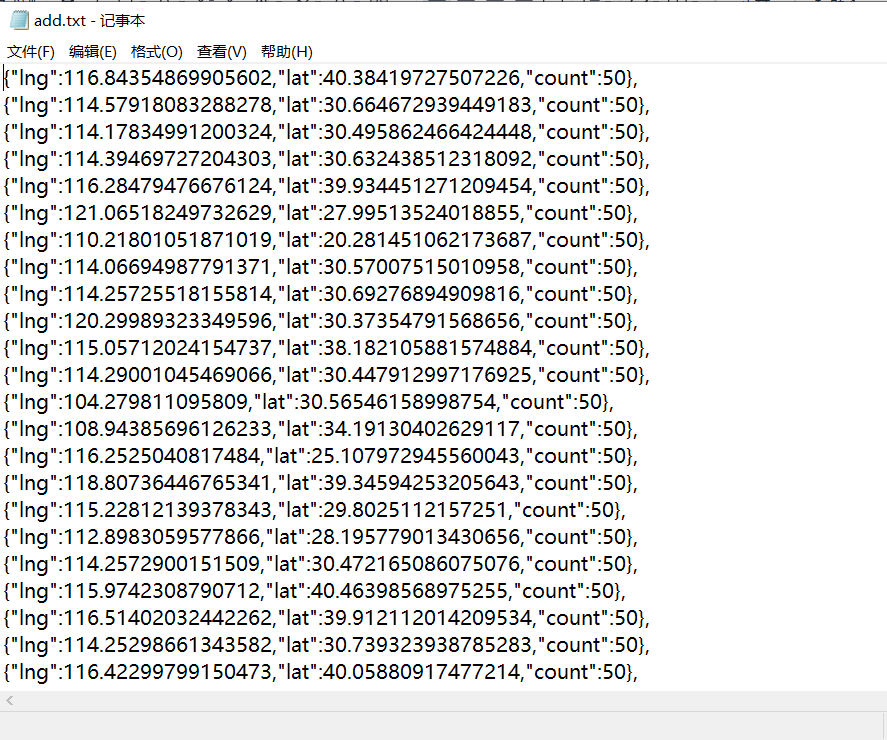
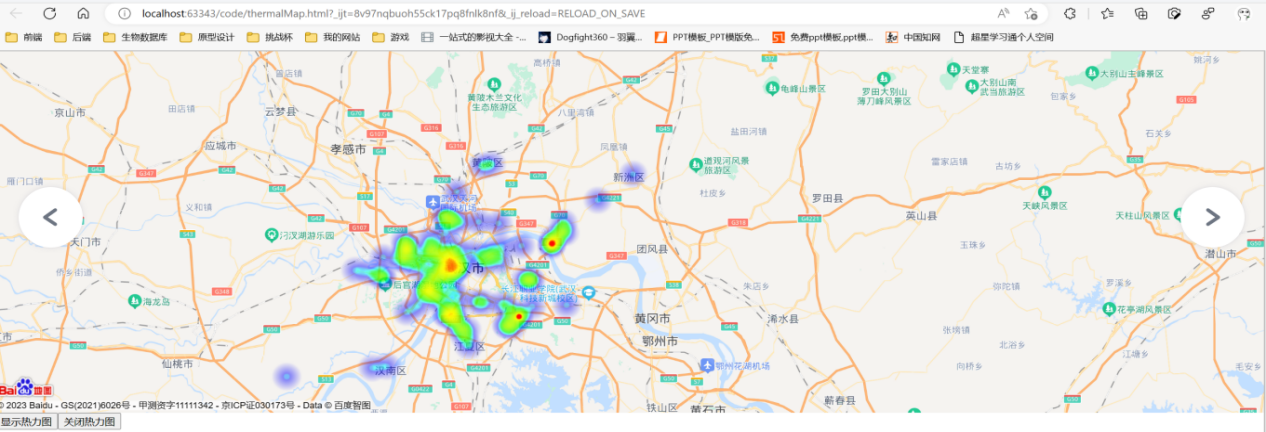
源码如图所示:ak 不可用,请自行在百度开发平台申请密钥进行热力图生成