Do design No code | 只设计不码码

- 未经版权所有者明确授权,禁止发行本手册及其被实质上修改的版本。
- 未经版权所有者事先授权,禁止将此作品及其衍生作品以标准(纸质)书籍形式发行。
- 未与任何第三方以任何形式合作。




- 前言
- 技术栈选型
- 代码仓库
- 用户体系
- 购物体系
- 营销体系
- 活动营销系统
- 销售营销系统(满减/买送/加价购/限时购...)
- 基础服务
- 交易中心
- 订单中心
- 仓储系统
- 地址服务
- 物流系统
- 售后服务
- 基础服务
- 接口静态化服务
- 上传服务
- 消息服务
- 短信
- 邮件
- 微信模板消息
- 站内信
一直从事互联网电商开发三年多的时间了,回头想想却对整个业务流程不是很了解,说出去很是惭愧。但是身处互联网电商的环境中,或多或少接触了其中的各个业务,其次周边还有很多从事电商的同事和朋友,这都是资源。于是,我决定和我的同事、盆友们、甚至还有你们去梳理整个流程并分享出来,谈不上结果要做的多么好,至少在每一个我们有能力去做好的地方,一定会细致入微。
除此之外,同时为了满足我们自身在工作中可能得不到的技术满足感,我们在做整个系统设计的过程中,会去使用我们最想用的技术栈。技术栈这一点我们借助docker去实现,所以最终的结果:一方面我们掌握了业务的东西,另一方面又得到了技术上的满足感,二者兼得。
最后,出于时间的考虑,我们提出了一个想法Do design No code。【只设计不码码】 这句话的意思:最终我们设计出来整个系统的数据模型,接口文档,甚至交互过程,以及环境部署等,但是最后我们却不写代码。是吧?如果这样了写代码还有什么意义。当然,也不全是这样,出于时间的考虑当然也会用代码实现出来的,说不定最后正是对面的你去实现的。
其次,这些内容肯定有考虑不全面或者在上规模的业务中存在更复杂的地方,欢迎指出,我们也希望学习和分享您的经验。
- 基础环境
+ k8s
+ docker
- 存储
+ mysql
+ redis
* codis
* redis主从
- queue
+ kafka
+ rocketmq
+ rabbitmq
- gw
+ kong
+ zuul
- webserver
+ nginx/openresty
+ envoy
- server
+ go
+ php
- frontend
+ vue
- rpc
+ grpc
+ thrift
- 基础能力
+ 监控
* zipkin
* elk
* falcon
+ 服务发现
* zookeeper
* etcd
+ 持续集成
* ci/cd
- 搜索
+ es
+ solr
请您耐心等待...
今天,我们开始第一部分用户体系的设计。本文分为如下四大模块:
- 架构设计
- 数据模型设计
- 交互设计
- 接口设计
当你第一次接触和用户相关的互联网产品时,或者曾今在我眼里。用户体系无非就是“登录”和“注册”,“修改用户信息”这些,等。简单来做的话,无非我们需要一张表去记录用户的身份信息:注册时(insert操作),往表里插入一个数据;登录时(select&update操作),通过用户标识(手机号、邮箱等)判断用户的密码是否正确;修改用户信息(select&update操作),就是直接update这个uid的用户信息(头像、昵称等)。

这样设计的确没什么问题,很简单不是么。但是随着业务的发展,一方面我们需要提供统一的用户管理(高内聚),又要提高系统的可扩展性,所以我想呈现出来的是我理解的一个基本用户体系应该有的东西。
首先我们对原有的用户表进行再一次的抽象(抽离用户注册、登录依赖的字段、第三方登录) -> 账户表,为什么这么做?随着业务的发展,以前只维护一个产品,也许某一天又开发新的产品,这样我们就可以统一的维护我们公司所有产品的注册登录逻辑,不同的产品只维护该产品和用户相关的信息即可(具体依赖产品形态)。如下图所示:

上图中,还提到了第三方登录/员工表/后台权限管理,这些都是一些用户体系基本必备的结构。
第三方登录:第三方也是登录方式的一种,我们也把它抽象到账户的一部分,如上图所示。其次,关于第三方登录这里存在一个交互方式设计存在的问题,后面交互设计时会提到。
员工:因为上面我们抽离了账户表,所以内部的管理系统后台也可以统一的使用账户表的登录逻辑,这样全公司在账号这个事情上达到了真正的高内聚。
提到了员工,我们的内部各种系统后台肯定涉及各种的权限管理,所以这里提到了简单的RBAC(基于角色的权限控制),具体的逻辑数据模型设计会提到。
随着业务产品形态的越来越复杂,在设计架构的时候,我们需要分析其中的变与不变:
- 变:越来越多的产品个性化用户需求
- 不变:注册登录的逻辑
最终的结果,我们把原有的用户拆成了账户和用户,同时我们也要在这里明确这两个概念的区别:
- 账户:整个体系唯一生产uid的地方,内聚注册登录逻辑,不涉及产品业务需求
- 用户:不同产品个性化的用户需求信息
最终的架构图如下:
- 第一部分:账户(服务层)
- 第二部分:用户(应用层,无限水平扩展)
- 第三部分:员工(应用层,员工权限体系)

对应上面的架构,我们很容易设计出我们的数据模型(这里假设我们目前只有一个对C端的应用):
账户 -> 1.账户表
用户 -> 2.用户表
员工 -> 3.员工表
除了上面三张表外,还需要我们的R(role)B(base)A(access)C(control)权限管理,RBAC基于角色的权限管理大家应该很熟悉,这里我就不详细说了,简单的RBAC首先需要:
4.系统菜单表(菜单即权限),系统的uri路径
5.权限表(菜单即权限),具体的权限就是访问系统的菜单
6.角色表,一个角色具有哪些权限
7.员工和角色的关联表,一个员工属于哪个角色
好了一个简单的RBAC涉及的表基本罗列出来了,但是在我的工作经历中大家实现的权限管理往往只针对某个系统,这样对于众多的系统后台来说就是乱、重复造轮子、权限管理效率低。所以我在上面的架构设计中把权限作为了一个服务为全系统提供基础服务能力。而达到这个目的的结果我只需要再增加一张表:
8.后台管理系统表, 登记所有的后台管理系统(这样通过系统id和系统资源uri的id就可以全局构成唯一性,单纯的uri存在重复的可能性,用uri不用url的原因是域名存在变动的可能性)
最后我们的用户体系应该基本就上面8张表。咦,貌似漏掉了第三方登录,我们加上吧,很简单如下:
9. 第三方用户登录表,记录不同第三方的用户标示
最最后就是上面的9张表了,具体的表结构和sql如下:

账户模型
-- 账户模型
CREATE TABLE `account_user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '账号id',
`email` varchar(30) NOT NULL DEFAULT '' COMMENT '邮箱',
`phone` varchar(15) NOT NULL DEFAULT '' COMMENT '手机号',
`username` varchar(30) NOT NULL DEFAULT '' COMMENT '用户名',
`password` varchar(32) NOT NULL DEFAULT '' COMMENT '密码',
`create_at` int(11) NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_ip_at` varchar(12) NOT NULL DEFAULT '' COMMENT '创建ip',
`last_login_at` int(11) NOT NULL DEFAULT '0' COMMENT '最后一次登录时间',
`last_login_ip_at` varchar(12) NOT NULL DEFAULT '' COMMENT '最后一次登录ip',
`login_times` int(11) NOT NULL DEFAULT '0' COMMENT '登录次数',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`),
KEY `idx_email` (`email`),
KEY `idx_phone` (`phone`),
KEY `idx_username` (`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='账户';
-- 第三方账户
CREATE TABLE `account_platform` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`uid` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '账号id',
`platform_id` varchar(60) NOT NULL DEFAULT '' COMMENT '平台id',
`platform_token` varchar(60) NOT NULL DEFAULT '' COMMENT '平台access_token',
`type` tinyint(1) NOT NULL DEFAULT '0' COMMENT '平台类型 0:未知,1:facebook,2:google,3:wechat,4:qq,5:weibo,6:twitter',
`nickname` varchar(60) NOT NULL DEFAULT '' COMMENT '昵称',
`avatar` varchar(255) NOT NULL DEFAULT '' COMMENT '头像',
`create_at` int(11) NOT NULL DEFAULT '0' COMMENT '创建时间',
`update_at` int(11) NOT NULL DEFAULT '0' COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_uid` (`uid`),
KEY `idx_platform_id` (`platform_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='第三方用户信息';用户模型
-- 用户模型
CREATE TABLE `skr_member` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '用户id',
`uid` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '账号id',
`nickname` varchar(30) NOT NULL DEFAULT '' COMMENT '昵称',
`avatar` varchar(255) NOT NULL DEFAULT '' COMMENT '头像(相对路径)',
`gender` enum('male','female','unknow') NOT NULL DEFAULT 'unknow' COMMENT '性别',
`role` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '角色 0:普通用户 1:vip',
`create_at` int(11) NOT NULL DEFAULT '0' COMMENT '创建时间',
`update_at` int(11) NOT NULL DEFAULT '0' COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_uid` (`uid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='账户信息';员工模型
-- 员工表
CREATE TABLE `staff_info` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '员工id',
`uid` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '账号id',
`email` varchar(30) NOT NULL DEFAULT '' COMMENT '员工邮箱',
`phone` varchar(15) NOT NULL DEFAULT '' COMMENT '员工手机号',
`name` varchar(30) NOT NULL DEFAULT '' COMMENT '员工姓名',
`nickname` varchar(30) NOT NULL DEFAULT '' COMMENT '员工昵称',
`avatar` varchar(255) NOT NULL DEFAULT '' COMMENT '员工头像(相对路径)',
`gender` enum('male','female','unknow') NOT NULL DEFAULT 'unknow' COMMENT '员工性别',
`create_at` int(11) NOT NULL DEFAULT '0' COMMENT '创建时间',
`update_at` int(11) NOT NULL DEFAULT '0' COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_uid` (`uid`),
KEY `idx_email` (`email`),
KEY `idx_phone` (`phone`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='员工信息(这里列了大概的信息,多的可以垂直拆表)';
系统权限管理模型
-- 权限管理: 系统map
CREATE TABLE `auth_ms` (
`id` smallint(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`ms_name` varchar(255) NOT NULL DEFAULT '0' COMMENT '系统名称',
`ms_desc` varchar(255) NOT NULL DEFAULT '0' COMMENT '系描述',
`ms_domain` varchar(255) NOT NULL DEFAULT '0' COMMENT '系统域名',
`create_at` int(11) NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`),
KEY `idx_domain` (`ms_domain`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='系统map(登记目前存在的后台系统信息)';
-- 权限管理: 系统menu
CREATE TABLE `auth_ms_menu` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`ms_id` smallint(11) unsigned NOT NULL DEFAULT '0' COMMENT '系统id',
`parent_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '父菜单id',
`menu_name` varchar(255) NOT NULL DEFAULT '0' COMMENT '菜单名称',
`menu_desc` varchar(255) NOT NULL DEFAULT '0' COMMENT '菜描述',
`menu_uri` varchar(255) NOT NULL DEFAULT '0' COMMENT '菜单uri',
`create_at` int(11) NOT NULL DEFAULT '0' COMMENT '创建时间',
`is_show` enum('yes','no') NOT NULL DEFAULT 'no' COMMENT '是否展示菜单',
`create_by` int(11) NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`),
KEY `idx_ms_id` (`ms_id`),
KEY `idx_parent_id` (`parent_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='系统menu';
-- 权限管理: 系统权限
CREATE TABLE `auth_item` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`ms_id` tinyint(11) unsigned NOT NULL DEFAULT '0' COMMENT '系统id',
`menu_id` varchar(255) NOT NULL DEFAULT '0' COMMENT '页面/接口uri',
`create_at` int(11) NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`),
KEY `idx_ms_menu` (`ms_id`, `menu_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='系统权限';
-- 权限管理: 系统权限(权限的各个集合)
CREATE TABLE `auth_role` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`name` varchar(255) NOT NULL DEFAULT '0' COMMENT '角色名称',
`desc` varchar(255) NOT NULL DEFAULT '0' COMMENT '角描述',
`auth_item_set` text COMMENT '权限集合 多个值,号隔开',
`create_at` int(11) NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='员工角色';
-- 权限管理: 角色与员工关系
CREATE TABLE `auth_role_staff` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`staff_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '员工id',
`role_set` text COMMENT '角色集合 多个值,号隔开',
`create_at` int(11) NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`),
KEY `idx_staff_id` (`staff_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='权限角色与员工关系';
友情提示:一大波图片即将到来,此处图片较多,不清楚的可点击大图查看
注册成功之后存在至少两种交互方式:
- 注册成功 -> 跳转到登录页面
- 注册成功 -> 自动登录 -> 跳转到应用首页(或者其他页面)
具体交互流程如下:






快捷登录的流程基本和上面一致只是验证密码换成了验证验证码。

第三方登录的交互其实存在这样的问题:
- 第三方账户登录成功后还需要绑定手机号/Email吗?
因为我发现有些PM为了提高用户使用的简单快捷性,往往第三方登录成功后会直接产生uid,而不进行账号的绑定。这样之后在再进行账号绑定就涉及账号合并的问题,很麻烦(如果有钱包等)。如果我们一开始就进行绑定操作,这样未来账号的关系就清晰明了便于维护,第三方登录其实就相当于普通账号的别名。 最后这个事情做不做的结果就是,账户表account_user和第三方用户信息表account_platform是的一对多还是一对一的关系。
- 如果绑定,已经注册的手机号/Email是否可以绑定?
这个还好说,一般来说绑定的选择基本是正确的。最后具体的流程图如下:

交互界面图如下:

首先,我们的后台管理系统需要个响亮的称号,想了一会以前公司用过apollo,于是我准备用mars但突然冒出来个earth,地球万物之根,刚好我们这又是个全业务的基础服务管理系统,哈哈就这样吧~ Earth System
Earth System的权限管理功能主要分为以下四部分:
- 系统管理(The manage system page)
- 编辑页面
- 列表页面
- 菜单管理(The menu page)
- 编辑页面
- 列表页面
- 角色管理(The role page)
- 编辑页面
- 列表页面
- 员工与角色关联管理(The role staff map page)
- 编辑页面
- 列表页面
具体交互如下:

1.注册接口
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| username | string | 非必传 | 用户账号 |
| string | email/phone两者择一 | 用户邮箱 | |
| phone | string | email/phone两者择一 | 用户手机号 |
| code | int | 必传 | 验证码 |
交互方式一(跳转到登录页面)响应内容:
{
"code": "200",
"msg": "OK",
"result": []
}交互方式二(跳转到首页页面)响应内容:
{
"code": "200",
"msg": "OK",
"result": {
"s_token": "string, 用户会话标示",
"s_token_expire": "string, 用户会话标示过期时间,0不过期",
"username": "string, 用户名",
"nickname": "string, 用户昵称",
"avatar": "string, 用户头像",
"gender": "string, 用户性别,male:男,female:女,other:未知",
}
}2.登录接口
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| username | string | username/email/phone三者择一 | 用户账号 |
| string | username/email/phone三者择一 | 用户邮箱 | |
| phone | string | username/email/phone三者择一 | 用户手机号 |
| password | string | 必传 | 密码 |
响应内容:
{
"code": "200",
"result": {
"s_token": "string, 用户会话标示",
"s_token_expire": "string, 用户会话标示过期时间,0不过期",
"nickname": "string, 用户昵称",
"username": "string, 用户名",
"avatar": "string, 用户头像",
"gender": "string, 用户性别,male:男,female:女,other:未知",
}
}3.快捷登录接口
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| string | email/phone两者择一 | 用户邮箱 | |
| phone | string | email/phone两者择一 | 用户手机号 |
| code | int | 必传 | 验证码 |
响应内容:
{
"code": "200",
"result": {
"s_token": "string, 用户会话标示",
"s_token_expire": "string, 用户会话标示过期时间,0不过期",
"nickname": "string, 用户昵称",
"username": "string, 用户名",
"avatar": "string, 用户头像",
"gender": "string, 用户性别,male:男,female:女,other:未知",
}
}4.第三方登录接口
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| type | string | 必传 | 平台类型 1:facebook,2:google,3:wechat,4:qq,5:weibo,6:twitter |
| platform_id | string | 必传 | 第三方平台用户ID |
| platform_token | string | 必传 | 第三方平台令牌 |
响应内容:
{
"code": "200",
"result": {
"s_token": "string, 用户会话标示",
"s_token_expire": "string, 用户会话标示过期时间,0不过期",
"username": "string, 用户名",
"nickname": "string, 用户昵称",
"avatar": "string, 用户头像",
"gender": "string, 用户性别,male:男,female:女,other:未知",
}
}5.用户信息修改接口
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| username | string | 非必传 | 用户账号 |
| nickname | string | 非必传 | 昵称 |
| avatar | string | 非必传 | 头像url |
| gender | string | 非必传 | 用户性别,male:男,female:女,other:未知 |
响应内容:
{
"code": "200",
"result": {
"username": "string, 用户名",
"nickname": "string, 用户昵称",
"avatar": "string, 用户头像",
"gender": "string, 用户性别,male:男,female:女,other:未知",
}
}6.用户登录状态校验
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| s_token | string | 必传 | 用户会话标示 |
响应内容:
{
"code": "200",
"result": {
"s_token_expire": "string, 用户会话标示过期时间,0不过期, -1登录失效",
}
}账户服务:
- 注册
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| username | string | 非必传 | 用户账号 |
| string | email/phone两者择一 | 用户邮箱 | |
| phone | string | email/phone两者择一 | 用户手机号 |
交互方式一(跳转到登录页面)响应内容:
{
"code": "200",
"msg": "OK",
"result": {
"uid": "string, 账户ID"
}
}- 登录
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| username | string | 非必传 | 用户账号 |
| string | email/phone两者择一 | 用户邮箱 | |
| phone | string | email/phone两者择一 | 用户手机号 |
| password | string | 必传 | 密码 |
响应内容:
{
"code": "200",
"msg": "OK",
"result": {
"uid": "string, 账户ID"
}
}- 第三方登录
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| type | string | 必传 | 平台类型 1:facebook,2:google,3:wechat,4:qq,5:weibo,6:twitter |
| platform_id | string | 必传 | 第三方平台用户ID |
| platform_token | string | 必传 | 第三方平台令牌 |
响应内容:
{
"code": "200",
"result": {
"uid": "string, 账户ID",
"nickname": "string, 用户昵称",
"avatar": "string, 用户头像",
}
}权限服务
- 获取系统菜单
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| ms_id | string | 必传 | 系统ID |
响应内容:
{
"code": "200",
"msg": "OK",
"result": {
"ms_name": "string, 系统名称",
"ms_desc": "string, 系描述",
"ms_domain": "string, 系统域名",
"list": [
{
"parent_id": "string, 父菜单ID",
"menu_id": "string, 菜单ID",
"menu_name": "string, 菜单ID",
"menu_desc": "string, 菜描述",
"menu_uri": "string, 菜单uri",
"child" : [
{
"parent_id": "string, 父菜单ID",
"menu_id": "string, 菜单ID",
"menu_name": "string, 菜单ID",
"menu_desc": "string, 菜描述",
"menu_uri": "string, 菜单uri",
"child" : []
}
]
}
]
}
}- 权限校验
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| menu_id | string | 必传 | 菜单ID |
响应内容:
{
"code": "200",
"msg": "OK",
"result": []
}对于一个电商来讲,购物车是整个购买流程最重要的一步。因为电商发展到今天购物车不仅仅只是为了完成打包下单的功能;也是收藏、对比、促销提醒、相关推荐的重要展示窗口。如此多的能力我们该如何设计保证购物车的高性能、以及良好的扩展能力来满足未来的发展呢?
今天开始我们就以一个假定的场景来输出一个购物车设计:某某电商平台,是一个多租户模式(我们前面的诸多设计都是多租户模式),用户可以把商品加入到购物车,并切按照商户纬度来展示、排序。当然购物车也支持常规的各种操作:选择、删除、清空、商品失效等。并且有相关的促销能够提醒用户。同时为了监控、运营,要支撑购物车数据同步到监控、数仓等能力。
本文会从用户使用的角度以及服务端两个角度来讲解系统的能力。本篇我们的主要目的是说清楚购物车的能力以及一些逻辑。下一篇会进行购物车模型设计以及接口定义。
我们先来定义一下在用户侧用户操作购物车的功能有哪些?
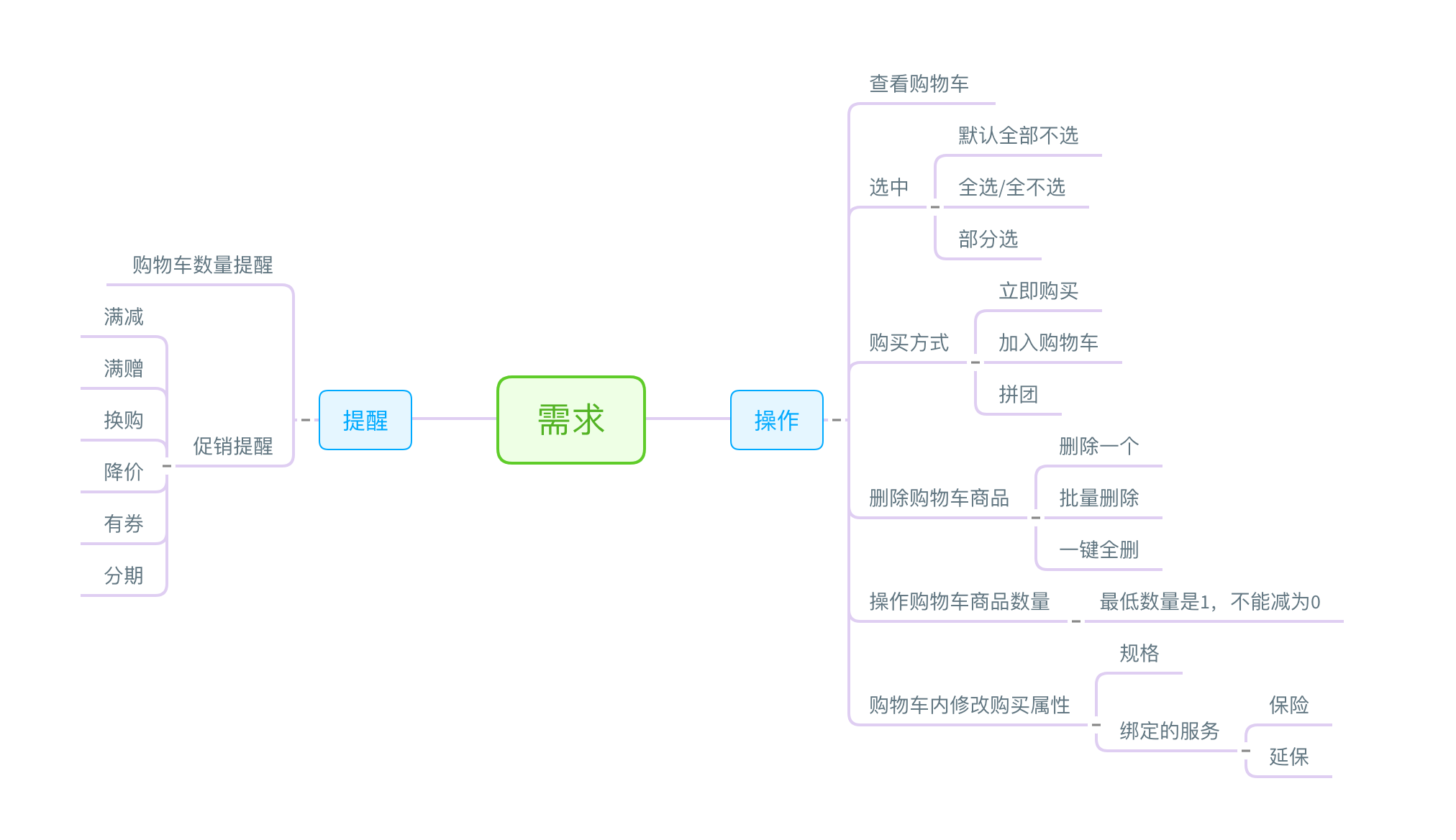
一个购物车基本的能力基本上都在上图中,下面我们一一来分解。
我们从用户的角度来看,购物车对于用户来说可以添加商品到购物车(加购物车、立即购买都属于一种添加方式);加入进购物车后,不想要了可以删除该商品(删一个、删多个、清空);想多买可以修改购买数量,发现钱不够可以减少购买数量;或者发现红色的比白色更漂亮,可以在购物车方便的进行更换规格;对于一些价格很贵的商品,能够在购物车添加一些保障服务(其实是绑定的虚拟商品);在要去结算的时候,还会提供选择能力让用户决定哪些商品真的本次要购买。
通过上面的描述我们可以看到这个过程是有其内在联系的。这里说一下关于选中功能,业界有两种做法,各有优劣,我们来看一下。淘宝的产品选中状态是保存在客户端的,并且默认不选中,刷新、重新打开APP状态会消失;京东、苏宁这一类是保存在服务端,会记录用户选中状态。针对这两种情况各有优劣。
客户端:
- 性能,选中/不选中的逻辑直接放在本地做,减少网络请求
- 体验,多端不能同步,但是购物车相对来说更像是一个收藏夹,每次用户自己选择也无可厚非
- 计算,价格计算时需要上传本地选中商品(也可以本地计算)
- 实现,主要靠客户端实现,与服务端无关,研发解耦合
服务端:
- 性能,每次操作选中都需要调用服务端,而该操作可能很频繁,除了网络损耗,服务端也需要考虑该如何快速找到修改的商品
- 体验,多端同步状态,记录历史状态
- 计算,服务端可获取数据,请求时无须上传额外数据
- 实现,服务端与客户端需要商定如何交互,以及返回数据(每次选中会导致价格变化),耦合在一起
个人认为这两种方式并无谁具备明显优势,完全是一种基于业务模式以及团队情况来做选择。我们这里后续的设计会基于在服务端保存商品选中状态。
在整个操作逻辑中,有个两个比较重要的地方单独说明一下:购买方式与购物车内修改购买属性
主要的购买方式有立即购买、加入购物车、拼团购三种方式。
首先普通的加入购物车没什么太多要说的。重点来看下立即购买与拼团。
立即购买在于操作上来说就是选择商品后直接到了订单确认页面,没有购物车中去结算这一步。但是它的实现却可以依赖购物车的逻辑来做,我们来看一下使用购物车与不使用购物车实现这个逻辑有什么差别?
如果使用购物车来实现,也就是用户点击立即购买时,商品本质上还是加入到购物车中,但这个购物车却与原型的购物车不同,因为该购物车只能加一个商品,并且每次操作都会被覆盖。在视角效果上也是直接从商品详情页面跳转到订单确认页面。来看看这种方式的好处
- 与购物车在订单确认、下单逻辑上一致,内部可以直接通过购物车获取数据
- 需要一个独立的专门用于一键购买的购物车来实现,内存有消耗
另外一种实现方式使用一个新的数据结构,因为一般来说一键购买更简单,它只需要商品信息、价格信息即可。每次交互均可以根据sku_id来获取。
- 订单确认、下单逻辑上需要进行改造,每次请求之间要传递约定参数
- 节省内存,上下交互通过sku_id来保证
我们会采用使用在服务端一键购买以独立的购物车形式来实现。购物车的数据模型一致,保证了后续处理流程上的一致。
对于拼团,他其实分为两部分,首先是开团这个动作,当团成立后。我们可以选择将成团的商品加入普通购物车,同时可以加购其它商品。也可以选择将成团商品加入一键购买的购物车,保证成团商品只能买一个。拼团模式更像是加入购物车的一个前置条件。本质上它对于购物车的设计没有影响。
这里主要是指可以在购物车便捷的操作一些需要在spu纬度操作的事情,比如:变更规格(也就是更换sku),以及选择绑定到spu纬度的服务(保险、延保等)。
我们重点说一下选择绑定的服务。例如:我们买一个手机,厂家提供了延保、各种其它附加服务,一般情况这种服务都是虚拟商品。但是这有个特殊情况。这些保障服务首先不能单独购买,其次他是跟主商品的数量息息相关。比如买两个手机,如果选择了加购服务,那么这些服务的数量必须是2,这会是一个联动关系。
这些保障服务是不能进行单独购买的,它一定要跟特定的商品捆绑销售。
服务端在存储这部分数据时一定需要考虑如何保存这种层级关系,这部分我们后面模型设计的时候大家会看到。
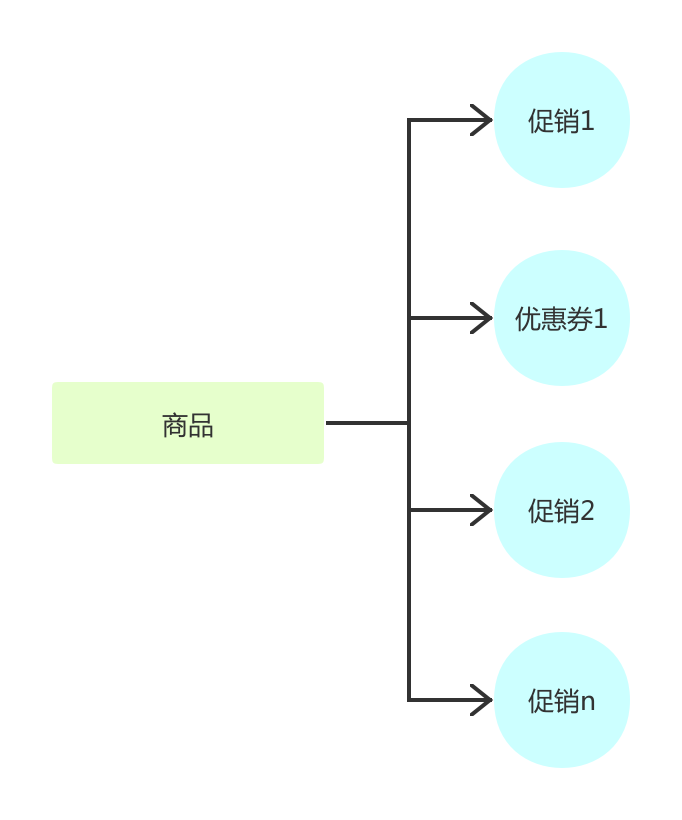
促销提醒很简单,返回的购物车数据,每一个商品应该携带当前的促销信息。这部分重点在于怎么获取促销信息,会在服务端看到。
然后说下购物车数量的提醒,也就是显示当前购物车商品的数量。一般来说进入到APP就会调用一个接口,获取用户的未读消息数、购物车商品数等。这里是需要非常高的读取速度。那么这种需求该如何满足呢?
方案一: 我们可以设计一个结构保存了用户相关的这种提醒信息数量,每次直接读取这个数据即可。不需要去跟消息服务、购物车服务打交道拿这些数据。
方案二: 在消息、购物车的模型中均设计一个保存总数量的字段,在读取数据的接口中,通过并发的方式调用这些服务拿到数据后进行聚合,这样在速度上只取决于最慢的服务。
这里我们的设计会采用 方案二,因为这样在某种程度上效率可以得到保证,同时整个系统的结构数据的一致性更容易得到保障。当然这里有个细节一定要注意,并发读取一定要设计超时,不要因为某个服务读数问题而导致拖累整个接口的性能。
接下来再来看看促销,这部分除了提醒,还需要提供对应的入口,让用户完成促销的操作。比如说某个商品有券,那么可以直接提供入口去领取;可凑单,有入口进入凑单列表并选择商品等。这部分需要解决的问题是服务端该如何及时从商品纬度拿到这些促销活动。
从用户的视角看完了,我们再来站在研发的角度看看服务端有哪些事情要做
还是先来看看需求的汇总图:
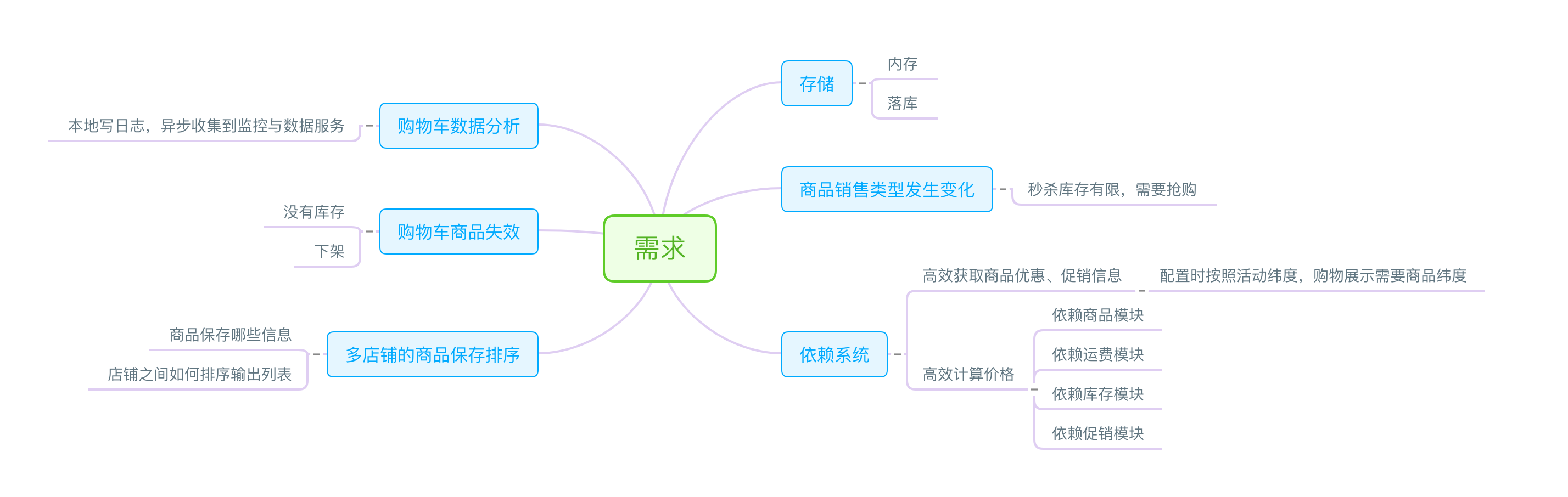
对于存储,首选肯定是内存存储,至于要不要落库,我觉得没有必要。说下我的理由:
- 购物车的数据相对变化非常频繁,落库成本比较高,如果异步方式落库,很难保障一致性
- 极端情况,cache奔溃了,仅仅需要用户重新加入购物车,并且我们可以通过cache的持久化机制来保证数据的恢复
所以对于购物车,我们只会把数据完全保存在内存中。
现在我们来讨论 商品销售类型发生变化 这个问题。这是什么意思呢?大家想一下:比如我把A商品加入到购物车,但是一直没有结算。这时运营说针对A商品搞一个活动,拿出10个库存5折购。那么问题来了,对于之前购物车中就有该商品的用户该如何处理?这里解决的主要问题是:购物车有该商品的用户不能直接以5折买。几种方案,我们来看一下:
方案一: 促销配置后,所有购物车中有该商品的用户失效或删除,这个方案首先被pass,操作成本太高,并且用户体验差
方案二: 购物车中要区分同一个SKU,不同销售类型。也就是说在我们的购物车中不是按照SKU的纬度来加商品,而是通过 SKU+售卖类型 来生成一个唯一识别码。
可以看到 方案二 解决了同一个sku在购物车并存的问题,并且库存之前互相不影响。不过这里又有一个问题?商品的售卖类型(或者说这个标记),该怎么什么地方设置?好像商品系统可以设计、促销系统也可以设置。我们的逻辑中会在促销系统中进行配置。因为商品属于基础逻辑,如果一改就是全局库存受到影响。活动结束后很难做到自动正常售卖。因此这个标记应该落到活动中进行设置(活动设置时会通过促销系统获取该商品之前的活动是否互斥,以确保配置的活动不会互相矛盾)。
购物车系统依赖了非常多的其它系统。
- 商品系统
- 库存系统
- 促销系统
- 结算系统
这些依赖的系统,有的是为了传输数据,有的是为了获取数据。我们按照这两个纬度来看一下。
服务端要解决的是促销的提醒与价格计算问题。
现来说计算,针对这部分最佳的方式是,调用结算中心的价格计算。我们来看一下购物车中的价格计算与订单结算时的价格计算的差异。
首先购物车中计算价格时不知道用户的地址,这会影响运费的计算;再是不知道用券的情况。那么其实如果解决了这两个问题,我们就可以让价格计算出自同一个逻辑,仅仅是部分入参不同罢了。因此我们这里计算时可以按照最高运费来计算,同时用券默认在购物车都不使用券。对于促销问题这里是可以通过促销系统确认选中的商品可以享受哪些价格的。因此促销的价格应该计算在内。
接下来在再来说说如何为用户高效的提供促销的信息。先从我们的配置视野出发。
我们在配置一个促销活动或者发一张券时,都是将多个商品归到一个促销活动或者券的下面。如果按照活动、券的纬度来获取商品效率相对比较高。
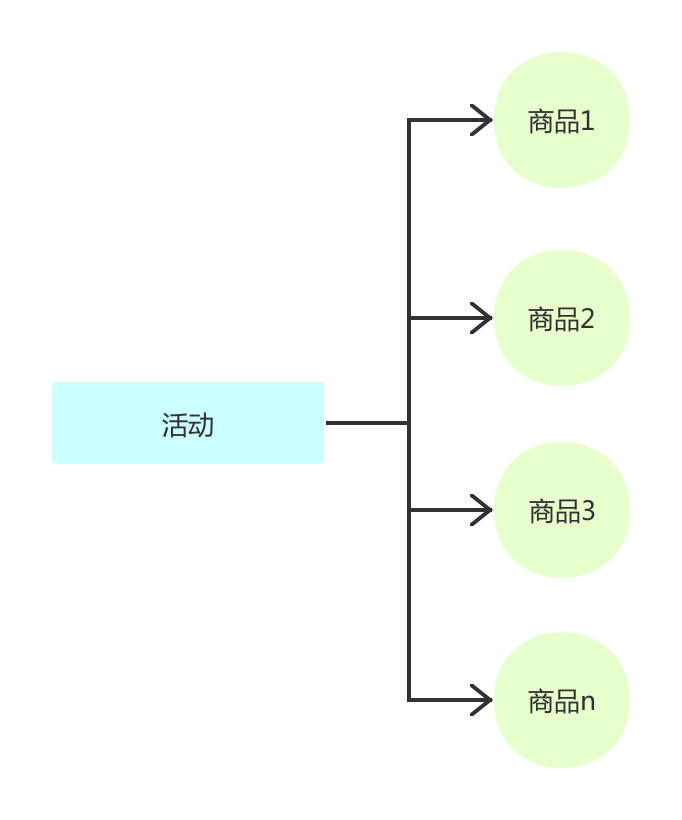
但是在购物车的场景中发生了一个变化。我们是需要从商品纬度获取到该商品的所有活动信息(全平台活动、店铺活动); 那么购物车中为了展示这些信息该怎么做?很常规的一个做法(也确实不少公司是这样):把所有活动信息取出来,遍历出所有跟该商品相关的信息。这种做法效率很低,并且无法满足大规模的应用场景,比如双十一期间。
因此这里为了满足该需求,促销系统需要提供一个能力按照商品获取对应促销(活动、券)。因此一般来讲促销系统配置的活动不能仅仅是按照活动纬度存储,同时还需要生成一份商品纬度的促销信息。
对于购物车数据来说,前端会通过埋点记录加入购物车数据的情况,但是前端埋点一般是记录触发了某个前端操作,但是并不知道该操作是否成功与否。以及无法及时了解当前整体购物车的数据情况。
为了让运营团队更完整的了解购物车当前情况,我们通过后端打本地日志,然后通过日志收集的方式将日志同步给数据、监控等服务。
还有两个小部分没有讲到,一是商品该如何失效,比如:库存没有了、下架了;二是购物车中的商品是多个店铺的,排序的策略是什么?
由于本文我们还只是讨论需求,不涉及具体的模型设计,因此只是介绍方案。首先是商品失效,这很像一个软删除操作,一旦设置,用户侧看到的商品将是无法进行结算的,只能进行删除操作。
对于排序我们会采用的设计是:根据某个店铺在购物车中最后发生操作的时间,最新的操作肯定在最上面。
通过上面我们基本上搞清楚了购物车设计中我们要做什么,依赖的系统要提供什么能力。下篇开始进入数据模型的设计、前后端接口设计。
如果你对购物车上面的需求还有哪些补充,欢迎留言。我们一起来完善。
在上一篇文章 购物车设计之需求分析 描述了购物车的通用需求。本文重点则在如何实现上进行架构上的设计(业务+系统架构)。
架构设计可以分为三个层面:
- 业务架构
- 系统架构
- 技术架构
快速简单的说明下三个架构的意思;当我们拿到购物车需求时,我们说用Golang来实现,存储用Redis;这描述的是技术架构;我们对购物车代码项目进行代码分层,设计规范,以及依赖系统的规划这叫系统架构;
那业务架构是什么呢?业务架构本质上是对系统架构的文字语言描述;什么意思?我们拿到一个需求首先要跟需求方进行沟通,建立统一的认知。比如:规范名词(购物车中说的商品与商品系统中商品的含义是不同的);建立大家都能明白的模型,购物车、用户、商品、订单这些实体之间的互动,以及各自具备什么功能。
在业务架构分析上有很多方法论,比如:领域驱动设计,但是它并不是唯一的业务架构分析方法,也并不是说最好的。适合你的就是最好的。我们常用的实体关系图、UML图也属于业务架构领域;
这里需要强点一点的是,不管你用什么方式来建模设计,有设计总比没设计强,其次一定要将建模的内容体现到你的代码中去。
本文在业务架构上的分析借助了 DDD (领域驱动设计)思想;还是那句话适合的就是最好的。
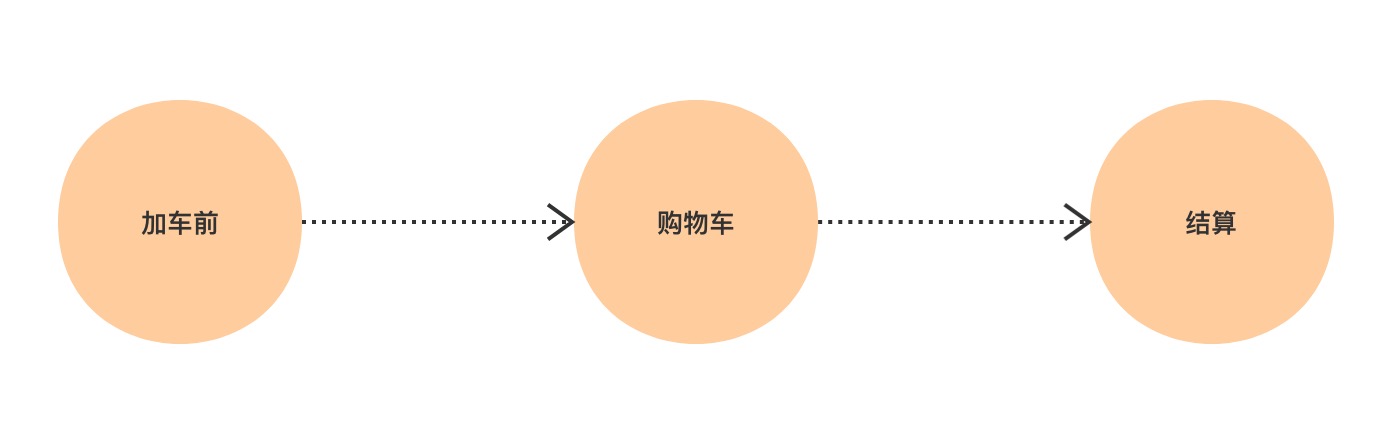
通过前面的需求分析,我们已经明确我们的购物车要干什么了。先来看一下一个典型的用户操作购物车过程。

在这个过程中,用户使用购物车这个载体完成了商品的购买流程;不断流动的数据是商品,购物车这个载体是稳定的。这是我们系统中的稳定点与变化点。
商品的流动方式可能多种多样,比如从不同地方加入购物车,不同方式加入购物车,生命周期在购物车中也不一样;但是这个流程是稳定的,一定是先让购物车中存在商品,然后才能去结算产生订单。
商品在购物车中的生命周期如下:
按照这个过程,我们来看一下每个阶段对应的操作。
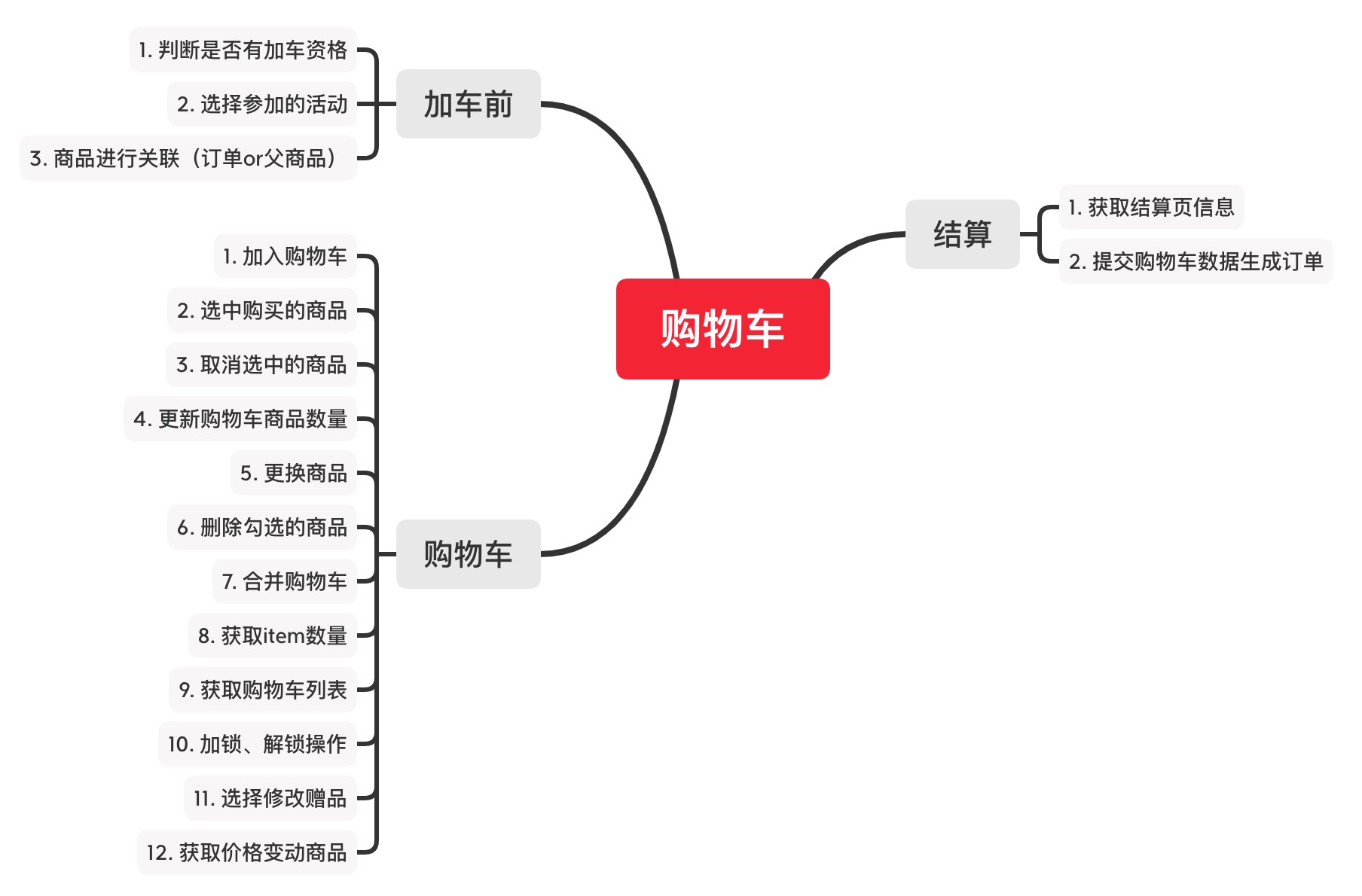
这里注意一点,加车前这个操作其实我们可以放到购物车的添加操作中,但是由于这部分是非常不稳定且多变的。我们将其独立出来,方便后续进行扩展而不影响相对比较稳定的购物车阶段。
上面这三个阶段,按照DDD中的概念,应该叫做实体,他们整体构成了购物车这个域;今天我们先不讲这些概念,就先略过,后面有机会单独发文讲解。
通过流程分析,我们总结出了系统需要具备的操作接口,以及这些接口对应的实体,现在我们先来看加车前主要要做些什么;
加车前其实主要就是对准备加入的购物车商品进行各个纬度的校验,检查是否满足要求。
在让用户加车前,我们首先解决的是用户从哪里卖,然后进行验证?因为同一个商品从不同渠道购买是存在不同情况的,比如:小米手机,我们是通过秒杀买,还是通过好友众筹买,或者商城直接购买,价格存在差异,但是实际上他是同一个商品;
第二个问题是是否具备购买资格,还是上面说的,秒杀、众筹这个加车操作,不是谁都可以添加的,得现有资格。那么资格的检查也是放到这里;
第三个问题是对这个购买的商品进行商品属性上的验证,如是否上下架,有库存,限购数量等等。
而且大家会发现,这里的验证条件可能是非常多变的。如何构建一个方便扩展的代码呢?
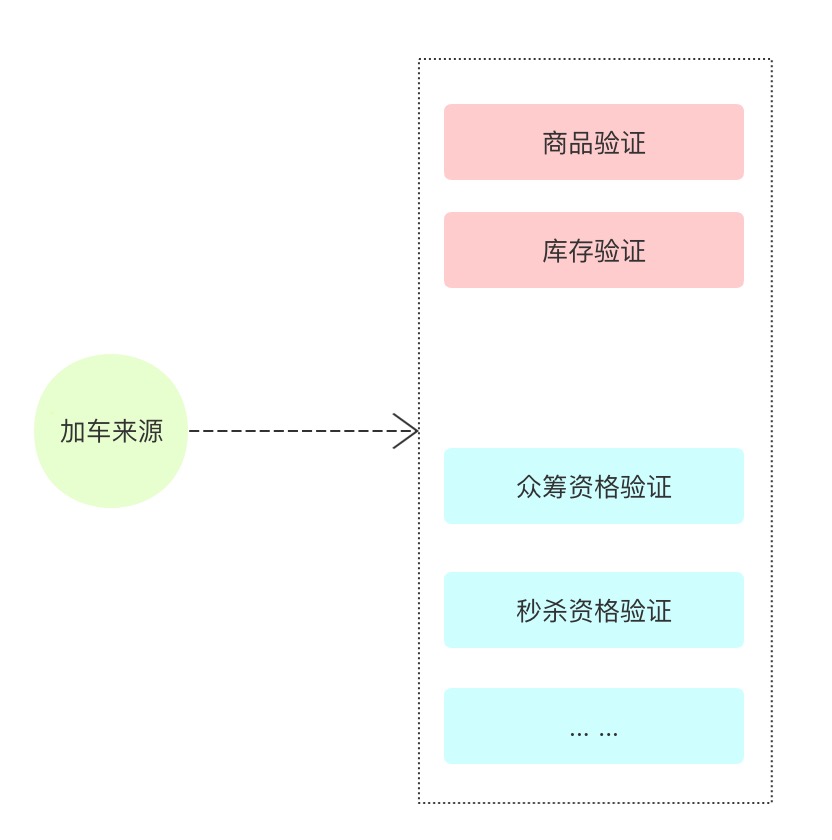
整个加车过程,重要的就是根据来源来区分不同的验证。我们有两种选择方式。
方式一:通过策略模式+门面模式的方式来搞定。策略就是根据不同的加车来源进行不同的验证,门面就是根据不同的来源封装一个个策略;
方式二:通过责任链模式,但是这里需要有一个变化,这个链在执行过程中,可以选择跳过某些节点,比如:秒杀不需要库存、也不需要众筹的验证;
通过综合的分析我选择了责任链的模式。贴一下核心代码
// 每个验证逻辑要实现的接口
type Handler interface {
Skipped(in interface{}) bool // 这里判断是否跳过
HandleRequest(in interface{}) error // 这里进行各种验证
}
// 责任链的节点
type RequestChain struct {
Handler
Next *RequestChain
}
// 设置handler
func (h *RequestChain) SetNextHandler(in *RequestChain) *RequestChain {
h.Next = in
return in
}
关于设计模式,大家可以看我小伙伴的github:https://github.com/TIGERB/easy-tips/tree/master/go/src/patterns
说完了加车前,现在来看购物车这一部分。我们在之前曾讨论过,购物车可能会有多种形态的,比如:存储多个商品一起结算,某个商品立即结算等。因此购物车一定会根据渠道来进行购物车类型的选择。
这部分的操作相对是比较稳定的。我们挑几个比较重要的操作来讲一下思路即可。
通过把条件验证的前置,会发现在进行加车操作时,这部分逻辑已经变得非常的轻量了。要做的主要是下面几个部分的逻辑。
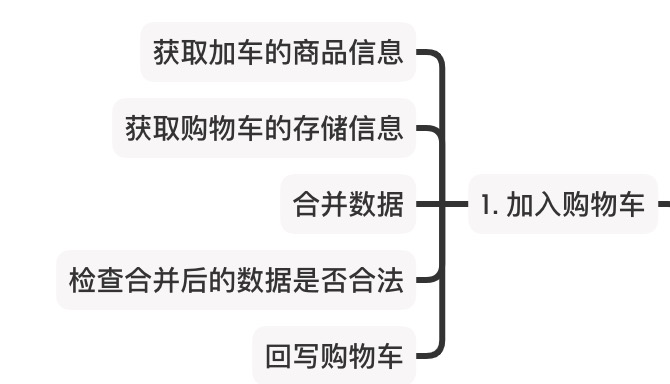
这里有几个取巧的地方,首先是获取商品的逻辑,由于在前面验证的时候也会用到,因此这里前面获取后会通过参数的方式继续往后传递,因此这里不需要在读库或者调用服务来获取;
其次这里需要把当前用户现有购物车数据获取到,然后将添加的这个商品添加进来。这是一个类似合并操作,原来这个商品是存在,相当于数量加一;需要注意这个商品跟现存的商品有没有父子关系,有没有可能加入后改变了某个活动规则,比如:原来买了2个送1个赠品,现在再添加了一个变成3个,送2个赠品;
注意:这里的添加并不是在购物车直接改数量,可能就是在列表、详情页直接添加添加。
通过将合并后的购物车数据,通过营销活动检查确认ok后,直接回写到存储中。
为什么会有合并购物车这个操作?因为一般电商都是准许游客身份进行操作的,因此当用户登录后需要将二者进行合并。
这里的合并很多部分的逻辑是可以与加入购物车复用的逻辑。比如:合并后的数据都需要检查是否合法,然后覆写回存储中。因此大家可以看到这里的关联性。设计的方法在某种程度上要通用。
购物车列表这是一个非常重要的接口,原则上购物车接口会提供两种类型,一种简版,一种完全版本;
简版的列表接口主要是用在类似PC首页右上角之类获取简单信息;完全版本就是在购物车列表中会用到。
在实际实现中,购物车绝不仅仅是一个读取接口那么简单。因为我们都知道不管是商品信息、活动信息都是在不断的发生变化。因此每次的读取接口必然需要检查当前购物车中数据的合法性,然后发现不一致后需要覆写原存储的数据。
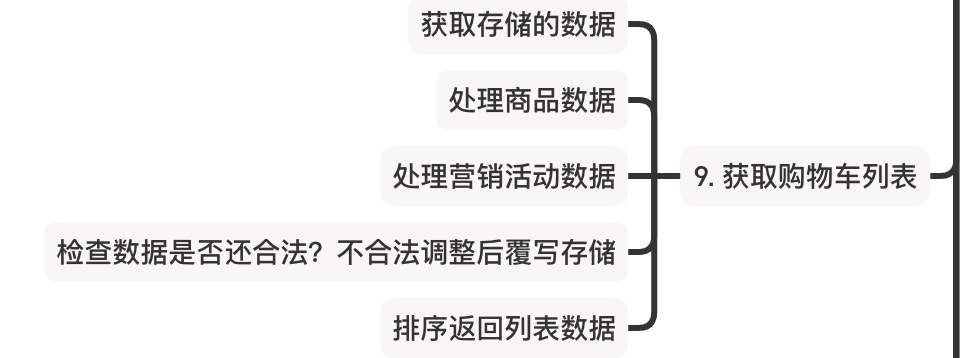
也有一些做法会在每个接口都去检查数据的合法性,我建议为了性能考虑,部分接口可以适当放宽检查,在获取列表时再进行完整的检查。比如添加接口,我只会检测我添加的商品的合法性,绝不会对整个购物车进行检查。因为该操作之后一般都会调用列表操作,那么此时还会进行校验,二者重复操作,因此只取后者。
结算包括两部分,结算页的详情信息与提交订单。结算页可以说是在购物车列表上的一个包装,因为结算页与列表页最大的不同是需要用户选择配送地址(虚拟商品另说),此时会产生更明确的价格信息,其他基本一致。因此在设计购物车列表接口的时候,一定要考虑充分的通用性。
这里另外一个需要注意的是:立即购买,我们也会通过结算页接口来实现,但是内部其实还是会调用添加接口,将商品添加到购物车中;有三个需要注意的地方,首先是这个添加操作是服务内部完成的,对于服务调用方是不需要感知这个加入操作的存在;其次是这个购物车在Redis中的Key是独立于普通购物车的,否则二者的商品耦合在一起非常难于操作处理;最后立即购买的购物车要考虑账号多终端登录的时候,彼此数据不能互相影响,这里可以用每个端的uuid来作为购物车的标记避免这种情况。
购物车的最后一步是生成订单,这一步最要紧的是需要给购物车加锁,避免提交过程中数据被篡改,多说一句,很多人写的Redis分布式锁代码都存在缺陷,大家一定要注意原子性的问题,这类文章网络上很多不再赘述。
加锁成功之后,我们这里有多种做法,一种是按照DB涉及组织数据开始写表,这适用于业务量要求不大,比如订单每秒下单量不超过2000K的;那如果你的系统并发要求非常高怎么办?
其实也很简单,高性能的三大法宝之一:异步;我们提交的时候直接将数据快照写入MQ中,然后通过异步的方式进行消费处理,可以通过通过控制消费者的数量来提升处理能力。这种方法虽然性能提升,但是复杂度也会上升,大家需要根据自己的实际情况来选择。
关于业务架构的设计,到此告一段落,接下来我们来看系统架构。
系统结构主要包含,如何将业务架构映射过来,以及输出对应输入参数、输出参数的说明。由于输入、输出针对各自业务来确定的,而且没有什么难度,我们这里就只说如何将业务架构映射到系统架构,以及系统架构中最核心的Redis数据结构选择以及存储的数据结构设计。
下面的代码目录是按照 Golang 来进行设计的。我们来看看如何将上面的业务架构映射到代码层面来。
├── addproducts.go
├── cartlist.go
├── mergecart.go
├── entity
│ ├── cart
│ │ ├── add.go
│ │ ├── cart.go
│ │ └── list.go
│ ├── order
│ │ ├── checkout.go
│ │ ├── order.go
│ │ └── submit.go
│ └── precart
├── event
│ └── sendorder.go
├── facade
│ ├── activity.go
│ └── product.go
└── repo外层有 entity、event、facade、repo这四个目录,职责如下:
entity: 存放的是我们前面分析的购物领域的三个实体;所有主要的操作都在这三个实体上;
event: 这是用来处理产生的事件,比如刚刚说的如果我们提交订单采用异步的方式,那么该目录就该完成的是如何把数据发送到MQ中去;
facade: 这儿目录是干嘛的呢?这主要是因为我们的服务还需要依赖像商品、营销活动这些服务,那么我们不应该在实体中直接调用它,因为第三方可能存在变动,或者有增加、减少,我们在这里进行以下简单的封装(设计模式中的门面模式);
repo: 这个目录从某种程度上可以理解为 Model层,在整个领域服务中,如果与持久化打交道,都通过它来完成。
最后外层的几个文件,就是我们所提供的领域服务,供应用层来进行调用的。
为了保证内容的紧凑,我这里放弃了对整个微服务的目录介绍,只单独介绍了领域服务,后续会单独成文介绍下微服务的整个系统架构。
通过上面的划分,我们完成了两件事情:
-
业务架构分析的结构在系统代码中都有映射,他们彼此体现。这样最大的好处是,保证设计与代码的一致性,看了文档你就知道对应的代码在哪里;
-
每个目录各自的关注点都进行了分离,更内聚,更容易开发与维护。
现在来看,我们选择Redis作为购物商品数据的存储,我们要解决两个问题,一是我们需要存哪些数据?二是我们用什么结构来存?
网络上很多写购物车的都是只保存一个商品id,真实场景是很难满足需求的。你想想,一个商品id如何记住用户选择的赠品?用户上次选择的活动?以及购买的商品渠道?
综合比较通用的场景,我给出一个参考结构:
// 购物车数据
type ShoppingData struct {
Item []*Item `json:"item"`
UpdateTime int64 `json:"update_time"`
Version int32 `json:"version"`
}
// 单个商品item元素
type Item struct {
ItemId string `json:"item_id"`
ParentItemId string `json:"parent_item_id,omitempty"` // 绑定的父item id
OrderId string `json:"order_id,omitempty"` // 绑定的订单号
Sku int64 `json:"sku"`
Spu int64 `json:"spu"`
Channel string `json:"channel"`
Num int32 `json:"num"`
Status int32 `json:"status"`
TTL int32 `json:"ttl"` // 有效时间
SalePrice float64 `json:"sale_price"` // 记录加车时候的销售价格
SpecialPrice float64 `json:"special_price,omitempty"` // 指定价格加购物车
PostFree bool `json:"post_free,omitempty"` // 是否免邮
Activities []*ItemActivity `json:"activities,omitempty"` // 参加的活动记录
AddTime int64 `json:"add_time"`
UpdateTime int64 `json:"update_time"`
}
// 活动
type ItemActivity struct {
ActID string `json:"act_id"`
ActType string `json:"act_type"`
ActTitle string `json:"act_title"`
}重点说一下 Item 这个结构,item_id 这个字段是标记购物车中某个商品的唯一标记,因为我们之前说过,同一个sku由于渠道不同,那么在购物车中会是两个不同的item;接下来的 parent_item_id 字段是用来标记父子关系的,这里将可能存在的树结构转成了顺序结构,我们不管是父商品还是子商品,都采用顺序存储,然后通过这个字段来进行关联;有些同学可能会奇怪,为什么会存order id这个字段呢?大家关注下自己的日常业务,比如:再来一单、定金预售等,这种一定是与某个订单相关联的,不管是为了资格验证还是数据统计。剩下的字段都是一些非常常规的字段,就不在一一介绍了;
字段的类型,大家根据自己的需要进行修改。
接下来该说怎么选择Redis的存储结构了,Redis常用的 Hash Table、集合、有序集合、链表、字符串 五种,我们一个个来分析。
首先购车一定有一个key来标记这个购物车属于哪个用户的,为了简化,我们的key假设是:uid:cart_type。
我们先来看如果用 Hash Table;我们添加时,需要用到如下命令:HSET uid:cart_type sku ShoppingData;看起来没问题,我们可以根据sku快速定位某个商品然后进行相关的修改等,但是注意,ShoppingData是一个json串,如果用户购物车中有非常多的商品,我们用 HGETALL uid:cart_type 获取到的时间复杂度是O(n),然后代码中还需要一一反序列化,又是O(n)的复杂度。
如果用集合,也会遇到类似的问题,每个购物车看做一个集合,集合中的每个元素是 ShoppingData ,取到代码中依然需要逐一反序列化(反序列化是成本),关于有序集合与链表就不在分析,大家可以按照上面的思路去尝试下问题所在。
看起来我们没得选,只有使用String,那我们来看一下String的契合度是什么样子。首先SET uid:cart_type ShoppingDataArr;我们把购物车所有的数据序列化成一个字符串存储,每次取出来的时间复杂度是O(1),序列化、反序列化都只需要一次。看来是非常不错的选择。但是在使用中大家还是有几点需要注意。
- 单个Value不能太大,要不然就会出现大key问题,所以一般购物车有上限限制,比如item不能超过多少个;
- 对redis的操作性能提升上来了,但是代码的就是修改单个item时的不便,必须每次读取全部然后找到对应的item进行修改;这里我们可以把从redis中的数据读取出来后,在内存中构建一个HashTable,来减少每次遍历的复杂度;
网上也看到很多Redis数据结构组合使用来保存购物车数据的,但是无疑增加了网络开销,相比起来还是String最经济划算。
至此对于购物车的实现设计算是完结了,其中关于订单表的设计会单独放到订单模块去讲。
对于整个购物车服务,虽然没有写的详细到某个具体的接口,但是分析到这一步,我相信大家心中都是有沟壑的,能够结合自己的业务去实现它。
文中有些很有意思的地方,建议大家动手去做做看,有任何问题,我们随时交流。
- 改编版的责任链模式
- Redis的分布式事务锁实现
接下来终于要到订单部分的设计了,希望大家继续关注我们。
今天我们开始「商品系统」的篇章。本文分为如下五大模块:
- 需求分析
- 架构设计
- Spu和Sku的故事
- 数据模型设计
- 接口设计
第一篇我们主要看看一个入门的电商平台(B2C)如何去构建自己的基础商品信息,其实这个事情很简单,想想我们的现实生活,商家摆放商品到货架,客户从货架挑选商品,客户把挑选好的商品放入购物车(篮),最后客户去收银台结账。
对于一个电商平台来讲,我们怎么理解上面的简单示例呢?接着,我们来拆分上面这个简单的事情:
商家摆放商品到货架,客户从货架挑选商品,客户把挑选好的商品放入购物车(篮),最后客户去收银台结账
- 商家是谁:电商平台
- 摆放是什么意思:上架
- 货架在哪:前台系统(web/app/...)
- 挑选:浏览前台系统
- 放入:点击前台系统「加入购物车按钮」
- ...(暂不多说了)
备注:本篇文章主要来看看1、2、3、4步该如何去设计。
通过上面的分析我们可以得出下面的信息:
- 我们需要一个「电商平台」,电商平台里面需要有个商品后台系统。
- 我们上架什么东西呢?商品!所以商品后台系统需要具备创建和发布商品到前台系统的功能。
- 我们需要一个前台系统(比如网页),前台系统具备商品列表和商品详情的页面,可供用户浏览。
- 前台系统的数据怎么来?所以我们需要一个接口网关(对外统一提供服务能力,企业总线)和商品服务
整理之后得到如下的需求点:
| 需求点 | 功能点 | 项目命名 | 技术栈 |
|---|---|---|---|
| 商品后台系统 | 1.创建商品 2.发布商品到前台系统 | Temporal Backend | PHP |
| 前台系统 | 1.商品列表 2.商品详情 | Skr Frontend | Vue |
| 接口网关 | 企业总线 | Skr Gateway | kong |
| 商品服务 | 1.创建商品接口 2.商品状态变更接口 2.商品列表接口 3. 商品详情接口 | Temporal Service | Golang |
通过上面的需求分析,再加上之前的《电商设计手册之用户体系》中的用户体系和《支付开发,不得不了解的国内、国际第三方支付流程》中的支付服务,我们规划出以下的架构图。

对我们程序猿来讲「商品系统」刚开始的样子就是如下三点:
- 创建商品功能:首先我们会有一张商品表,每创建一个商品我们会的到一个goods_id,如果商品存在父子的关系,加一个parent_id的字段就搞定了。
- 商品列表接口:商品表分页查询商品。
- 商品详情接口:商品表按goods_id索引查询商品信息。
很简单是吧,基本一张表就搞定了,看起来也是没什么问题的。但是呢,程序设计的巧妙之处就在于抽象能力,电商行业把goods_id进行了进一步的抽象,产生了Spu和Sku概念,在了解Spu和Sku定义之前,我们还得了解下销售属性的含义,举个例子便于理解:
想想我们的现实生活,假如我们去批发市场上了一批AJ1球鞋,批发商会给我们不同配色、大小的AJ1球鞋。我们在店里销售这些商品时都会询问客户:“您是需要什么颜色和大小的AJ1球鞋呢?”。这里的颜色和大小就是所谓的销售属性,因为不同颜色和大小的AJ1球鞋可能价格不同、库存数量不同,现实生活中是不是如此,不同颜色或大小的AJ1都有差别巨大的价格。
接着,我们来看看Spu和Sku定义:
| 名称 | 概念 | 解释 |
|---|---|---|
| Spu | standard product unit 标准产品单位 | goods_id剥离销售属性的部分,例如:小米8。商品列表我们展示Spu列表。 |
| Sku | stock keeping unit 库存量单位 | 就是你想买的那个商品真正的编号,这个编号对应的库存就是你想买的那个商品的库存量。Spu+一或多个销售属性对应一个Sku,例如:小米8黑128G,其中黑和128G就是销售属性,小米8就是一个Spu。 |
搞清楚了么?
所以最后简单的商品表就拆成了spu表和sku表,接着我们还抽象出来了可复用的销售属性表和销售属性值表。除此之外 我们应该还有品牌表、类别表、简单的sku库存表(目前简单设计此表,后期具体业务重构此表)。接着我们列下这些表的明细:
| 表名称 | 表名 |
|---|---|
| 品牌表 | product_brands |
| 类别表 | product_category |
| spu表 | product_spu |
| sku表 | product_sku |
| 销售属性表 | product_attr |
| 销售属性值 | product_attr_value |
| sku库存表 | product_sku_stock |
除了上面的表之外,我又加了另一张表 关联关系冗余表 product_spu_sku_attr_map,为什么呢?顾名思义,冗余用的,有了这张表,我们可以很高效的得到:
- spu下 有哪些sku
- spu下 有那些销售属性
- spu下 每个销售属性对应的销售属性值(一对多)
- spu下 每个销售属性值对应的sku(一对多)
具体表结构如下所示:
-- 品牌表 product_brands
CREATE TABLE `product_brands` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '品牌ID',
`name` varchar(255) NOT NULL DEFAULT '' COMMENT '品牌名称',
`desc` varchar(255) NOT NULL DEFAULT '' COMMENT '品牌描述',
`logo_url` varchar(255) NOT NULL DEFAULT '' COMMENT '品牌logo图片',
`create_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='品牌表';
-- 类别表 product_category
CREATE TABLE `product_category` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '分类ID',
`pid` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '父ID',
`name` varchar(255) NOT NULL DEFAULT '' COMMENT '分类名称',
`desc` varchar(255) NOT NULL DEFAULT '' COMMENT '分类描述',
`pic_url` varchar(255) NOT NULL DEFAULT '' COMMENT '分类图片',
`path` varchar(255) NOT NULL DEFAULT '' COMMENT '分类地址{pid}-{child_id}-...',
`create_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='类别表';
-- spu表 product_spu
-- spu: standard product unit 标准产品单位
CREATE TABLE `product_spu` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'SPU ID',
`brand_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '品牌ID',
`category_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '分类ID',
`name` varchar(255) NOT NULL DEFAULT '' COMMENT 'spu名称',
`desc` varchar(255) NOT NULL DEFAULT '' COMMENT 'spu描述',
`selling_point` varchar(255) NOT NULL DEFAULT '' COMMENT '卖点',
`unit` varchar(255) NOT NULL DEFAULT '' COMMENT 'spu单位',
`banner_url` text COMMENT 'banner图片 多个图片逗号分隔',
`main_url` text COMMENT '商品介绍主图 多个图片逗号分隔',
`price_fee` int unsigned NOT NULL DEFAULT 0 COMMENT '售价,整数方式保存',
`price_scale` tinyint unsigned NOT NULL DEFAULT 0 COMMENT '售价,金额对应的小数位数',
`market_price_fee` int unsigned NOT NULL DEFAULT 0 COMMENT '市场价,整数方式保存',
`market_price_scale` tinyint unsigned NOT NULL DEFAULT 0 COMMENT '市场价,金额对应的小数位数',
`create_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT AUTO_INCREMENT=666666 CHARSET=utf8mb4 COMMENT='spu表';
-- sku表 product_sku
-- sku: stock keeping unit 库存量单位
CREATE TABLE `product_sku` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'SKU ID',
`spu_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT 'SPU ID',
`attrs` text COMMENT '销售属性值{attr_value_id}-{attr_value_id} 多个销售属性值逗号分隔',
`banner_url` text COMMENT 'banner图片 多个图片逗号分隔',
`main_url` text COMMENT '商品介绍主图 多个图片逗号分隔',
`price_fee` int unsigned NOT NULL DEFAULT 0 COMMENT '售价,整数方式保存',
`price_scale` tinyint unsigned NOT NULL DEFAULT 0 COMMENT '售价,金额对应的小数位数',
`market_price_fee` int unsigned NOT NULL DEFAULT 0 COMMENT '市场价,整数方式保存',
`market_price_scale` tinyint unsigned NOT NULL DEFAULT 0 COMMENT '市场价,金额对应的小数位数',
`create_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT AUTO_INCREMENT=666666 CHARSET=utf8mb4 COMMENT='sku表';
-- 销售属性表 product_attr
CREATE TABLE `product_attr` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '销售属性ID',
`name` varchar(255) NOT NULL DEFAULT '' COMMENT '销售属性名称',
`desc` varchar(255) NOT NULL DEFAULT '' COMMENT '销售属性描述',
`create_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='销售属性表';
-- 销售属性值 product_attr_value
CREATE TABLE `product_attr_value` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '销售属性值ID',
`attr_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '销售属性ID',
`value` varchar(255) NOT NULL DEFAULT '' COMMENT '销售属性值',
`desc` varchar(255) NOT NULL DEFAULT '' COMMENT '销售属性值描述',
`create_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='销售属性值';
-- 关联关系冗余表 product_spu_sku_attr_map
-- 1. spu下 有哪些sku
-- 2. spu下 有那些销售属性
-- 3. spu下 每个销售属性对应的销售属性值(一对多)
-- 4. spu下 每个销售属性值对应的sku(一对多)
CREATE TABLE `product_spu_sku_attr_map` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`spu_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT 'SPU ID',
`sku_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT 'SKU ID',
`attr_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '销售属性ID',
`attr_name` varchar(255) NOT NULL DEFAULT '0' COMMENT '销售属性名称',
`attr_value_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '销售属性值ID',
`attr_value_name` varchar(255) NOT NULL DEFAULT '0' COMMENT '销售属性值',
`create_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`status` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='关联关系冗余表';
-- sku库存表 product_sku_stock
CREATE TABLE `product_sku_stock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`sku_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT 'SKU ID',
`quantity` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '库存',
`create_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '状态 1:enable, 0:disable, -1:deleted',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='sku库存表';
关于接口设计目前很简单,无非列表和详情。但是这里我做了一个很好的设计动静分离,例如库存的动态的数据,单独提供接口,其他列表和详情数据完全静态化,把流量打到CDN去,这里又会说到我们下步计划的基础服务体系里的「静态资源服务」,这个服务的主要功能就是把我们的接口数据静态化。具体的V1.0版的接口设计如下:
1、spu详情 GET {version}/product/spu/{spu_id}
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| spu_id | number | yes | spu ID |
响应内容:
{
"code": "200",
"msg": "OK",
"result": {
"brand_info": {
"id": "number, 品牌ID",
"name": "string, 品牌名称",
"desc": "string, 品牌描述",
"logo_url": "string, 品牌logo图片",
},
"category_info": {
"id": "number, 分类ID",
"name": "string, 品牌名称",
"desc": "string, 品牌描述",
"pic_url": "string, 分类图片",
"path": "string, 分类地址{pid}-{child_id}-...",
},
"spu_info": {
"id": "number, spu id",
"name": "string, spu名称",
"desc": "string, spu描述",
"selling_point": "string, 卖点",
"unit": "string, spu单位",
"banner_url": [
"string, banner 图片url",
"string, banner 图片url",
],
"main_url": [
"string, 商品介绍主图 图片url",
"string, 商品介绍主图 图片url",
],
"price": "string, 售价",
"market_price": "string, 市场价",
"attrs": [ // 有那些销售属性
{
"id": "销售属性ID",
"name": "string, 销售属性名称",
"desc": "string, 销售属性描述",
"values": [ // 每个销售属性对应的销售属性值(一对多)
{
"id": "销售属性值ID",
"name": "string, 销售属性值",
"desc": "string, 销售属性值描述",
// 每个销售属性值对应的sku(一对多)
// 页面初始化时,按钮不可点击逻辑判断: 如果该销售属性值下所有sku没有库存,则该销售属性按钮不可点击
// 选择销售属性值时,按钮不可点击逻辑判断:销售属性构成双向链表,每个销售属性又是一个单向链表存改销售属性对应的所有销售属性值。每当选择一个销售属性值时先前和后一个销售属性遍历,执销售属性值下所有sku售罄的按钮不可点击,且当前销售属性值map记录key为当前点击的销售属性值ID,值统一标示一下就行,目的记录是由于选择了哪个销售属性值使得当前的销售属性值为售罄状态
// 取消选择销售属性值时,按钮不可点击逻辑恢复判断:数据结构同上,遍历,记录的map删除key为当前取消选中的销售属性值,并判断是否还有别的key使得该销售属性值为售罄状态,如果没有则恢复未售罄状态
"skus": [
"number, sku id",
"number, sku id",
],
}
],
}
],
"skus": [ // 有哪些sku
"number, sku id",
"number, sku id",
],
"skus_map": {
"{attr_value_id}-{attr_value_id}-...": "number, sku id",
"{attr_value_id}-{attr_value_id}-...": "number, sku id",
"{attr_value_id}-{attr_value_id}-...": "number, sku id",
"{attr_value_id}-{attr_value_id}-...": "number, sku id",
"{attr_value_id}-{attr_value_id}-...": "number, sku id",
"{attr_value_id}-{attr_value_id}-...": "number, sku id",
}
}
}
}2、获取spu下所有skus库存 GET {version}/stock/spu/{spu_id}
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| spu_id | number | yes | spu ID |
响应内容:
{
"code": "200",
"msg": "OK",
"result": {
"skus_stock": {
"int, sku id": {
"quantity": "int, 剩余库存数量"
}
}
}
}
}3、sku详情 GET {version}/product/sku/{sku_id}
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| sku | number | yes | sku ID |
响应内容:
{
"code": "200",
"msg": "OK",
"result": {
"id": "number, sku id",
"name": "string, sku名称",
"desc": "string, sku描述",
"unit": "string, sku单位",
"banner_url": [
"string, banner 图片url",
"string, banner 图片url",
],
"main_url": [
"string, 商品介绍主图 图片url",
"string, 商品介绍主图 图片url",
],
"price": "string, 售价",
"market_price": "string, 市场价",
}
}4、spu列表 GET {version}/product/spu/list
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| - | - | - | - |
响应内容:
{
"code": "200",
"msg": "OK",
"result": {
"list": [
{
"id": "number, spu id",
"name": "string, spu名称",
"desc": "string, spu描述",
"unit": "string, spu单位",
"banner_url": [
"string, banner 图片url",
"string, banner 图片url",
],
"price": "string, 售价",
"market_price": "string, 市场价",
}
]
}
}营销体系在一个电商系统中承担着尖刀般的作用,为电商团队拼下无数订单,就如同现实生活中的一线销售人员,引流、促销、提高成单率和客单价。
一个营销体系拥有各种提升GMV的手段,并且仍然在不断的推陈出新,着实令人敬佩。
按照不同的维度,我们把营销体系划分为两大系统:
| 系统 | 描述 | 维度 |
|---|---|---|
| 活动营销系统 | 拥有各种手段提升PV\UV,并引导消费 | PV、UV维度 |
| 销售营销系统 | 拥有各种降低或变相降低价格的手段,来促进消费 | 价格维度 |
- 活动营销系统:
- 抽奖
- 按时间抽奖
- 按当前活动参与次数抽奖
- 按数额区间抽奖
- 活动模板
- 抢购???
- 抽奖
- 销售营销系统:
- 满减
- 满赠
- 买送
- 限时购(限时降价或限时折扣)
- 秒杀
- 加价购
- 多买
- 预售
- 全款预售
- 定金(订金)膨胀预售
- 盲售
- 拼团
- 砍价
- 众筹
- 组合套装
- 营销体系的基础服务支撑:
- 优惠券服务
- 满减券
- 折扣券
- 现金券
- 积分服务
- 优惠券服务
营销体系中我们需要把以下概念定义清楚,要使用哪些名词,以及明确其定义,防止沟通过程中的效率低下或理解偏差:
| 概念 | 定义 |
|---|---|
| 抢购 | 爆品/新品发售场景 |
| --- | --- |
| 满减 | 单笔订单满多少减多少,例如,“满500减20” |
| 满赠 | 单笔订单满多少增送其他商品,例如,“满999送秋裤” |
| 买送 | 买就送,例如,“全场下单送秋裤” |
| 限时购 | 限定时间区间,降价或折扣 |
| 秒杀 | 白送价格,数量极少的销售场景,例如,“一元秒杀” |
| 加价购 | 再加多少钱,可以低价购买其他推荐商品 |
| 多买 | 单笔订单购买多个sku,享受折扣 |
| 全款预售 | 预售库存一次付清 |
| 订金膨胀预售 | 包含订金阶段、尾款阶段,订金翻倍抵现尾款,订金可退 |
| 定金膨胀预售 | 包含定金阶段、尾款阶段,定金翻倍抵现尾款,定金不退 |
| 盲售 | 包含订金(定金)阶段,尾款阶段;不知道尾款价格,不知道sku的具体信息,只知道spu的信息(可选) |
| 拼团 | 限定时间凑够多人成功支付订单(享优惠价格) |
| 砍价(点赞降价) | 限定时间邀请好友砍价到指定金额 |
| 众筹 | 限定时间购买人数达到指定人数及以上即可成功享受优惠价格 |
| 组合套装 | 多个sku捆绑销售 |
| --- | --- |
| 满减券 | 单笔订单满多少才能使用的优惠券 |
| 折扣券 | 单笔订单折扣 |
| 现金券 | 单笔订单抵现金 |
首先我们先来回顾下营销体系的组成:
| 营销体系 |
|---|
| 活动营销系统 |
| 销售营销系统 |
今天带来的是活动营销系统下的第一个独立子系统通用抽奖工具的介绍,本篇文章主要分为如下4部分:
- 常见抽奖场景与归类
- 抽奖需求配置
- 常见奖品类型
- 抽奖五要素
下面是我列出来的一些常见的抽奖场景,红包雨、糖果雨、打地鼠、大转盘(九宫格)、考眼力、答题闯关、游戏闯关、支付刮刮乐、积分刮刮乐等等活动营销场景。
| 活动名称 | 描述 |
|---|---|
| 红包雨 | 每日整点抢红包🧧抽奖,每个整点一般可参与一次 |
| 糖果雨 | 每日整点抢糖果🍬抽奖,每个整点一般可参与一次 |
| 打地鼠 | 每日整点打地鼠抽奖,每个整点一般可参与一次 |
| 大转盘(九宫格) | 某个时间段,转盘抽奖,每个场一般可参N次 |
| 考眼力 | 某个时间段,旋转杯子猜小球在哪个被子里,猜对可抽奖,一般每日可参与N次 |
| 答题闯关 | 每过一关,可参与抽奖,越到后面奖品越贵重 |
| 游戏闯关 | 每过一关,可参与抽奖,越到后面奖品越贵重 |
| 支付刮刮乐 | 支付订单后可刮奖,支付金额越大奖品越贵重 |
| 积分刮刮乐 | 积分刮奖,消费积分额度越大奖品越贵重 |
通过上面的活动描述,我们把整个抽奖场景归为以下三类:
| 类型 | 活动名称 | 维度 |
|---|---|---|
| 按时间抽奖 | 红包雨、糖果雨、打地鼠、幸运大转盘(九宫格)、考眼力 | 时间维度 |
| 按抽奖次数抽奖 | 答题闯关、游戏闯关 | 参与该活动次数维度 |
| 按数额范围区间抽奖 | 支付刮刮乐、积分刮刮乐 | 数额区间维度 |
接着我们来看下每类抽奖活动具体的抽奖需求配置。
本小节每类抽奖活动的需求配置,分为如下三个部分:
- 活动配置
- 场次配置
- 奖品配置
| 类型 | 活动名称 | 特点 |
|---|---|---|
| 按时间抽奖 | 红包雨、糖果雨、打地鼠、幸运大转盘(九宫格)、考眼力 | 时间维度 |
| 按时间抽奖 | 是否多场次 | 单场次次数限制(次) | 总场次次数限制(次) |
|---|---|---|---|
| 红包雨 | 是 | 1 | N |
| 糖果雨 | 是 | 1 | N |
| 打地鼠 | 是 | N | N |
| 幸运大转盘(九宫格) | 否 | N | N |
| 考眼力 | 否 | N | N |
通过上面的分析我们得到了活动和场次的概念: 一个活动需要支持多场次的配置。
- 活动activity:配置活动的日期范围
- 场次session:配置每场的具体时间范围
红包雨的需求配置示例:
活动特征:红包雨需要支持多场次。
比如双十二期间三天、每天三场整点红包雨配置如下:
活动、场次配置:
| 双十二红包雨 |
|---|
| 活动配置: |
| 2019-12-10 至 2019-12-12 |
| 场次配置: |
| 10:00:00 至 10:01:00 |
| 12:00:00 至 12:01:00 |
| 18:00:00 至 18:01:00 |
奖品配置:
| 场次 | 奖品1 | 奖品2 | --- | 奖品N |
|---|---|---|---|---|
| 场次10:00:00 至 10:01:00 | 优惠券2元 | 空奖 | --- | 无 |
| 场次12:00:00 至 12:01:00 | 优惠券5元 | 空奖 | --- | 无 |
| 场次18:00:00 至 18:01:00 | 优惠券10元 | 优惠券20元 | --- | 空奖 |
上面配置的结果如下:
2019-12-10日三场整点红包雨:
2019-12-10 10:00:00 ~ 10:01:00
2019-12-10 12:00:00 ~ 12:01:00
2019-12-10 18:00:00 ~ 18:01:00
2019-12-11日三场整点红包雨:
2019-12-11 10:00:00 ~ 10:01:00
2019-12-11 12:00:00 ~ 12:01:00
2019-12-11 18:00:00 ~ 18:01:00
2019-12-12日三场整点红包雨:
2019-12-12 10:00:00 ~ 10:01:00
2019-12-12 12:00:00 ~ 12:01:00
2019-12-12 18:00:00 ~ 18:01:00幸运大转盘的需求配置示例:
活动特征:幸运大转盘不需要多场次。
比如年货节2020-01-20 至 2020-02-10期间幸运大转盘配置如下:
活动、场次配置:
| 双十二幸运大转盘 |
|---|
| 活动配置: |
| 2019-12-10 至 2019-12-12 |
| 场次配置: |
| 00:00:00 至 23:59:59 |
奖品配置:
| 场次 | 奖品1 | 奖品2 | --- | 奖品N |
|---|---|---|---|---|
| 场次00:00:00 至 23:59:59 | 优惠券2元 | 空奖 | --- | 无 |
上面配置的结果如下:
幸运大转盘抽奖活动将于 2019-12-10 00:00:00 ~ 2019-12-12 23:59:59 进行注意与思考:双十二幸运大转盘不需要多个场次,只配置一个场次即可,完全复用活动场次模型。
| 类型 | 活动名称 | 特点 |
|---|---|---|
| 按抽奖次数抽奖 | 答题闯关、游戏闯关 | (成功参与)当前活动次数维度 |
答题闯关的需求配置示例:
活动特征:每一关的奖品不同,一般越到后面中大奖的几率越大。
活动、场次配置:
| 双十二答题闯关 |
|---|
| 活动配置: |
| 2019-12-10 至 2019-12-12 |
| 场次配置: |
| 00:00:00 至 23:59:59 |
奖品配置:
| 双十二答题闯关 | 奖品 |
|---|---|
| 第一关 | 优惠券2元 |
| 第二关 | 优惠券5元 |
| 第三关 | 优惠券10元 |
| 第四关 | 优惠券20元 |
| 第五关 | 优惠券50元 |
| 第六关 | 优惠券100元 |
注意与思考:同理活动&场次配置完全复用,同幸运大转盘配置(不需要支持多场次)。
| 类型 | 活动名称 | 特点 |
|---|---|---|
| 按数额范围区间抽奖 | 支付刮刮乐、积分刮刮乐 | 数额区间维度 |
支付刮刮乐的需求配置示例:
活动特征:不同的订单金额,一般金额越大中大奖的几率越大。
活动、场次配置:
| 双十二答题闯关 |
|---|
| 活动配置: |
| 2019-12-10 至 2019-12-12 |
| 场次配置: |
| 00:00:00 至 23:59:59 |
奖品配置:
| 订单金额 | 奖品1 | 奖品2 | --- | 奖品N |
|---|---|---|---|---|
| 0~100 | 优惠券2元 | 空奖 | --- | 无 |
| 100~200 | 优惠券5元 | 空奖 | --- | 无 |
| 200~1000 | 优惠券10元 | 优惠券20元 | --- | 空奖 |
| 1000以上 | 优惠券50元 | 笔记本电脑 | --- | 空奖 |
注意与思考:同理活动&场次配置完全复用,同幸运大转盘配置(不需要支持多场次)。
总结: 通过上面的分析我们得到了抽奖工具的两个要素活动和场次。
抽奖抽什么?
| 常见奖品类型 |
|---|
| 优惠券 |
| 积分 |
| 实物 |
| 空奖 |
总结: 我们得到了抽奖工具的另一个要素奖品。
通过上面的分析我们已经得到了抽奖的三要素
- 活动
- 场次
- 奖品
那还有什么要素我们还没聊到呢?接下来来看。
抽奖自然离不开奖品的中奖概率的设置。关于中奖概率我们支持如下灵活的配置:
- 手动设置奖品中奖概率
- 自动概率,根据当前奖品的数量、奖品的权重得到中奖概率
比如我们某次大促活动红包雨的配置如下:
| 活动配置 | 描述 |
|---|---|
| 活动时间 | 2019-12-10至2019-12-12 |
| 活动名称 | 2019双十二大促整点红包雨 |
| 活动描述 | 2019双十二大促全端整点红包雨活动 |
| 手动设置奖品概率 | 是 |
| 场次 | 奖品类型 | 具体奖品 | 奖品数量 | 中奖概率 |
|---|---|---|---|---|
| 10:00:00 ~ 10:01:00 | 优惠券 | 2元优惠券 | 2000 | 50% |
| - | 优惠券 | 5元优惠券 | 1000 | 20% |
| - | 空奖 | - | 5000 | 30% |
| 12:00:00 ~ 12:01:00 | 优惠券 | 2元优惠券 | 2000 | 50% |
| - | 优惠券 | 5元优惠券 | 1000 | 20% |
| - | 空奖 | - | 5000 | 30% |
| 18:00:00 ~ 18:01:00 | 优惠券 | 2元优惠券 | 2000 | 50% |
| - | 优惠券 | 5元优惠券 | 1000 | 20% |
| - | 空奖 | - | 5000 | 30% |
备注:每轮场次中奖概率之和必须为100%,否则剩余部分默认添加为空奖的中奖概率。
如何均匀的抽走奖品?
答案: 均匀投奖。
具体方式为拆分总奖品数量,到各个细致具体的时间段。以双十二幸运大转盘为例:
| 场次 | 奖品类型 | 具体奖品 | 奖品数量 | 中奖概率 | 投奖时间(默认提前5分钟投奖) | 投奖数量 |
|---|---|---|---|---|---|---|
| 00:00:00 至 23:59:59 | 优惠券 | 2元优惠券 | 2000 | 50% | - | - |
| - | - | - | - | - | 00:00:00 | 2000 |
| - | - | - | - | - | 06:00:00 | 2000 |
| - | - | - | - | - | 12:00:00 | 2000 |
| - | - | - | - | - | 18:00:00 | 2000 |
这里我们就得到了抽奖的第五个要素:均匀投奖。
通过上面的分析,我们得到抽奖五要素如下:
| 抽奖五要素 | 要素名称 |
|---|---|
| 第一要素 | 活动 |
| 第二要素 | 场次 |
| 第三要素 | 奖品 |
| 第四要素 | 中奖概率 |
| 第五要素 | 均匀投奖 |
同时我们通过抽奖五要素也得到了通用抽奖工具配置一场抽奖活动的5个基本步骤:
- 活动配置
- 场次配置
- 奖品配置
- 奖品中奖概率配置
- 奖品投奖配置
需求已经分析完了,今天我们就来看看这通用抽奖工具具体的设计,分为如下三个部分:
- DB设计
- 配置后台设计
- 接口设计
第一要素活动配置的抽奖活动表:
-- 通用抽奖工具(万能胶Glue) glue_activity 抽奖活动表
CREATE TABLE `glue_activity` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '活动ID',
`serial_no` char(16) unsigned NOT NULL DEFAULT '' COMMENT '活动编号(md5值中间16位)',
`name` varchar(255) NOT NULL DEFAULT '' COMMENT '活动名称',
`description` varchar(255) NOT NULL DEFAULT '' COMMENT '活动描述',
`activity_type` tinyint(1) unsigned NOT NULL DEFAULT '1' COMMENT '活动抽奖类型1: 按时间抽奖 2: 按抽奖次数抽奖 3:按数额范围区间抽奖',
`probability_type` tinyint(1) unsigned NOT NULL DEFAULT '1' COMMENT '中奖概率类型1: static 2: dynamic',
`times_limit` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '抽奖次数限制,0默认不限制',
`start_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '活动开始时间',
`end_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '活动结束时间',
`create_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '状态 -1:deleted, 0:disable, 1:enable',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='抽奖活动表';第二要素场次配置的抽奖场次表:
-- 通用抽奖工具(万能胶Glue) glue_session 抽奖场次表
CREATE TABLE `glue_session` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '场次ID',
`activity_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '活动ID',
`times_limit` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '抽奖次数限制,0默认不限制',
`start_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '场次开始时间',
`end_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '场次结束时间',
`create_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '状态 -1:deleted, 0:disable, 1:enable',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='抽奖场次表';第三、四要素奖品配置的抽奖场次奖品表:
-- 通用抽奖工具(万能胶Glue) glue_session_prizes 抽奖场次奖品表
CREATE TABLE `glue_session_prizes` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`session_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '场次ID',
`node` varchar(255) NOT NULL DEFAULT '' COMMENT '节点标识 按时间抽奖: 空值, 按抽奖次数抽奖: 第几次参与值, 按数额范围区间抽奖: 数额区间上限值',
`prize_type` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '奖品类型 1:优惠券, 2:积分, 3:实物, 4:空奖 ...',
`name` varchar(255) NOT NULL DEFAULT '' COMMENT '奖品名称',
`pic_url` varchar(255) NOT NULL DEFAULT '' COMMENT '奖品图片',
`value` varchar(255) NOT NULL DEFAULT '' COMMENT '奖品抽象值 优惠券:优惠券ID, 积分:积分值, 实物: sku ID',
`probability` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '中奖概率1~100',
`create_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '状态 -1:deleted, 0:disable, 1:enable',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='抽奖场次奖品表';
第五要素均匀投奖的抽奖场次奖品定时投放器表:
-- 通用抽奖工具(万能胶Glue) glue_session_prizes_timer 抽奖场次奖品定时投放器表
CREATE TABLE `glue_session_prizes_timer` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`session_prizes_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '抽奖场次奖品ID',
`delivery_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '定时投放奖品数量的时间',
`prize_quantity` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '奖品数量',
`create_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`create_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建人staff_id',
`update_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
`update_by` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '修改人staff_id',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '状态 -1:deleted, 0:wait, 1:success',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='抽奖场次奖品定时投放器表';
其他表,抽奖记录&奖品发放记录表:
-- 通用抽奖工具(万能胶Glue) glue_user_draw_record 用户抽奖记录表
CREATE TABLE `glue_user_draw_record` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增ID',
`activity_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '活动ID',
`session_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '场次ID',
`prize_type_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '奖品类型ID',
`user_id` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建人user_id',
`create_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`update_at` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
`status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '状态 -1:未中奖, 1:已中奖 , 2: 发奖失败 , 3: 已发奖',
`log` text COMMENT '操作信息等记录',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户抽奖记录表';





- 获取活动信息 GET {version}/glue/activity
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| serial_no | string | Y | 活动编号 |
响应内容:
{
"code": "200",
"msg": "OK",
"result": {
"serial_no": "string, 活动编号",
"type": "number, 活动抽奖类型1: 按时间抽奖 2: 按抽奖次数抽奖 3:按数额范围区间抽奖",
"name": "string, 活动名称",
"description": "string, 活动描述",
"start_time": "number, 活动开始时间",
"end_time": "number, 活动开始时间",
"remaining_times": "number, 活动抽奖次数限制,0不限制",
"sessions_list":[
{
"start_time": "number, 场次开始时间",
"end_time": "number, 场次开始时间",
"remaining_times": "number, 场次抽奖次数限制,0不限制",
"prizes_list": [
{
"name": "string, 奖品名称",
"pic_url": "string, 奖品图片"
}
]
}
]
}
}- 抽奖 POST {version}/glue/activity/draw
请求参数:
| 字段 | 类型 | 是否必传 | 描述 |
|---|---|---|---|
| serial_no | string | Y | 活动编号 |
| uid | number | Y | 用户ID |
响应内容:
// 中奖
{
"code": "200",
"msg": "OK",
"result": {
"serial_no": "string, spu id",
"act_remaining_times": "number, 本活动抽奖剩余次数,0不限制",
"session_remaining_times": "number, 本场次抽奖剩余次数,0不限制",
"prizes_info":
{
"name": "string, 奖品名称",
"pic_url": "string, 奖品图片"
}
}
}
// 未中奖
{
"code": "401",
"msg": "",
"result": {
}
}活动营销系统中的第一个字系统通用抽奖工具今天讲完了,希望对大家有一定的帮助或启示。
本文结构很简单:
5张图送你5种秒杀系统,再加点骚操作,再顺带些点心里话🤷♀️。
实现原理: 通过redis原子操作减库存
图一

| 优点 | 缺点 |
|---|---|
| 简单好用 | 考验redis服务能力 |
| 是否公平 |
|---|
| 公平 |
| 先到先得 |
我们称这类秒杀系统为:
简单秒杀系统
如果刚开始QPS并不高,redis完全抗的下来的情况,完全可以依赖这个「简单秒杀系统」。
实现原理: 服务内存限流算法 + redis原子操作减库存
图二

| 优点 | 缺点 |
|---|---|
| 简单好用 | - |
| 是否公平 |
|---|
| 不是很公平 |
| 相对的先到先得 |
我们称这类秒杀系统为:
够用秒杀系统
实现原理: 服务本地内存原子操作减库存
服务本地内存的库存怎么来的?
活动开始前分配好每台机器的库存,推送到机器上。
图三

| 优点 | 缺点 |
|---|---|
| 高性能 | 不支持动态伸缩容(活动进行期间),因为库存是活动开始前分配好的 |
| 释放redis压力 | - |
| 是否公平 |
|---|
| 不是很公平 |
| 不是绝对的先到先得 |
我们称这类秒杀系统为:
预备库存秒杀系统
实现原理: 服务本地协程Coroutine定时redis原子操作减部分库存到本地内存 + 服务本地内存原子操作减库存
图四

| 优点 | 缺点 |
|---|---|
| 高性能 | 支持动态伸缩容(活动进行期间) |
| 释放redis压力 | - |
| 具备通用性 | - |
| 是否公平 |
|---|
| 不是很公平,但是好了点 |
| 几乎先到先得 |
我们称这类秒杀系统为:
实时预备库存秒杀系统
实现原理: 服务本地Goroutine定时同步是否售罄到本地内存 + 队列 + 排队成功轮训(或主动Push)结果
图五

| 优点 | 缺点 |
|---|---|
| 高性能 | 开发成本高(需主动通知或轮训排队结果) |
| 真公平 | - |
| 具备通用性 | - |
| 是否公平 |
|---|
| 很公平 |
| 绝对的先到先得 |
我们称这类秒杀系统为:
公平排队秒杀系统
上面的秒杀系统还不够完美吗?
答案:是的。
还有什么优化的空间?
答案:静态化获取秒杀活动信息的接口。
静态化是什么意思?
答案:比如获取秒杀活动信息是通过接口 https://seckill.skrshop.tech/v1/acticity/get 获取的。现在呢,我们需要通过https://static-api.skrshop.tech/seckill/v1/acticity/get 这个接口获取。有什么区别呢?看下面:
| 服务名 | 接口 | 数据存储位置 |
|---|---|---|
| 秒杀服务 | https://seckill.skrshop.tech/v1/acticity/get | 秒杀服务内存或redis等 |
| 接口静态化服务 | https://static-api.skrshop.tech/seckill/v1/acticity/get | CDN、本地文件 |
以前是这样

变成了这样

结果:可以通过接口https://static-api.skrshop.tech/seckill/v1/acticity/get就获取到了秒杀活动信息,流量都分摊到了cdn,秒杀服务自身没了这部分的负载。
小声点说:“秒杀结果我也敢推CDN😏😏😏。”
备注:
之后我们会分享`如何用Golang设计一个好用的「接口静态化服务」`。
上面我们得到了如下几类秒杀系统
| 秒杀系统 |
|---|
| 简单秒杀系统 |
| 够用秒杀系统 |
| 预备库存秒杀系统 |
| 实时预备库存秒杀系统 |
| 公平排队秒杀系统 |
我想说的是里面没有最好的方案,也没有最坏的方案,只有适合你的。
拿先到先得来说,一定要看你们的产品对外宣传,切勿上来就追逐绝对的先到先得。其实你看所有的方案,相对而言都是“先到先得”,比如,活动开始一个小时了你再来抢,那相对于准时的用户自然抢不过,对吧。
又如预备库存秒杀系统,虽然不支持动态伸缩容。但是如果你的环境满足如下任意条件,就完全够用了。
- 秒杀场景结束时间之快,通常几秒就结束了,真实活动可能会发生如下情况:
- 服务压力大还没挂:根本就来不及动态伸缩容
- 服务压力大已经挂了:可以先暂停活动,服务起来&扩容结束,用剩余库存重新推送
- 运维自身不具备动态伸缩容的能力
所以:
合适好用就行,切勿过度设计。
进入正题,营销体系的基础服务「优惠券服务」。通过如下问题来介绍优惠券:
- 优惠券有哪些类型?
- 优惠券有哪些适用范围?
- 优惠券有哪些常见的场景?
- 优惠券服务要有哪些服务能力?
- 优惠券服务的风控怎么做?
对于获取优惠券的用户而言:关注的是优惠券的优惠能力,所以按优惠能力维度优惠券主要分为下面三类:
| 优惠能力维度 | 描述 |
|---|---|
| 满减券 | 满多少金额(不含邮费)可以减多少金额 |
| 现金券 | 抵扣多少现金(无门槛) |
| 抵扣券 | 抵扣某Sku全部金额(一个数量) |
| 折扣券 | 打折 |
对于发放优惠券的运营人员而言:
一种是「固定有效期」,优惠券的生效时间戳和过期时间戳,在创建优惠券的时候已经确定。用户在任意时间领取该券,该券的有效时间都是之前设置的有效时间的开始结束时间。
另一种是「动态有效期」,创建优惠券设置的是有效时间段,比如7天有效时间、12小时有效时间等。这类优惠券以用户领取优惠券的时间为优惠券的有效时间的开始时间,以以用户领取优惠券的时间+有效时间为有效时间的结束时间。
| 有效期维度 | 优惠券类型 | 优惠券生效时间 | 优惠券失效时间 | 描述 |
|---|---|---|---|---|
| 固定 | 固定有效期 | 优惠券类型被创建时已确定 | 优惠券类型被创建时已确定 | 无论用户什么时间领取该优惠券,优惠券生效的时间都是设置好的统一时间 |
| 动态 | 动态有效期 | 用户领取优惠券时,当前时间戳 | 用户领取优惠券时,当前时间戳 + N*24*60*60 | 优惠券类型被创建时,只确定了该优惠券的有效,例如6小时、7天、一个月 |
小结如下:

| 运营策略 | 描述 |
|---|---|
| (非)指定Sku | Sku券 |
| (非)指定Spu | Spu券 |
| (非)指定类别 | 类别券 |
| 指定店铺 | 店铺券 |
| 全场通用 | 平台券 |
| 适用终端(复选框) | 描述 |
|---|---|
| �A�ndroid | 安卓端 |
| iOS | iOS端 |
| PC | 网页电脑端 |
| Mobile | 网页手机端 |
| 微信端 | |
| 微信小程序 | 微信小程序 |
| All | 以上所有 |
| 适用人群 | 描述 |
|---|---|
| 白名单 | 测试用户 |
| 会员 | 会员专属 |
小结如下:

| 领取优惠券场景 | 描述 |
|---|---|
| 活动页面 | 大促、节假日活动页面展示获取优惠券的按钮 |
| 游戏页面 | 通过游戏获取优惠券 |
| 店铺首页 | 店铺首页展示领券入口 |
| 商品详情 | 商品详情页面展示领券入口 |
| 积分中心 | 积分兑换优惠券 |
| 展示优惠券场景 | 描述 |
|---|---|
| 活动页面 | 大促、节假日活动页面展示可以领取的优惠券 |
| 商品详情 | 商品详情页面展示可以领取、可以使用的优惠券列表 |
| 个人中心-我的优惠券 | 我的优惠券列表 |
| 订单结算页面 | 结算页面,适用该订单的优惠券列表以及推荐 |
| 积分中心 | 展示可以兑换的优惠券详情 |
| 选择优惠券场景 | 描述 |
|---|---|
| 商品详情 | 商品详情页面展示该用户已有的,且适用于该商品的优惠券 |
| 订单结算页面-优惠券列表 | 选择可用优惠券结算 |
| 订单结算页面-输入优惠码 | 输入优惠码结算 |
| 返还优惠券场景 | 描述 |
|---|---|
| 未支付订单取消 | 未支付的订单,用户主动取消返还优惠券,或超时关单返还优惠券 |
| 已支付订单全款取消 | 已支付的订单,订单部分退款不返还,当整个订单全部退款返还优惠券 |
| 场景示例 | 描述 |
|---|---|
| 活动页领券 | 大促、节假日活动页面展示获取优惠券的按钮 |
| 游戏发券 | 游戏奖励 |
| 商品页领券 | - |
| 店铺页领券 | - |
| 购物返券 | 购买某个Sku,订单妥投后发放优惠券 |
| 新用户发券 | 新用户注册发放优惠券 |
| 积分兑券 | 积分换取优惠券 |
小结如下:

| 发放方式 | 描述 |
|---|---|
| 同步发放 | 适用于用户点击领券等实时性要求较高的获取券场景 |
| 异步发放 | 适用于实时性要求不高的发放券场景,比如新用户注册发券等场景 |
| 发放能力 | 描述 |
|---|---|
| 单张发放 | 指定一个优惠券类型ID,且指定一个UID只发一张该券 |
| 批量发放 | 指定一个优惠券类型ID,且指定一批UID,每个UID只发一张该券 |
| 发放类型 | 描述 |
|---|---|
| 优惠券类型标识 | 通过该优惠券类型的身份标识发放,比如创建一个优惠券类型时会生成一个16位标识码,用户通过16位标识码领取优惠券;这里不使用自增ID(避免对外泄露历史创建了的优惠券数量), |
| 优惠码code | 创建一个优惠券类型时,运营人员会给该券填写一个6位左右的Ascall码,比如SK�R6a6,用户通过该码领取优惠券 |
| 撤销能力 | 描述 |
|---|---|
| 单张撤销 | 指定一个优惠券类型ID,且指定一个UID只撤销一张该券 |
| 批量撤销 | 指定一个优惠券类型ID,且指定一批UID,每个UID撤销一张该券 |
| 用户优惠券列表 | 子类 | 描述 |
|---|---|---|
| 全部 | - | 查询该用户所有的优惠券 |
| 可以使用 | 全部 | 查询该用户所有可以使用的优惠券 |
| - | 适用于某个spu或sku | 查询该用户适用于某个spu或sku可以使用的优惠券 |
| - | 适用于某个类别 | 查询该用户适用于某个类别可以使用的优惠券 |
| - | 适用于某个店铺 | 查询该用户适用于某个店铺可以使用的优惠券 |
| 无效 | 全部 | 查询该用户所有无效的优惠券 |
| - | 过期 | 查询该用户所有过期的优惠券 |
| - | 失效 | 查询该用户所有失效的优惠券 |
订单结算页面推荐一张最适合该订单的优惠券
小结如下:

一旦有发生风险的可能则触发风控:
- 对用户,提示稍后再试或联系客服
- 对内部,报警提示,核查校验报警是否存在问题
| 领取 | 描述 |
|---|---|
| 设备ID | 每天领取某优惠券的个数限制 |
| UID | 每天领取某优惠券的个数限制 |
| IP | 每天领取某优惠券的个数限制 |
| 使用 | 描述 |
|---|---|
| 设备ID | 每天使用某优惠券的个数限制 |
| UID | 每天使用某优惠券的个数限制 |
| IP | 每天使用某优惠券的个数限制 |
| 手机号 | 每天使用某优惠券的个数限制 |
| 邮编 | 比如注重邮编的海外地区,每天使用某优惠券的个数限制 |
依托用户历史订单数据,得到用户成功完成交易(比如成功妥投15天+)的比率,根据此比率对用户进行等级划分,高等级进入通行Unblock名单,低等级进入Block名单,根据不同用户级别设置限制策略。等其他大数据分析手段。
- 发券预算
- 实际使用券预算
根据预算值设置发券总数阈值,当触发阈值时阻断并报警。
优惠券尽量不要支持虚拟商品以防止可能被利用的不法活动。

这几年的工作中一直与支付打交到,借着 skr-shop 这个项目来与大家一起分享探索一下支付系统该怎么设计、怎么做。我们先从支付的一些常见流程出发分析,找出这些支付的共性,抽象后再去探讨具体的数据库设计、代码结构设计。
相关项目:
支付整体而言的一个流程是:给第三方发起了一笔交易,用户通过第三方完成支付,第三方告诉我支付成功,我把用户购买的产品给用户。
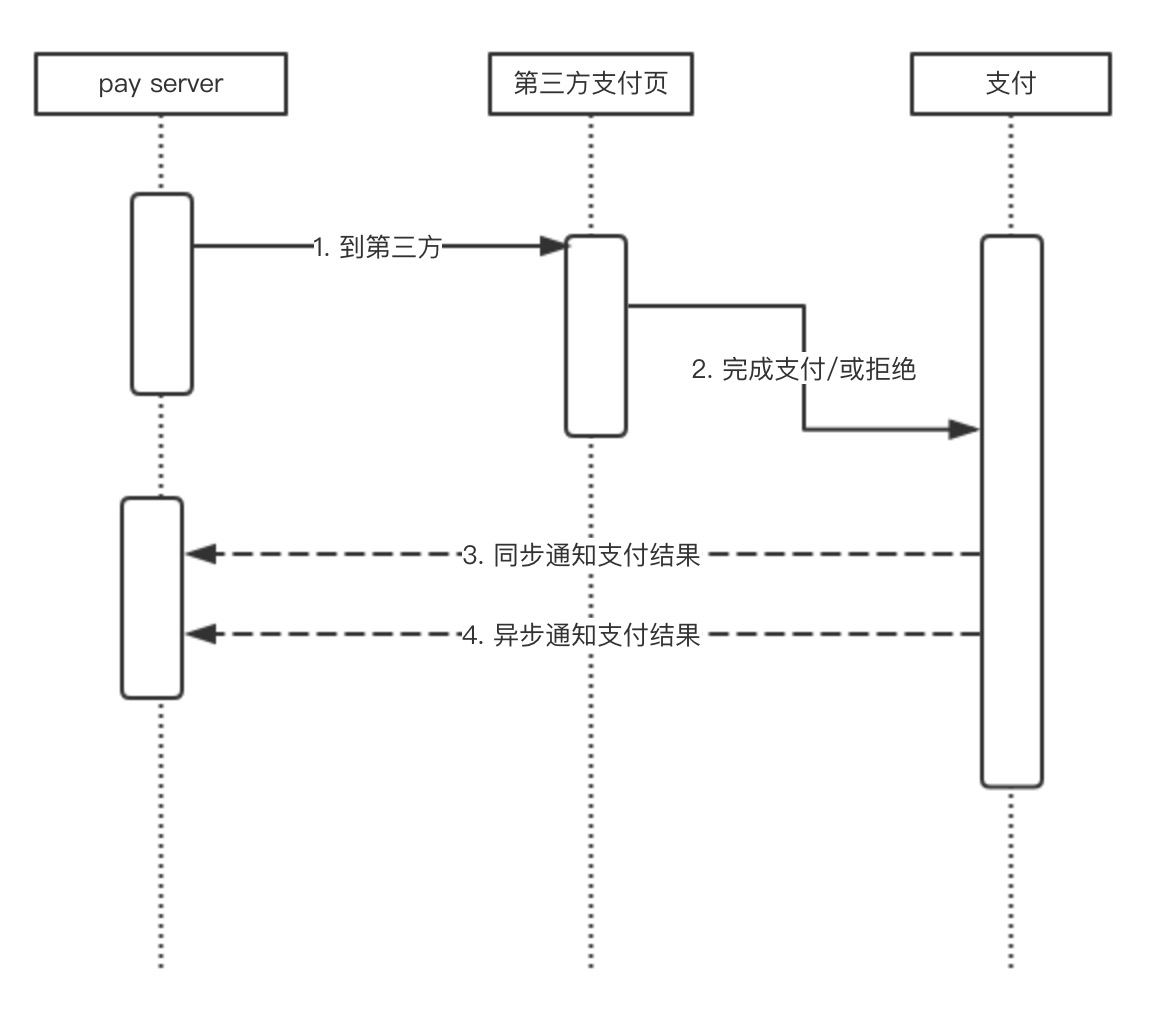
看似简单的流程,这里边不同的支付机构却有不同的处理。下面以我接触过的一些支付来总结一下
国内的典型支付代表是:支付宝、微信、银行(以招商银行为例),由于国内的支付都支持多种渠道的支付方式,为了描述简单,我们均以pc上的支付为例进行讲解。
支付宝的接入是我觉得最简单的一种支付。对于在PC上的支付能力,支付宝提供了【电脑支付】。当用户下单后,商户系统根据支付宝的规则构建好一个url,用户跳转到这个url后进入到支付宝的支付页面,然后完成支付流程。
在支付成功后,支付宝会通过 同步通知、异步通知 两种方式告诉商户系统支付成功,并且两种通知方式的结果都是可信的,而且异步通知的消息延迟也非常短暂。
对于退款流程,支付宝支持全额、部分退款。并且能够根据商户的退款单号区分是否是同一笔退款进而避免了重复退款的可能。支付的退款是调用后同步返回结果,不会异步通知。
微信并没有提供真的PC支付能力,但是我们可以利用【扫码支付】来达成电脑支付的目的。扫码支付有两种模式,这里以模式二为例。
微信调用下单接口获取到这个二维码链接,然后用户扫码后,进入支付流程。完成支付后微信会 异步通知,但是这里并没有 同步通知,因此前端页面只能通过定时轮训的方式检查这笔交易是否支付,直到查询到成功、或者用户主动关闭页面。
退款流程与支付宝最大的不同是,有一个 异步通知 需要商户系统进行处理。
第一个不同点:
- 异步通知的接口需要处理多种不同类型的异步消息
随着在线支付在国内的蓬勃发展,各家银行也是不断推出自己的在线支付能力。其中的佼佼者当属 招商银行。大家经常用的滴滴上面就有该支付方式,可以体验一下。
招商支付使用的是银行卡,因此首次用户必须进行绑卡。因此这里可能就多了一个流程,首先得记录用户是否绑过卡,然后用于签名的公钥会发生变化,需要定期更新。
招商所有平台的支付体验都是一致的,会跳转到招行的H5页面完成逻辑,支付成功后并不会自动跳回商户,也就是没有 同步通知,它的支付结果只会走异步通知流程,延迟非常短暂。
退款流程与支付宝一样,也是同步返回退款结果,没有异步通知。
第二个不同点:
- 支付前需要检查用户是否签约过,有签约流程
国内在线支付流程相对都比较完善,接入起来也非常容易。需要注意的一点是:退款后之前支付的单子依然是支付成功状态,并不会变成退款状态。因为退款与支付属于不同的交易。
这一点基本上是国内在线支付的通用做法。
国际支付的平台非常多,包括像支付宝、微信也在扩展这一块市场。我以我接触的几家支付做一个简单的总结。
这是比较出名的一家国际支付公司,它主要做的是银行卡支付,公司在英国
支付流程上,也是根据规则构建好请求的url后,直接跳转到 WorldPay 的页面,通过信用卡完成支付。这里比较麻烦的处理机制是:支付成功后,他首次给你的异步/同步消息通知并不能作为支付成功的依据。真的从银行确认划款成功后,才会给出真的支付成功通知。这中间还可能会异步通知告诉你支付请求被拒绝。最头痛的是不同状态的异步消息时间间隔都是按照分钟以上级别的延迟来计算
退款流程上,状态跟微信一样,需要通过异步消息来确认退款状态。其次它的不同点在于无法根据商户退款单号来确认是否已经发起过退款,因此对于它来说只要请求一次退款接口,那它就默认发起了一次退款。
第三、四不同点:
支付成功后的通知状态有多种,涉及到商户系统业务流程的特殊处理
退款不支持商户退款单号,无法支持防重复退款需要商户自己处理
这是俄罗斯的一家支付公司,这也是一家搞死人不偿命的公司,看下面介绍
它的支付发起是需要构建一个form表单,向它post支付相关的数据。成功后会跳转到它的支付页,用户完成支付即可。对于 同步通知,它需要用户手动触发跳回商户,与招商的逻辑很像,同步也仅仅是做返回并不会真的告知支付结果。异步通知 才是真的告知支付状态。比较恶心的是,支付时必须传入指定格式的商品信息,这会在部分退款时用到。
现在来说退款,退款也是与 WorldPay 一样,不支持商户的退款单号,因此防重方面也许自己的系统进行设计。并且如果是部分退款,需要传入指定的退款商品,这就会出现一个非常尴尬的局面:部分退款的金额与任何一个商品金额都对应不上,退款则会失败。
第五个不同点:
- 部分退款时需要传入部分退款的商品信息,并且金额要一致
接下来再来聊聊印尼的这家支付机构 doku。由于印尼这个国家信用卡的普及程度并不高,它的在线支付提供一种超商支付方式。
什么是超商支付呢?也就是用户在网络上完成下单后,会获取到一个二维码或者条形码。用户拿着这个条形码到超商(711、全家这种)通过收银员扫码,付现金给超商,完成支付流程。
这种方式带来的问题是,用户长时间不去支付,导致订单超时关单后才去付款。对整个业务流程以及用户体验带来很多伤害。
再来说退款,由于存在超商这种支付方式,导致这种支付无法支持在线自动退款,需要人工收集用户银行卡信息,然后完成转账操作。非常痛苦不堪。
第六个不同点:
- 线上没有付款,只有获取付款码,退款需要通过人工操作
亚马逊出品,与支付宝非常类似。提供的是集成式的钱包流程。
支付时直接构建一个url,然后跳转到亚马逊即可完成支付。它还提供一种授权模式,能够不用跳转amazon,再商户端即完成支付。
支付成功后也会同步跳转,同步通知 的内容可以作为支付是否成功的判断依据。经过实际检查 异步通知 的到达会稍有延迟,大概10s以内。
退款方面也支持商户退款单号可以依赖此进行防重。但是退款的状态也是基于异步来的。
这其中还有一些国际支付,如:PayPal、GooglePay、PayTM 等知名支付机构没有进行介绍,是因为基本它们的流程也都在上面的模式之中。我们后续的代码结构设计、数据库设计都基于满足上面的各种支付模型来完成设计。
最后,赠送大家一副脑图,这是接入一家支付时必须弄清楚的问题清单
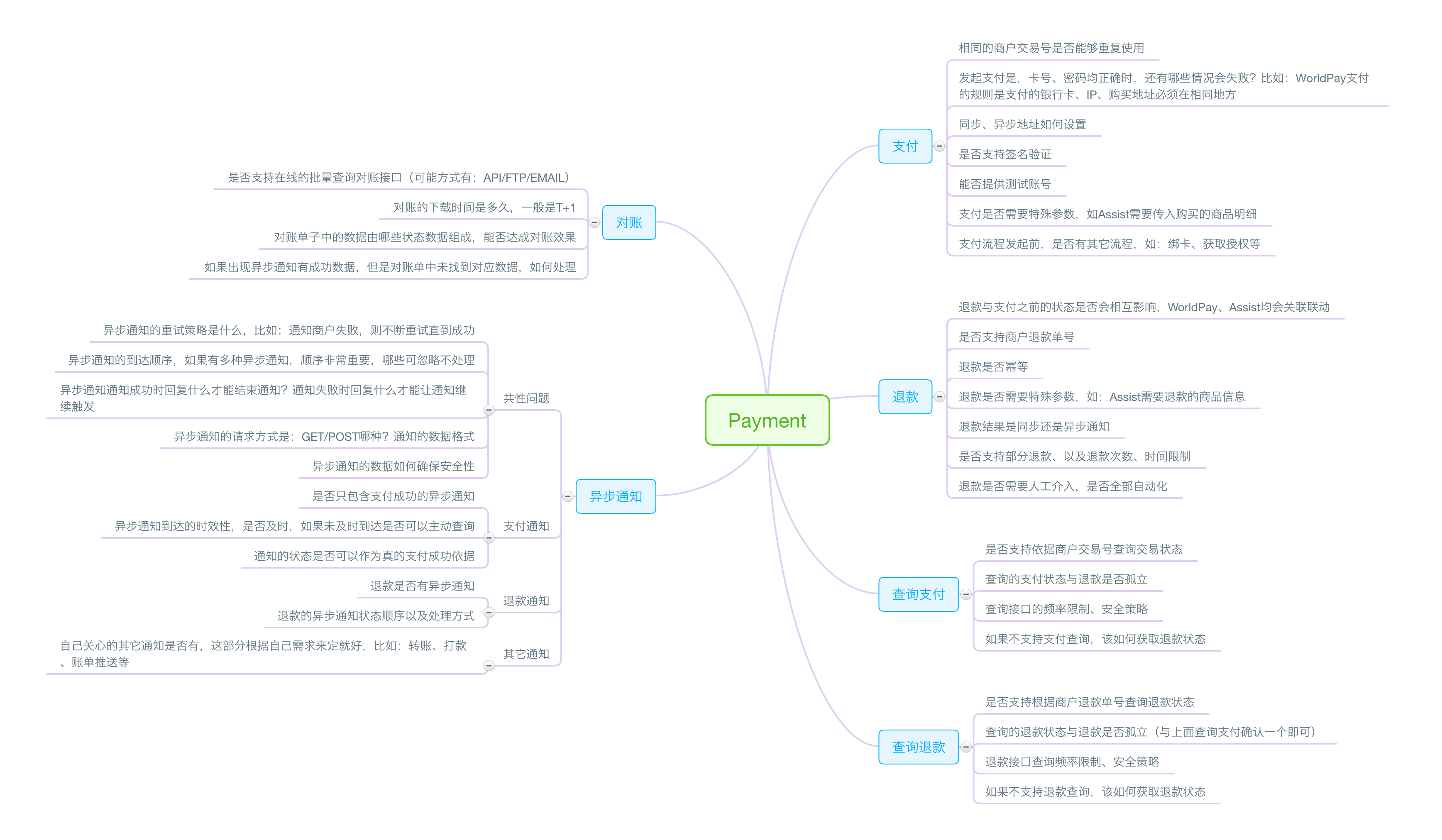
文中我们从严谨的角度一步步聊到支付如何演变成独立的系统。内容包括:系统演进过程、接口设计、数据库设计以及代码如何组织的示例。若有不足之处,欢迎讨论共同学习。
我记得最开始工作的时候,所有的功能:加购物车/下单/支付 等逻辑都是放在一个项目里。如果一个新的项目需要某个功能,就把这个部分的功能包拷贝到新的项目。数据库也原封不动的拷贝过来,稍微根据需求改改。
这就是所谓的 单体应用 时代,随着公司产品线开始多元,每条产品线都需要用到支付服务。如果支付模块调整了代码,那么就会处处改动、处处测试。另一方面公司的交易数据割裂在不同的系统中,无法有效汇总统一分析、管理。
这时就到了系统演进的时候,我们把每个产品线的支付模块抽离成统一的服务。对自己公司内部提供统一的API使用,可以对这些API进一步包装成对应的SDK,供内部业务线快速接入。这里服务使用HTTP或者是RPC协议都可以根据公司实际情况决定。不过如果考虑到未来给第三方使用,建议使用HTTP协议,
系统的演变过程:
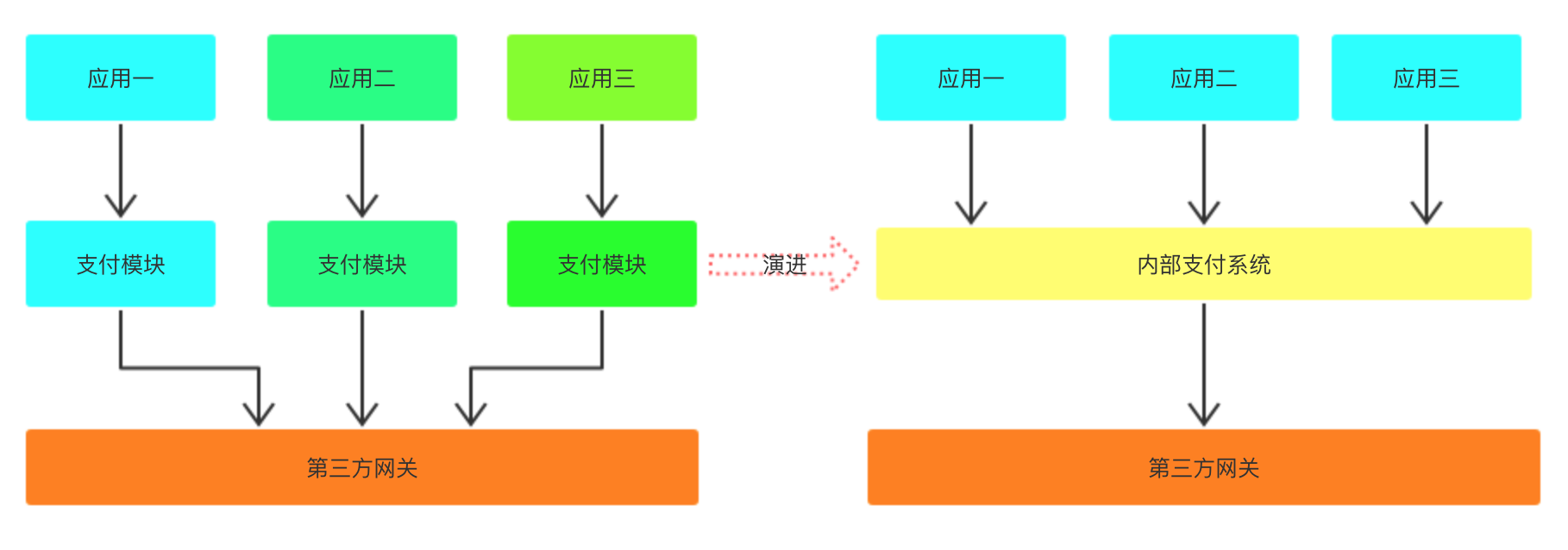
总结下,将支付单独抽离成服务后,带来好处如下:
- 避免重复开发,数据隔离的现象出现;
- 支付系统周边功能演进更容易,整个系统更完善丰满。如:对账系统、实时交易数据展示;
- 随时可对外开发,对外输出Paas能力,成为有收入的项目;
- 专门的团队进行维护,系统更有机会演进成顶级系统;
- 公司重要账号信息保存一处,风险更小。
如果我们接手该需求,需要为公司从零搭建支付系统。我们该从哪些方面入手?这样的系统到底需要具备什么样的能力呢?
首先支付系统我们可以理解成是一个适配器。他需要把很多第三方的接口进行统一的整合封装后,对内部提供统一的接口,减少内部接入的成本。做为一个最基本的支付系统。需要对内提供如下接口出来:
- 发起支付,我们取名:
/gopay - 发起退款,我们取名:
/refund - 接口异步通知,我们取名:
/notify/支付渠道/商户交易号 - 接口同步通知,我们取名:
/return/支付渠道/商户交易号 - 交易查询,我们取名:
/query/trade - 退款查询,我们取名:
/query/refund - 账单获取,我们取名:
/query/bill - 结算明细,我们取名:
/query/settle
一个基础的支付系统,上面8个接口是肯定需要提供的(这里忽略某些支付中的转账、绑卡等接口)。现在我们来基于这些接口看看都有哪些系统会用到。
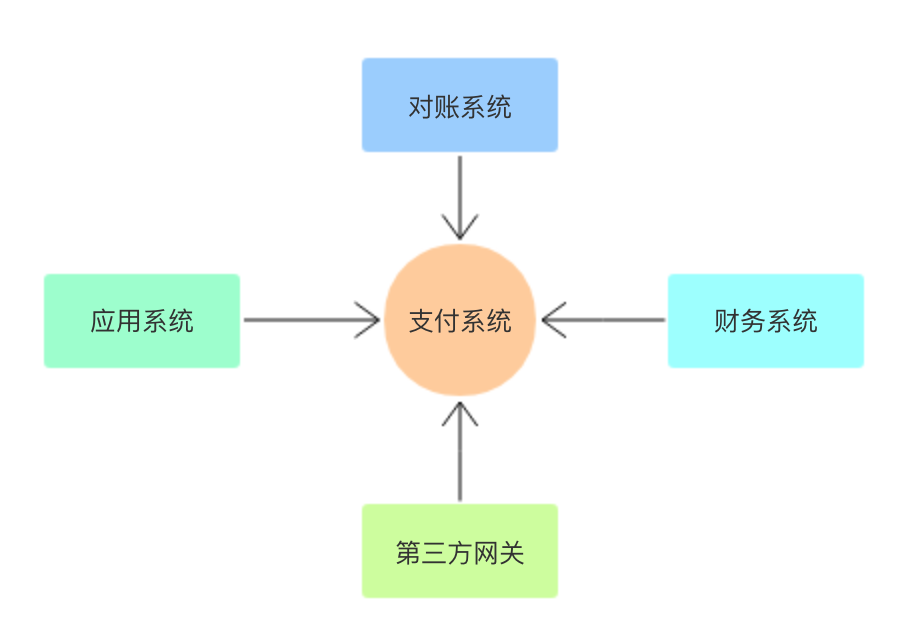
下面按照系统维度,介绍下这些接口如何使用,以及内部的一些逻辑。
一般支付网关会提供两种方式让应用系统接入:
- 网关模式,也就是应用系统自己需要开发一个收银台;(适合提供给第三方)
- 收银台模式,应用系统直接打开支付网关的统一收银台。(内部业务)
下面为了讲清楚设计思路,我们按照 网关模式 进行讲解。
对于应用系统它需要能够请求支付,也就是调用 gopay 接口。这个接口会处理商户的数据,完成后会调用第三方网关接口,并将返回结果统一处理后返回给应用方。
这里需要注意,第三方针对支付接口根据我的经验大致有以下情况:
- 支付时,不需要调用第三方,按照规则生成数据即可;
- 支付时,需要调用第三方多个接口完成逻辑(这可能比较慢,大型活动时需要考虑限流/降配);
- 返回的数据是一个url,可直接跳转到第三方完成支付(wap/pc站);
- 返回的数据是xml/json结构,需要拼装或作为参数传给她的sdk(app)。
这里由于第三方返回结构的不统一,我们需要统一处理成统一格式,返回给商户端。我推荐使用json格式。
{
"errno":0,
"msg":"ok",
"data":{
}
}我们把所有的变化封装在 data 结构中。举个例子,如果返回的一个url。只需要应用程序发起 GET 请求。我们可以这样返回:
{
"errno":0,
"msg":"ok",
"data":{
"url":"xxxxx",
"method":"GET"
}
}如果是返回的结构,需要应用程序直接发起 POST 请求。我们可以这样返回:
{
"errno":1,
"msg":"ok",
"data":{
"from":"<form action="xxx" method="POST">xxxxx</form>",
"method":"POST"
}
}这里的 form 字段,生成了一个form表单,应用程序拿到后可直接显示然后自动提交。当然封装成 from表单这一步也可以放在商户端进行。
上面的数据格式仅仅是一个参考。大家可根据自己的需求进行调整。
一般应用系统除了会调用发起支付的接口外,可能还需要调用 支付结果查询接口。当然大多数情况下不需要调用,应用系统对交易的状态只应该依赖自己的系统状态。
对于对账,一般分为两个类型:交易对账 与 结算对账
交易对账的核心点是:检查每一笔交易是否正确。它主要目的是看我们系统中的每一笔交易与第三方的每一笔交易是否一致。
这个检查逻辑很简单,对两份账单数据进行比较。它主要是使用 /query/bill 接口,拿到在第三方那边完成的交易数据。然后跟我方的交易成功数据进行比较。检查是否存在误差。
这个逻辑非常简单,但是有几点需要大家注意:
- 我方的数据需要正常支付数据+重复支付数据的总和;
- 对账检查不成功主要包括:金额不对、第三方没有找到对应的交易数据、我方不存在对应的交易数据。
针对这些情况都需要有对应的处理手段进行处理。在我的经验中上面的情况都有过遇到。
金额不对:主要是由于第三方的问题,可能是系统升级故障、可能是账单接口金额错误;
第三方无交易数据: 可能是拉去的账单时间维度问题(比如存在时差),这种时区问题需要自己跟第三方确认找到对应的时间差。也可能是被攻击,有人冒充第三方异步通知(说明系统校验机制又问题或者密钥泄漏了)。
自己系统无交易数据: 这种原因可能是第三方通知未发出或者未正确处理导致的。
上面这些问题的处理绝大部份都可以依赖 query/trade query/refund 来完成自动化处理。
那么有了上面的 交易对账 为什么还需要 结算对账 呢?这个系统又是干嘛的?先来看下结算的含义。
结算,就是第三方网关在固定时间点,将T+x或其它约定时间的金额,汇款到公司账号。
下面我们假设结算周期是: T+1。结算对账主要使用到的接口是 /query/settle,这个接口获取的主要内容是:每一笔结算的款项都是由哪些笔交易组成(交易成功与退款数据)。以及本次结算扣除多少手续费用。
它的逻辑其实也很简单。我们先从自己的系统按照 T+1 的结算周期,计算出对方应该汇款给我们多少金额。然后与刚刚接口获取到的数据金额比较:
银行收款金额 + 手续费 = 我方系统计算的金额
这一步检查通过后,说明金额没有问题。接下来需要检查本次结算下的每一笔订单是否一致。
结算系统是 强依赖 对账系统的。如果对账发现异常,那么结算金额肯定会出现异常。另外结算需要注意的一些问题是:
- 银行可能会自行退款给用户,因为用户可直接向自己发卡行申请退款;
- 结算也存在时区差问题;
- 结算接口中的明细交易状态与我方并不完全一致。比如:银行结算时发现某笔退款完成,但我方系统在进行比较时按照未退款完成的逻辑在处理。
针对上面的问题,大家根据自己的业务需求需要做一些方案来进行自动化处理。
财务系统有很多内部业务,我这里只聊与支付系统相关的。(当然上面的对账系统也可以算是财务范畴)。
财务系统与支付主要的一个关系点在于校验交易、以及退款。这里校验交易可以使用 query/trade query/refund这两个接口来完成。这个逻辑过程就不需要说了。下面重点说下退款。
我看到很多的系统退款是直接放在了应用里边,用户申请退款直接就调用退款接口进行退款。这样的风险非常高。支付系统的关于资金流向的接口一定要慎重,不能过多的直接暴露给外部,带来风险。
退款的功能应该是放到财务系统来做。这样可以走内部的审批流程(是否需要根据业务来),并且在财务系统中可以进行更多检查来觉得是否立即进行退款,或者进入等待、拒绝等流程。
针对第三方主要使用到的其实就是异步通知与同步通知两个接口。这一部分的逻辑其实非常简单。就是根据第三方的通知完成交易状态的变更。以及通知到自己对应的应用系统。
这部分比较复杂的是,第三方的通知数据结构不统一、通知的类型不统一。比如:有的退款是同步返回结果、有的是异步返回结果。这里如何设计会在后面的 系统设计 中给出答案。
数据的设计是按照:交易、退款、日志 来设计的。对于上面说到的对账等功能并没有。这部分不难大家可以自行设计,按照上面讲到的思路。主要的表介绍如下:
pay_transaction记录所有的交易数据。pay_transaction_extension记录每次向第三方发起交易时,生成的交易号pay_log_data所有的日志数据,如:支付请求、退款请求、异步通知等pay_repeat_transaction重复支付的数据pay_notify_app_log通知应用程序的日志pay_refund记录所有的退款数据
具体的表结构:
-- -----------------------------------------------------
-- Table 创建支付流水表
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `pay_transaction` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`app_id` VARCHAR(32) NOT NULL COMMENT '应用id',
`pay_method_id` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '支付方式id,可以用来识别支付,如:支付宝、微信、Paypal等',
`app_order_id` VARCHAR(64) NOT NULL COMMENT '应用方订单号',
`transaction_id` VARCHAR(64) NOT NULL COMMENT '本次交易唯一id,整个支付系统唯一,生成他的原因主要是 order_id对于其它应用来说可能重复',
`total_fee` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '支付金额,整数方式保存',
`scale` TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '金额对应的小数位数',
`currency_code` CHAR(3) NOT NULL DEFAULT 'CNY' COMMENT '交易的币种',
`pay_channel` VARCHAR(64) NOT NULL COMMENT '选择的支付渠道,比如:支付宝中的花呗、信用卡等',
`expire_time` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '订单过期时间',
`return_url` VARCHAR(255) NOT NULL COMMENT '支付后跳转url',
`notify_url` VARCHAR(255) NOT NULL COMMENT '支付后,异步通知url',
`email` VARCHAR(64) NOT NULL COMMENT '用户的邮箱',
`sing_type` VARCHAR(10) NOT NULL DEFAULT 'RSA' COMMENT '采用的签方式:MD5 RSA RSA2 HASH-MAC等',
`intput_charset` CHAR(5) NOT NULL DEFAULT 'UTF-8' COMMENT '字符集编码方式',
`payment_time` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '第三方支付成功的时间',
`notify_time` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '收到异步通知的时间',
`finish_time` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '通知上游系统的时间',
`trade_no` VARCHAR(64) NOT NULL COMMENT '第三方的流水号',
`transaction_code` VARCHAR(64) NOT NULL COMMENT '真实给第三方的交易code,异步通知的时候更新',
`order_status` TINYINT NOT NULL DEFAULT 0 COMMENT '0:等待支付,1:待付款完成, 2:完成支付,3:该笔交易已关闭,-1:支付失败',
`create_at` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建时间',
`update_at` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '更新时间',
`create_ip` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建的ip,这可能是自己服务的ip',
`update_ip` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '更新的ip',
PRIMARY KEY (`id`),
UNIQUE INDEX `uniq_tradid` (`transaction_id`),
INDEX `idx_trade_no` (`trade_no`),
INDEX `idx_ctime` (`create_at`)),
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8mb4
COMMENT = '发起支付的数据';
-- -----------------------------------------------------
-- Table 交易扩展表
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `pay_transaction_extension` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`transaction_id` VARCHAR(64) NOT NULL COMMENT '系统唯一交易id',
`pay_method_id` INT UNSIGNED NOT NULL DEFAULT 0,
`transaction_code` VARCHAR(64) NOT NULL COMMENT '生成传输给第三方的订单号',
`call_num` TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '发起调用的次数',
`extension_data` TEXT NOT NULL COMMENT '扩展内容,需要保存:transaction_code 与 trade no 的映射关系,异步通知的时候填充',
`create_at` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建时间',
`create_ip` INT UNSIGNED NOT NULL COMMENT '创建ip',
PRIMARY KEY (`id`),
INDEX `idx_trads` (`transaction_id`, `pay_status`),
UNIQUE INDEX `uniq_code` (`transaction_code`)),
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8mb4
COMMENT = '交易扩展表';
-- -----------------------------------------------------
-- Table 交易系统全部日志
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `pay_log_data` (
`id` BIGINT UNSIGNED NOT NULL,
`app_id` VARCHAR(32) NOT NULL COMMENT '应用id',
`app_order_id` VARCHAR(64) NOT NULL COMMENT '应用方订单号',
`transaction_id` VARCHAR(64) NOT NULL COMMENT '本次交易唯一id,整个支付系统唯一,生成他的原因主要是 order_id对于其它应用来说可能重复',
`request_header` TEXT NOT NULL COMMENT '请求的header 头',
`request_params` TEXT NOT NULL COMMENT '支付的请求参数',
`log_type` VARCHAR(10) NOT NULL COMMENT '日志类型,payment:支付; refund:退款; notify:异步通知; return:同步通知; query:查询',
`create_at` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建时间',
`create_ip` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建ip',
PRIMARY KEY (`id`),
INDEX `idx_tradt` (`transaction_id`, `log_type`)),
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8mb4
COMMENT = '交易日志表';
-- -----------------------------------------------------
-- Table 重复支付的交易
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `pay_repeat_transaction` (
`id` BIGINT UNSIGNED NOT NULL,
`app_id` VARCHAR(32) NOT NULL COMMENT '应用的id',
`transaction_id` VARCHAR(64) NOT NULL COMMENT '系统唯一识别交易号',
`transaction_code` VARCHAR(64) NOT NULL COMMENT '支付成功时,该笔交易的 code',
`trade_no` VARCHAR(64) NOT NULL COMMENT '第三方对应的交易号',
`pay_method_id` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '支付方式',
`total_fee` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '交易金额',
`scale` TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '小数位数',
`currency_code` CHAR(3) NOT NULL DEFAULT 'CNY' COMMENT '支付选择的币种,CNY、HKD、USD等',
`payment_time` INT NOT NULL COMMENT '第三方交易时间',
`repeat_type` TINYINT UNSIGNED NOT NULL DEFAULT 1 COMMENT '重复类型:1同渠道支付、2不同渠道支付',
`repeat_status` TINYINT UNSIGNED DEFAULT 0 COMMENT '处理状态,0:未处理;1:已处理',
`create_at` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建时间',
`update_at` INT UNSIGNED NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`),
INDEX `idx_trad` ( `transaction_id`),
INDEX `idx_method` (`pay_method_id`),
INDEX `idx_time` (`create_at`)),
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8mb4
COMMENT = '记录重复支付';
-- -----------------------------------------------------
-- Table 通知上游应用日志
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `pay_notify_app_log` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`app_id` VARCHAR(32) NOT NULL COMMENT '应用id',
`pay_method_id` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '支付方式',
`transaction_id` VARCHAR(64) NOT NULL COMMENT '交易号',
`transaction_code` VARCHAR(64) NOT NULL COMMENT '支付成功时,该笔交易的 code',
`sign_type` VARCHAR(10) NOT NULL DEFAULT 'RSA' COMMENT '采用的签名方式:MD5 RSA RSA2 HASH-MAC等',
`input_charset` CHAR(5) NOT NULL DEFAULT 'UTF-8',
`total_fee` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '涉及的金额,无小数',
`scale` TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '小数位数',
`pay_channel` VARCHAR(64) NOT NULL COMMENT '支付渠道',
`trade_no` VARCHAR(64) NOT NULL COMMENT '第三方交易号',
`payment_time` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '支付时间',
`notify_type` VARCHAR(10) NOT NULL DEFAULT 'paid' COMMENT '通知类型,paid/refund/canceled',
`notify_status` VARCHAR(7) NOT NULL DEFAULT 'INIT' COMMENT '通知支付调用方结果;INIT:初始化,PENDING: 进行中; SUCCESS:成功; FAILED:失败',
`create_at` INT UNSIGNED NOT NULL DEFAULT 0,
`update_at` INT UNSIGNED NOT NULL DEFAULT 0,
PRIMARY KEY (`id`),
INDEX `idx_trad` (`transaction_id`),
INDEX `idx_app` (`app_id`, `notify_status`)
INDEX `idx_time` (`create_at`)),
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8mb4
COMMENT = '支付调用方记录';
-- -----------------------------------------------------
-- Table 退款
-- -----------------------------------------------------
CREATE TABLE IF NOT EXISTS `pay_refund` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`app_id` VARCHAR(64) NOT NULL COMMENT '应用id',
`app_refund_no` VARCHAR(64) NOT NULL COMMENT '上游的退款id',
`transaction_id` VARCHAR(64) NOT NULL COMMENT '交易号',
`trade_no` VARCHAR(64) NOT NULL COMMENT '第三方交易号',
`refund_no` VARCHAR(64) NOT NULL COMMENT '支付平台生成的唯一退款单号',
`pay_method_id` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '支付方式',
`pay_channel` VARCHAR(64) NOT NULL COMMENT '选择的支付渠道,比如:支付宝中的花呗、信用卡等',
`refund_fee` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '退款金额',
`scale` TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '小数位数',
`refund_reason` VARCHAR(128) NOT NULL COMMENT '退款理由',
`currency_code` CHAR(3) NOT NULL DEFAULT 'CNY' COMMENT '币种,CNY USD HKD',
`refund_type` TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '退款类型;0:业务退款; 1:重复退款',
`refund_method` TINYINT UNSIGNED NOT NULL DEFAULT 1 COMMENT '退款方式:1自动原路返回; 2人工打款',
`refund_status` TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '0未退款; 1退款处理中; 2退款成功; 3退款不成功',
`create_at` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '创建时间',
`update_at` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '更新时间',
`create_ip` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '请求源ip',
`update_ip` INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '请求源ip',
PRIMARY KEY (`id`),
UNIQUE INDEX `uniq_refno` (`refund_no`),
INDEX `idx_trad` (`transaction_id`),
INDEX `idx_status` (`refund_status`),
INDEX `idx_ctime` (`create_at`)),
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8mb4
COMMENT = '退款记录';表的使用逻辑进行下方简单描述:
支付,首先需要记录请求日志到 pay_log_data中,然后生成交易数据记录到 pay_transaction与pay_transaction_extension 中。
收到通知,记录数据到 pay_log_data 中,然后根据时支付的通知还是退款的通知,更新 pay_transaction 与 pay_refund 的状态。如果是重复支付需要记录数据到 pay_repeat_transaction 中。并且将需要通知应用的数据记录到 pay_notify_app_log,这张表相当于一个消息表,会有消费者会去消费其中的内容。
退款 记录日志日志到 pay_log_data 中,然后记录数据到退款表中 pay_refund。
当然这其中还有些细节,需要大家自己看了表结构,实际去思考一下该如何使用。如果有任何疑问欢迎到我们GitHub的项目(点击阅读原文)中留言,我们都会一一解答。
这些表能够满足最基本的需求,其它内容可根据自己的需求进行扩张,比如:支持用户卡列表、退款走银行卡等。
这部分主要说下系统该如何搭建,以及代码组织方式的建议。
由于支付系统的安全性非常高,因此不建议将对应的入口直接暴露给用户可见。应该是在自己的应用系统中调用支付系统的接口来完成业务。另外系统对数据要求是:强一致性的。因此也没有缓存介入(当如缓存可以用来做报警,这不在本文范畴)。
具体的实现,系统会使用两个域名,一个为内部使用,只有指定来源的ip能够访问固定功能(访问除通知外的其它功能)。另一个域名只能访问 notify return 两个路由。通过这种方式可以保证系统的安全。
在数据库的使用上无论什么请求直接走 Master 库。这样保证数据的强一致。当然从库也是需要的。比如:账单、对账相关逻辑我们可以利用从库完成。
不管想做什么最终都要用代码来实现。我们都知道需要可维护、可扩展的代码。那么具体到支付系统你会怎么做呢?我已支付为例说下我的代码结构设计思路。仅供参考。比如我要介入:微信、支付宝、招行 三家支付。我的代码结构图如下:
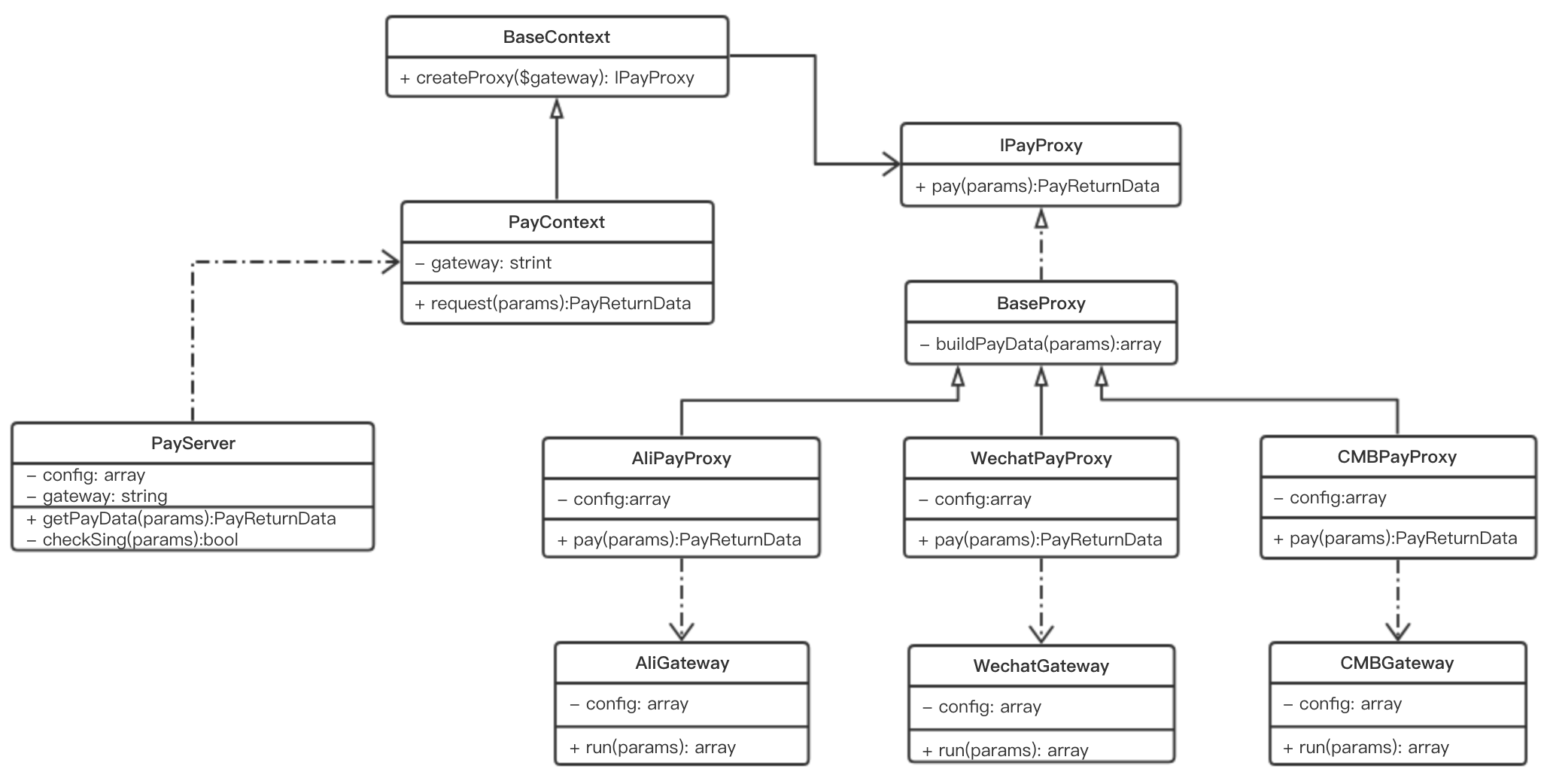
用文字简单介绍下。我会将每一个第三方封装成: XXXGateway 类,内部是单纯的封装第三方接口,不管对方是 HTTP 请求还是 SOAP 请求,都在内部进行统一处理。
另外有一层XXXProxy 来封装这些第三方提供的能力。这一层主要干两件事情:对传过来请求支付的数据进行个性化处理。对返回的结构进行统一处理返回上层统一的结构。当然根据特殊情况这里可以进行一切业务处理;
通过上面的操作变化已经基本上被完全封装了。如果新增一个支付渠道。只需要增加:XXXGateway 与 XXXProxy。
那么 Context 与 Server 有什么用呢?Server 内部封装了所有的业务逻辑,它提供接口给 action 或者其它 server 进行调用。而 Context 这一层存在的价值是处理 Proxy 层返回的错误。以及在这里进行报警相关的处理。
上面的结构只是我的一个实践,欢迎大家讨论。
本文描述的系统只是满足了最基本的支付需求。缺少相关的监控、报警。如果你按照上文设计自己的系统,风险自担与我无关。
请您耐心等待...
请您耐心等待...
请您耐心等待...
请您耐心等待...
请您耐心等待...
排名不分先后,字典序
| 昵称 | 简介 | 个人博客 |
|---|---|---|
| AStraw | 研究生创业者 | 公众号“稻草人生” |
| 大愚Dayu | 国内大多人使用的PHP第三方支付聚合项目Payment作者,创过业 | 大愚Talk |
| lwhcv | 曾就职于百度/融360 | -------- |
| TIGERB | PHP框架EasyPHP作者 | TIGERB的技术博客 |
| Veaer | 宇宙无敌风火轮全干工程师 | Veaer |