This repository contains the PyTorch implementation for "Dynamic Group Convolution for Accelerating Convolutional Neural Networks" by Zhuo Su*, Linpu Fang*, Wenxiong Kang, Dewen Hu, Matti Pietikäinen and Li Liu (* Authors have equal contributions). [arXiv]
The code is based on CondenseNet.
If you find our project useful in your research, please consider citing:
@inproceedings{su2020dgc,
title={Dynamic Group Convolution for Accelerating Convolutional Neural Networks},
author={Su, Zhuo and Fang, Linpu and Kang, Wenxiong and Hu, Dewen and Pietik{\"a}inen, Matti and Liu, Li},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2020}
}
Dynamic Group Convolution (DGC) can adaptively select which part of input channels to be connected within each group for individual samples on the fly. Specifically, we equip each group with a small feature selector to automatically select the most important input channels conditioned on the input images. Multiple groups can adptively capture abundant and complementary visual/semantic features for each input image. The DGC preserves the original network structure and has similar computational efficiency as the conventional group convolutions simultaneously. Extensive experiments on multiple image classification benchmarks including CIFAR-10, CIFAR-100 and ImageNet demonstrate its superiority over the exiting group convolution techniques and dynamic execution methods.
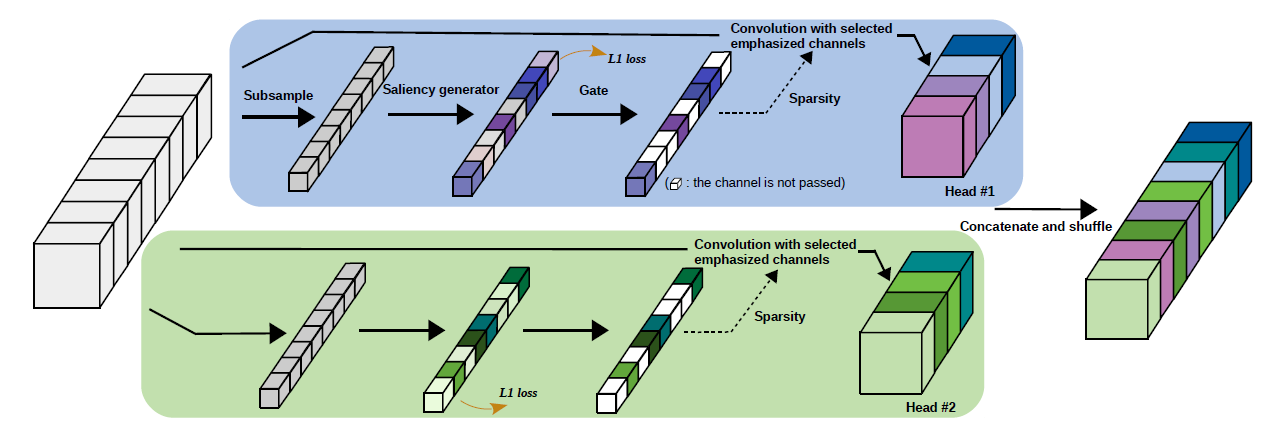
Figure 1: Overview of a DGC layer.
The DGC network can be trained from scratch by an end-to-end manner, without the need of model pre-training. During backward propagation in a DGC layer, gradients are calculated only for weights connected to selected channels during the forward pass, and safely set as 0 for others thanks to the unbiased gating strategy (refer to the paper). To avoid abrupt changes in training loss while pruning, we gradually deactivate input channels along the training process with a cosine shape learning rate.

Figure 2: Training pipeline.
At the moment, we are sorry to tell that the training process on ImageNet is somewhat slow and memory consuming because this is still a coarse implementation. For the first bash script of condensenet on ImageNet, the model was trained on two v100 GPUs with 32G gpu memory each.
Remove --evaluate xxx.tar to Train, otherwise to Evaluate (the trained models can be downloaded through the following links or baidunetdisk (code: 9dtn))
(condensenet with dgc on ImageNet, pruning rate=0.75, heads=4, top1=25.4, top5=7.8)
Links for imagenet_dydensenet_h4.tar (92.3M):
google drive,
onedirve
python main.py --model dydensenet -b 256 -j 4 --data imagenet --datadir /path/to/imagenet \
--epochs 120 --lr-type cosine --stages 4-6-8-10-8 --growth 8-16-32-64-128 --bottleneck 4 \
--heads 4 --group-3x3 4 --gate-factor 0.25 --squeeze-rate 16 --resume --gpu 0 --savedir results/exp \
--evaluate /path/to/imagenet_dydensenet_h4.tar(resnet18 with dgc on ImageNet, pruning rate=0.55, heads=4, top1=31.22, top5=11.38)
Links for imagenet_dyresnet18_h4.tar (47.2M):
google drive,
onedirve
python main.py --model dyresnet18 -b 256 -j 4 --data imagenet --datadir /path/to/imagenet \
--epochs 120 --lr-type cosine --heads 4 --gate-factor 0.45 --squeeze-rate 16 --resume \
--gpu 0 --savedir results/exp --evaluate /path/to/imagenet_dyresnet18_h4.tar(densenet86 with dgc on Cifar10, pruning rate=0.75, heads=4, top1=4.77)
Links for cifar10_dydensenet86_h4.tar (16.7M):
google drive,
onedirve
python main.py --model dydensenet -b 64 -j 4 --data cifar10 --datadir ../data --epochs 300 \
--lr-type cosine --stages 14-14-14 --growth 8-16-32 --bottleneck 4 --heads 4 --group-3x3 4 \
--gate-factor 0.25 --squeeze-rate 16 --resume --gpu 0 --savedir results/exp \
--evaluate /path/to/cifar10_dydensenet86_h4.tar(densenet86 with dgc on Cifar100, pruning rate=0.75, heads=4, top1=23.41)
Links for cifar100_dydensenet86_h4.tar (17.0M):
google drive,
onedirve
python main.py --model dydensenet -b 64 -j 4 --data cifar100 --datadir ../data --epochs 300 \
--lr-type cosine --stages 14-14-14 --growth 8-16-32 --bottleneck 4 --heads 4 --group-3x3 4 \
--gate-factor 0.25 --squeeze-rate 16 --resume --gpu 0 --savedir results/exp \
--evaluate /path/to/cifar100_dydensenet86_h4.tarAny discussions or concerns are welcomed in the Issues!