{kind=link}
A powerful library for audio processing with advanced features for speech recognition, text translation, and speech synthesis.
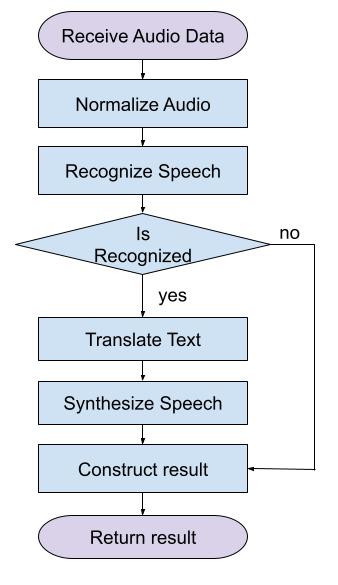
This robust library offers a wide range of capabilities for working with audio, including speech recognition, text translation, and speech synthesis. It is perfect for developers looking to integrate advanced audio features into their applications.
Key Features:
- Speech Recognition: Accurate and fast conversion of voice to text for various languages.
- Text Translation: Automatic translation of recognized text into other languages, making interaction more accessible.
- Speech Synthesis: Generation of natural-sounding speech from text, enabling the creation of interactive voice applications.
This library is designed to provide high-quality audio processing tools, offering everything you need to develop innovative solutions in the field of speech technology.
pip install babylon-stsHere is an example of how to process a local audio file, translate its content, and save the result to a new file:
import numpy as np
import soundfile as sf
from datetime import datetime
from pydub import AudioSegment
from babylon_sts import AudioProcessor
def process_local_audio(input_file: str, output_file: str, language_to: str = 'ru', language_from: str = 'en', model_name: str = 'small', sample_rate: int = 24000):
# Using pydub to read the MP3 file
audio_segment = AudioSegment.from_file(input_file)
# Converting audio to a format supported for further processing
audio_segment = audio_segment.set_frame_rate(sample_rate).set_channels(1)
audio_data = np.array(audio_segment.get_array_of_samples())
audio_data = audio_data.tobytes() # Converting data to bytes
# Creating an instance of AudioProcessor with the necessary parameters
audio_processor = AudioProcessor(language_to=language_to, language_from=language_from, model_name=model_name, sample_rate=sample_rate)
# Current time as a timestamp for processing
timestamp = datetime.utcnow()
try:
# Processing the audio data
final_audio, log_data = audio_processor.process_audio(timestamp, audio_data)
# Saving the processed audio to a new file
sf.write(output_file, final_audio, sample_rate)
except ValueError as e:
print(f"Error during synthesis: {e}")
# Calling the function to process the local file
process_local_audio('audio/original_audio.mp3', 'audio/translated_audio.wav')- language_to (str): The language code. Possible values: 'en', 'ua', 'ru', 'fr', 'de', 'es', 'hi'.
- language_from (str): The language code. Possible values: 'en', 'ua', 'ru', 'fr', 'de', 'es', 'hi'.
- model_name (str): The Whisper model to use. Possible values: 'tiny', 'base', 'small', 'medium', 'large'.
- sample_rate (int): The sample rate for audio processing.
- speaker (Optional[str]): The name of speaker for speech synthesize. Full speakers list here https://github.com/snakers4/silero-models?tab=readme-ov-file#models-and-speakers
pip install -r requirements.txtpython -m unittest discover -s testsThis library leverages several state-of-the-art models to provide advanced audio processing features:
- Whisper by OpenAI for speech recognition: Whisper GitHub Repository
- Helsinki-NLP's MarianMT for text translation: MarianMT GitHub Repository
- Silero Models for speech synthesis: Silero Models GitHub Repository
These models are used in accordance with their respective licenses.
This project is licensed under the MIT License - see the LICENSE file for details.