CLI Train
To train a machine learning model targeting a different entity type using a new corpus, the nejiTrain.sh executable can be used, which provides usage and self-explanatory information.
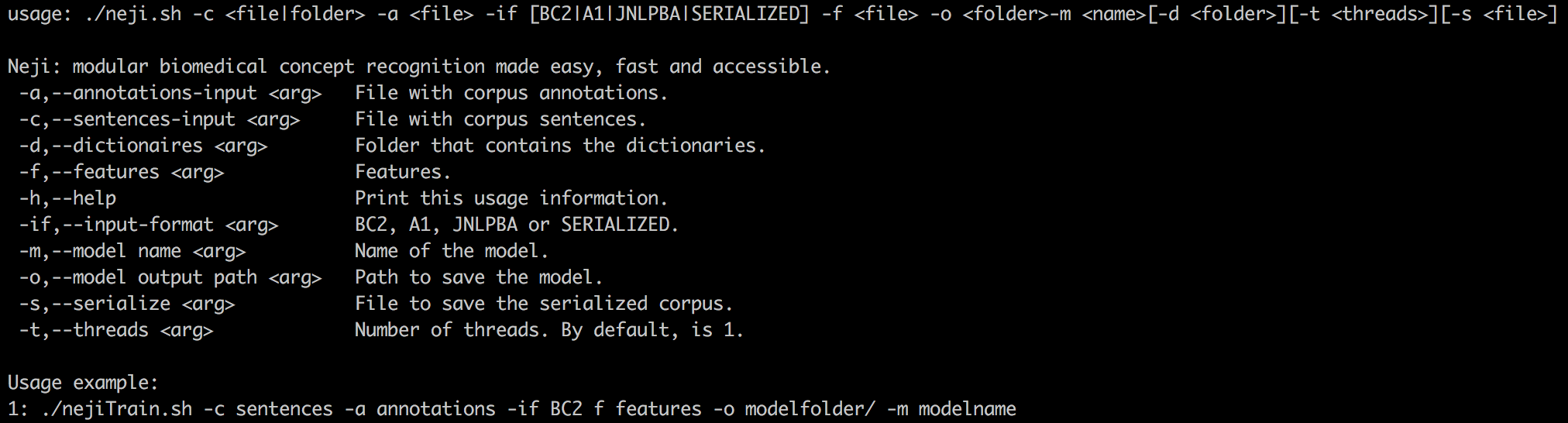
Description of the supported input corpora formats is available on the Formats page.
The definition of CRF models' characteristics is performed using a simple configuration file. Through it, you can specify:
- the features that the model will use
- the order of the CRF
- the parsing direction
- the target entity type
token=1
stem=0
lemma=1
pos=1
chunk=1
nlp=0
capitalization=1
counting=1
symbols=1
ngrams=1
suffix=1
prefix=1
morphology=1
greek=1
roman=0
prge=1
concepts=1
verbs=1
window=1
conjunctions=0
order=2
parsing=BW
entity=PRGE
As the output of training a model, a folder with the model name and the following structure is created:
_priority
model
model.config
model.gz
model.properties
This folder contains the model ("model.gz"), its configuration ("model.config"), its characteristics ("model.properties") and the priority file ("_priority") to be used by Neji. With this output, the model is ready to be directly used by Neji to annotate documents.
Neji is distributed with an example, which is provided in the "example/train" folder. The following resources are provided:
- Corpus: sentences and annotations in BC2 format
- Model Configuration: configuration file with a simple model
To train a model using the provided corpus and model configuration, execute the following command:
./nejiTrain.sh -if BC2
-c example/train/sentences -a example/train/annotations
-f example/train/bw_o2_windows.config
-m genetag_lite_model -o example/train/