Features
This section covers the different features implemented in the Web Audio Evaluation Tool.
Unless otherwise specified, each feature described here is optional, i.e. it can be enabled and disabled, or adjusted to some extent.
As the example projects (in ./tests/examples/) showcase all of these features, please refer to these configuration XML documents for a demonstration of how to enable and adjust them.
See XML specification for extensive documentation on how to use these features.
Crucial to almost every kind of experiment design, randomisation is embedded at various stages of the Web Audio Evaluation Tool, from random ordering and labelling of stimuli, over presentation of the different pages in random order, to offering an entirely different test to different participants in a pseudo-random fashion.
Make sure to switch these options on if you need it.
For the page pooling, you have to place all of your pages inside one XML and store it at tests/pool.xml. Then use the url attribute on the page loading to request php/pool.php. This will trigger the automatic scanning of your saves folder to create a test of a subset of pages. You set the number of pages to present by setting the poolSize attribute of the node.
Almost any participant action can be logged with a time stamp, including
- time spent for each page
- times spent listening to each individual fragment
- portion of fragment that was auditioned each time
- initial (random) position of sliders
- movements of each slider
This data can then be used for any purpose, as well as visualised automatically with e.g. the timeline_view_movement.py script, as follows:

The XML results files provide a convenient data structure which can be used in virtually any data processing workflow. However, those who are satisfied with a simple box plot, pie chart, or confidence interval display of test results, can visualise all results within the browser. Additionally, some Python scripts are included to quickly generate graphs.
Even for those with bigger plans for data analysis, this feature facilitates spotting of errors, or allows showing a graph of an individual's results (or all results thus far) immediately upon submitting a test.
Depending on your needs, the participant can be reminded to do either of the following things before even being able to continue to the next page, or submit the test:
- all fragments are (partially/completely) played;
- all sliders have been moved at least once;
- no comment boxes are left empty;
- at least one slider is below a certain value;
- at least one slider is above a certain value.
Various flavours of survey questions (text box, number, radio button, check box) are available for in-test surveys, which can be shown immediately before or after the test, or before/after any page.
If you want to allow participants to change the listening level throughout the test, a volume slider can be shown on the screen, with the added advantage that movements of this slider can be logged.
When this is activated, the samples are synchronised so that when sample A is at the 5.1 second mark when switching to sample B, sample B starts playing from exactly 5.1 seconds onwards (as opposed to from the start, i.e. 0.0 seconds). This is especially relevant when the stimuli being compared are different versions of the same source, and longer than a few seconds.
The implementation here allows for seamless switching between fragments. The Web Audio API makes it possible for us to play all stimuli at the same time, and mute/solo the selected one only, then toggle rapidly to the next selected stimulus.
There are two major advantages to time-aligned switching:
- When switching between two samples, only the differing attributes change and not the source material and its position (i.e. the brightness of the same music excerpt).
- There is no excessive focus on the first few seconds of the excerpt, which would be the case when quickly switching between a few different samples.
Switching can also be disabled altogether, forcing subjects to let a fragment finish playback (or interrupt manually) before being able to audition another fragment.
Looping enables the fragments to loop until stopped by the user. Looping is synchronous so all fragments start at the same time on each loop. Individual test pages can have their playback looped by the <page> attribute loop with a value of "true" or "false". If the fragments are not of equal length initially, they are padded with zeros so that they are equal length, to enable looping without the fragments going out of sync relative to each other.
Note that fragments cannot be played until all page fragments are loaded when in looped mode, as the engine needs to know the length of each fragment to calculate the padding.
Each audio fragment has its loudness calculated on loading. It is possible to change the fragment's gain automatically so that a certain loudness is reached. This is especially useful when all samples need to be equally loud within a certain page or test. The tool uses the EBU R128 recommendation following the ITU-R BS.1770-4 loudness calculations to return the integrated LUFS loudness. The loudness attribute is set in LUFS.
The attribute loudness specifies the desired loudness for all audioelements within the current scope. Applying it in the <setup> node will set the loudness for all test pages. Applying it in the <page> node will set the loudness for that page. Applying it in the <audioelement> node will set the loudness for that fragment. The scope is set locally, so if there is a loudness on both the <page> and <setup> nodes, that test page will take the value associated with the <page>.
It is possible to set the gain (in decibel) applied to the different audioelements. This gain is applied after any loudness normalisation.
The sessions are saved intermittently to the server (or local machine, depending on test) so that a test can be resumed in the event of a computer failure, human error or forgotten dentist appointment.
Risk of accidentally closed windows (and the resulting loss of data) is mitigated by showing a warning message before allowing anyone to close an incomplete test.
At the very start of a test, sliders corresponding with sine waves at different octaves can be shown, to be set at an equal perceived loudness. This can serve as an audiometric test, and/or a test of the playback system.
This is especially useful as a crude assessment in remote tests, where it is critical to know whether some low or high frequencies are clearly audible.
If you require the test to be conducted at a certain sample rate (i.e. you do not tolerate resampling of the elements to correspond with the system's sample rate), add sampleRate="96000" - where "96000" can be any supported sample rate (in Hz) - so that a warning message is shown alerting the subject that their system's sample rate is different from this enforced sample rate. This is checked immediately after parsing and stops the page loading any other elements if this check has failed.
See Sample rate for information on how to set the sample rate on a Windows or Mac computer prior to taking a listening test.
Show the current test page number and the total number of test pages.
Stimuli can be rated in terms of several attributes at once. Note that we do not necessarily recommend this, as participants tend to 'correlate' ratings of different attributes, e.g. rate 'overall preference' highly when 'fidelity' is rated highly, also known as the Halo bias.
The audio elements, <audioelement> have the attribute type, which defaults to normal. Setting this to one of the following will have the following effects.
type="outside-reference"
This will place the object in a separate playback element clearly labelled as an outside reference. This is exempt of any movement checks but will still be included in any listening checks.
Hidden reference
type="reference"
The element will still be randomised as normal (if selected) and presented to the user. However, the element will have the ‘reference’ type in the results to quickly find it. The reference can be forced to be above a value before completing the test page by setting the attribute 'marker' to be a value between 0 and 100 representing the integer value position it must be equal to or above.
Hidden anchor
type="anchor"
The element will still be randomised as normal (if selected) and presented to the user. However the element will have the 'anchor' type in the results to quickly find it. The anchor can be forced to be below a value before completing the test page by setting the attribute ‘marker’ to be a value between 0 and 100 representing the integer value position it must be equal to or below.
For troubleshooting and usage statistics purposes, information about the browser and the operating system is logged in the results XML file. This is especially useful in the case of remote tests, when it is not certain which operating system, browser and/or browser were used. Note that this information is not always available and/or accurate, e.g. when the subject has taken steps to be more anonymous, so it should be treated as a guide only.
Example:
<navigator> <platform>MacIntel</platform>
<vendor>Google Inc.</vendor>
<uagent>Mozilla /5.0 . . . </uagent>
<screen innerHeight="1900px" innerWidth="1920px"/>
</navigator>
There are two types of comment boxes which can be presented, those linked to the audio fragments on the page and those which pose a general question. When enabled, there is a comment box below the main interface for every fragment on the page. There is some customisation around the text that accompanies the box, by default the text will read "Comment on fragment" followed by the fragment identifier (the number / letter shown by the interface). This 'prefix' can be modified using the page node <commentboxprefix>. The comment box prefix node takes no attribute and the text contained by the node represents the prefix. For instance, if we have a node <commentboxprefix> Describe fragment </commentboxprefix>, then the interface will show "Describe fragment" followed by the identifier (the marker label).
The second type of comment box is slightly more complex because it can handle different types of response data. These are called 'comment questions' because they are located in the comment section of the test but pose a specific question, not related to any individual stimulus.
Rating interfaces (MUSHRA, Horizontal, Discrete, ...) can have an optional 'Sort' button that rearranges the stimuli so that they appear in increasing order of subject rating.
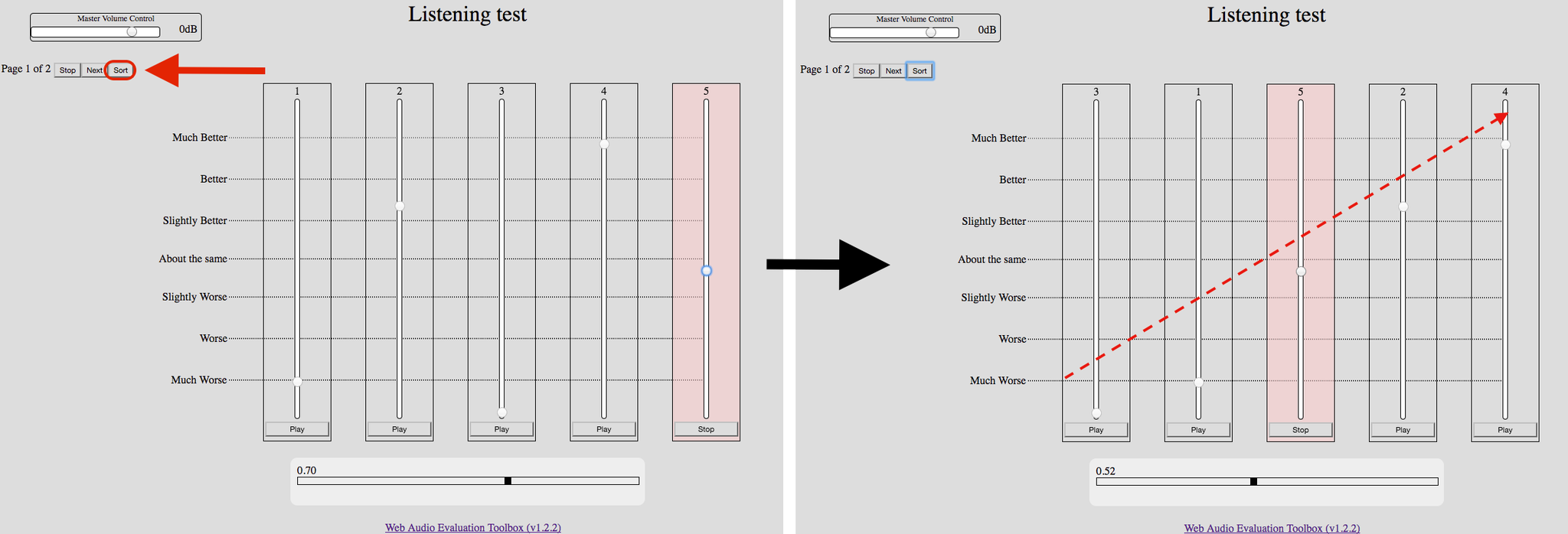
The APE interface requires you to drag the stimuli in order yourself, so the sorting functionality is redundant there.
Append &saveFilenamePrefix=somecustomname to the test URL to save files as somecustomname-[randomstring].xml instead of save-[randomstring].xml. This allows to distinguish between different tests, different participants, or different locations, without looking at the content of the XML files.