❯ CMake
❯ GCC
❯ Git
❯ C++ IDE (optional). CLion is recommended.
Note
To install
CMakeyou should run this code on your computer:
Important this code works only on Ubuntu!$ sudo apt install cmakeTo find out how to download to your operating system follow this link.
For compiler installation, please, refer to the official documentation of your compiler. For example GCC link.
-
You should compile our project run the
compile.shfile with-cflag:$ ./compile.sh -c # compile project # or $ ./compile.sh --compile # compile project
-
If you want to get rid of executable files, run the
compile.shfile with--cleanflag:$ ./compile.sh --clean
Note
If you get this error when running
compile.sh:$ -bash: ./compile.sh: /bin/bash^M: bad interpreter: No such file or directoryenter that code:
$ sed -i -e 's/\r$//' compile.sh
To install our project, you need to clone the repository first:
$ mkdir ~/workdir
$ cd ~/workdir
$ git clone https://github.com/CaCuCkA/thread-pools.git
$ cd thread-poolsReplace
~/workdirwith the path to your workspace.
One possible way to understand is realworld example. Imagine you have company where employees who would normally spend
their time in the office are occasionally required to visit clients or suppliers or to attend a trade show or
conference. Although these trips might be necessary, and on any given day there might be several people making this
trip, it may well be months or even years between these trips for any particular employee. Because it would therefore be
rather expensive and impractical for each employee to have a company car, companies often offer a car pool instead;
they
have a limited number of cars that are available to all employees. When an employee needs to make an off-site trip, they
book one of the pool cars for the appropriate time and return it for others to use when they return to the office. If
there are no pool cars free on a given day, the employee will have to reschedule their trip for a subsequent date.
Thread pool is the similar idea, except that threads are being shared rather than cars. I found an image in the
Internet to better understanding how it works.
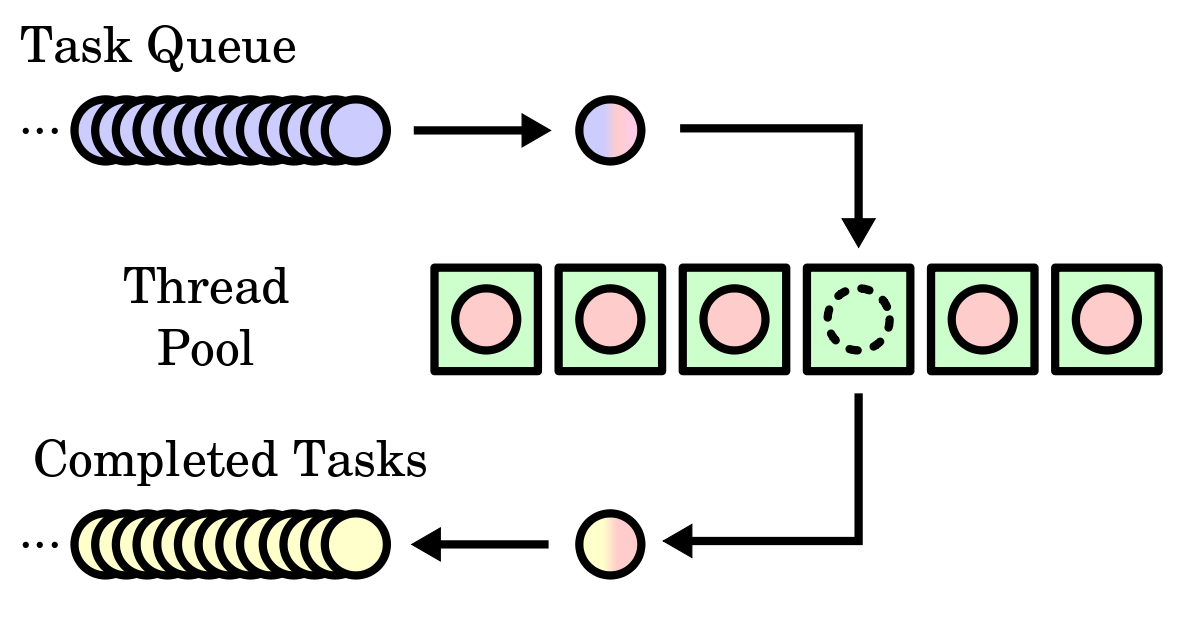
As you can see, we have three important elements here:
- Task Queue. This is where the work that has to be done is stored.
- Thread Pool. This is set of
workersthat continuously take work from the queue and do it. - Complete Tasks. When the Thread has finished the work we return "something" to notify that the work has finished.
All tasks that can be executed concurrently are submitted to the pool, which put them on a queue. We use this
datastructure because we want the work to be started in the same order that we sent it. However, if we will have
basic queue which are already implemented in standard library we will have data race. Therefore, we should
implement our own thread safe queue.
This is wrapper that use mutex and condition variables to restrict the concurrent access. Let's see a small sample
of the ThreadSafeQueue class:
void Enque(T&& val)
{
{
std::unique_lock lock(m_mutex);
m_buffer.push_front(std::move(val));
}
m_not_empty.notify_one();
}-
The code starts with a block of code enclosed in curly braces
{}. This is known as a scoped block and is used to limit the scope ofstd::unique_lockobject lock. By enclosing it in a block, the lock will be automatically released when the -
Inside the scoped block, a
std::unique_locknamed lock is created using the mutex. Thestd::unique_lockis a RAII (Resource Acquisition Is Initialization) class that provides automatic locking and unlocking of a mutex. By creating astd::unique_lockobject withm_mutex, the mutex is locked. -
The next is taken push element into the back of the queue.
-
After the scoped block ends, the
std::unique_lockobject lock is destroyed, and the mutexm_mutexis automatically unlocked. -
Finally, the line
m_not_empty.notify_one()notifies a waiting thread that the queue is not empty. This is done by calling the notify_one member function on the m_not_empty condition variable. This will wake up a single waiting thread that is blocked on the condition variable, allowing it to continue execution.
The most important method of the thread pool is the one responsible for adding work to the queue. Usually this method is called submit. For the first time it is pretty hard to understand how does it work. However, I will try to explain. Let's think about what should do and after tha we will worry about how to do it. What:
- Accept any function with any parameters.
- Return "something" immediately to avoid blocking main thread. This returned object should eventually contain the result of the operation.
The complete submit functions looks like this:
template<typename FunctionType>
std::future<typename std::result_of<FunctionType()>::type>
Submit(FunctionType function)
{
typedef typename std::result_of<FunctionType()>::type resultType;
std::packaged_task<resultType()> task(std::move(function));
std::future<resultType> result(task.get_future());
m_work_queue.Enque(std::move(task));
return result;
}Nevertheless, we're going to inspect line by line what's going on in order to fully understand how it works.
Function returns a std::future<> to hols the return
value of the task and allow the caller to wait for the task to complete. This requires
that you know the return type of the supplied function, which is where std::result_of<> comes
in: std::result_of<FunctionType()>::type is the type of the result of involving an instance of type FunctionType (
such as function) with no arguments. We will use the same std::result_of<> expression for the resultType typedef
inside the function.
Then we wrap the function in a std::packaged_task<resultType()> because function is a function or callable object
that takes no parameters and returns an instance of type resultType, as we deduced. Now we can get future from
the std::packaged_task<> before pushing the task into the queue
and returning the future. Note that we have to use std::move() when pushing the task onto the queue,
because std::packeged_task<> isn't copyable. The queue now stores FunctionWrapper object rather
than std::function<void()> objets in order to handle this.
For the reason that std::packaged_task<> instances are not copyable, just movable, we cannot use std::function<> for
the queue entries, because std::function<> requires that the stored function objects are copy-constructible. Instead,
we must use a custom function wrapper that can handle move-only types. This is a simple type-erasure class with a
function call operator. We only need to handle functions that take no parameters and return void, so this is a
straightforward virtual call in the implementation
The complete FunctionWrapper class looks like this:
class FunctionWrapper
{
struct ImplementBase
{
virtual void Call() = 0;
virtual ~ImplementBase() {}
};
template<typename F>
struct ImplementType : ImplementBase
{
F m_f;
ImplementType(F&& t_f)
:
m_f(std::move(t_f))
{}
void Call()
{
m_f();
}
};
public:
FunctionWrapper() = default;
FunctionWrapper(const FunctionWrapper&) = delete;
FunctionWrapper(FunctionWrapper&) = delete;
FunctionWrapper& operator=(const FunctionWrapper&) = delete;
template<typename F>
FunctionWrapper(F&& f)
:
m_implement(new ImplementType<F>(std::forward<F>(f)))
{}
FunctionWrapper(FunctionWrapper&& other)
:
m_implement(std::move(other.m_implement))
{}
FunctionWrapper& operator=(FunctionWrapper&& other)
{
m_implement = std::move(other.m_implement);
return *this;
}
void operator()()
{
m_implement->Call();
}
private:
std::unique_ptr<ImplementBase> m_implement;
};Now that we understand how the submit method works, we're going to focus on how the work gets done. Probably, the simplest implementation of a thread worker could be using polling:
Loop:
If Queue is not empty
Dequeue work
Do it
else
reschedule the execution of threads
Okay, now we should understand what is going on here. Our thread try to deque task in loop if the thread succeeds in, it will do the task otherwise it will be rescheduled to give opportunity to work other threads. The final code of a worker looks like this:
void WorkerThread()
{
while(!m_done)
{
FunctionWrapper task;
if (m_work_queue.TryDeque(task))
{
task();
}
else
{
std::this_thread::yield();
}
}
}There is no coordinate difference between implementing a thread pool using WinApi and the pthread library. But there
are some nuances that I would like to draw your attention to.
Note
I can't guarantee that this is the only correct implementation especially using
WinApi, so if you've seen more correct variants of implementation, I'd be happy if you could share them with me
Implementation of thread pool is based on WinApi. This high-level API does away with the burden of thread pool
implementation and gives you a number of features that allow you to speed up the implementation process. I would like to
draw attention to a number of features that I use for implementation:
-
CreateThreadpool()andCloseThreadpool(). These functions are used to create and close a thread pool. So I put them in the constructor and destructor of my class. Their pre-declaration:PTP_POOL CreateThreadpool( PVOID reserved );void CloseThreadpool( [in, out] PTP_POOL ptpp );
-
SetThreadpoolThreadMinimum()andSetThreadpoolThreadMaximum(). These functions are used to set the maximum and minimum number of threads that a thread pool can possess. In my implementation I used onlySetThreadpoolThreadMinimum(). I set the number of threads equal to the number of logical cores on my computer. To find out how many you have, you can use this command:SYSTEM_INFO sysInfo; GetSystemInfo(&sysInfo); DWORD threadCount = sysInfo.dwNumberOfProcessors;Function pre-declaration:
BOOL SetThreadpoolThreadMinimum( [in, out] PTP_POOL ptpp, [in] DWORD cthrdMic );void SetThreadpoolThreadMaximum( [in, out] PTP_POOL ptpp, [in] DWORD cthrdMost );
-
CreateThreadpoolWork()andCloseThreadpoolWork(). This functions creates and closes worker objects. I used them in functionSubmit()and class` destructor. Their pre-declaration:PTP_WORK CreateThreadpoolWork( [in] PTP_WORK_CALLBACK pfnwk, [in, out, optional] PVOID pv, [in, optional] PTP_CALLBACK_ENVIRON pcbe );void CloseThreadpoolWork( [in, out] PTP_WORK pwk );
I would also like to point out that the WorkerThread function is different from the basic function that was implemented in the
StaticThreadPoolclass. It`s final code looks like:template<typename ResultType> static void CALLBACK ThreadPoolWorkCallback(PTP_CALLBACK_INSTANCE, PVOID Context, PTP_WORK) { auto task = static_cast<std::packaged_task<ResultType()>*>(Context); (*task)(); delete task; }
-
SubmitThreadpoolWork(). This function posts a work object to the thread pool. A worker thread calls the work object's callback function. I also used this function inSubmit(). It`s pre-declaration:void SubmitThreadpoolWork( [in, out] PTP_WORK pwk );
Generally speaking, the full version of the class is not much different from the basic version, but it has its own
nuances. You can read more details about WinApi at the official Microsoft
website.
Basically, the implementation of a thread pool using the pthread library is no different from the basic one except
that
it uses exclusively pthread library functions. Therefore, I think there is no need to explain its implementation.
Every time a thread calls submit() on a particular instance of the thread pool, it has to push a new item onto the
single shared work queue. Likewise, the worker threads are continually popping items off the queue in order to run the
tasks. This means that as the number of processors increases, there’s increasing contention on the queue. This can be a
real performance drain; even if you use a lock-free queue so there’s no explicit waiting, cache ping-pong can be a
substantial time sink. One way to avoid cache ping-pong is to use a separate work queue per thread. Each thread then
posts new items to its own queue and takes work from the global work queue only if there’s no work on its own individual
queue. The following listing shows an implementation that makes use of a thread_local variable to ensure that
each thread has its own work queue, as well as the global one
Now Submit() checks to see if the current thread has a work queue. If it does, it`s a pool thread, and you can put the
task on the local queue; otherwise, you need to put the task on the pool queue as before. The full implementation of
this function is look like:
template<typename FunctionType>
std::future<typename std::result_of<FunctionType()>::type>
Submit(FunctionType function)
{
typedef typename std::result_of<FunctionType()>::type resultType;
std::packaged_task<resultType()> task(function);
std::future<resultType> result(task.get_future());
if (m_localQueue)
{
m_localQueue->Enque(std::move(task));
}
else
{
m_mainQueue.Enque(std::move(task));
}
}Function WorkerThread() is also upgraded. Now all logic is in RunPendingTask() function. All what it does is check
to see if there are any items on the local queue. If there are, you can take the front one and process it; notice that
the local queue can be a plain std::queue<> because it’s only ever accessed by the one thread. If there are no tasks
on the local queue, you try the pool queue as before. This works fine for reducing contention, but when the distribution
of work is uneven, it can easily result in one thread having a lot of work in its queue while the others have no work do
to. Full implementation of WorkerThread() and RunPendingTask() are look like:
void WorkerThread()
{
m_localQueue = std::make_unique<local_queue_type>();
while (!m_done)
{
RunPendingTask();
}
}void RunPendingTask()
{
FunctionWrapper task;
if (m_localQueue && !m_localQueue->empty())
{
task = std::move(m_localQueue->front());
m_localQueue->pop();
task();
}
else if (m_mainQueue.TryDeque(task))
{
task();
}
else
{
std::this_thread::yield();
}
}In order to allow a thread with no work to do to take work from another thread with a full queue, the queue must be
accessible to the thread doing the stealing from RunPendingTask(). This requires that each thread register its queue
with the thread pool or be given one by the thread pool. Also, you must ensure that the data in the work
queue is suitably synchronized and protected so that your invariants are protected.
For this thread pool implementation we should modify our thread safe queue. It’s possible to write a lock-free queue
that allows the owner thread to push and pop at one end while other threads can steal entries from the other. Let's see
a small sample of the WorkStealingQueue class:
bool TrySteal(T& data)
{
std::lock_guard<std::mutex> lock(m_mutex);
if (m_buffer.empty())
{
return false;
}
data = std::move(m_buffer.back());
m_buffer.pop_back();
return true;
}The implementation of this function is quite simple to understand. First we have to lock our mutex to make sure no one
can take our item. Then we check if the buffer (our queue) is empty and still the item from it. The careful reader will
notice that the TrySteal function takes an element from the end. This can help improve performance from a cache
perspective, because the data related to that task is more likely to still be in the cache than the data related to a
task pushed on the queue previously.
The implementation of the Submit() function is no different, so I see no point in discussing it.
The WorkerThread() does not change. However, a RunPendingTask() is being updated. Now we add another check, where we
check if we can take task from another queue. Full implementation of RunPendingTask() is looks like:
void RunPendingTask()
{
FunctionWrapper task;
if (PopTaskFromLocalQueue(task) ||
PopTaskFromPoolQueue(task) ||
PopTaskFromOtherThreadQueue(task))
{
task();
}
else
{
std::this_thread::yield();
}
}Creating the thread pool is as easy as:
cross_type::thread_pool threadPool;If we want to send some work to the pool, after we have initialized it, we just have to call the submit function:
threadPool.Submit([=]()
{
return Multiply(i, j);
}));To test productivity of different types of thread pool I create problem that simulate work:
inline void SimulateHardComputation()
{
std::this_thread::sleep_for(std::chrono::milliseconds(200 + rnd())) ;
}
int Multiply(const int a, const int b)
{
SimulateHardComputation();
const int res = a * b;
return res;
}| Average time | Minimum time |
|---|---|
 |
 |
We can see that implementation using WinApi and the pthread library is fastest. But I don't think it's correct to compare, because each implementation is good in its own way and is used in different situations.
- C++ Concurrency IN ACTION. Most thread pools`implementations are taken from there.
- C++ references If you don't know how works C++ function's in my code you can read a description.
- WinApi. Full description of WinApi.
pthreadlibrary. Full description ofpthreadlibrary.