13.JavaScript 数据结构与算法(十三)二叉搜索树 #13
Description
二叉搜索树
二叉搜索树(BST,Binary Search Tree),也称为二叉排序树和二叉查找树。
二叉搜索树是一棵二叉树,可以为空。
如果不为空,则满足以下性质:
- 条件 1:非空左子树的所有键值小于其根节点的键值。比如三中节点 6 的所有非空左子树的键值都小于 6;
- 条件 2:非空右子树的所有键值大于其根节点的键值;比如三中节点 6 的所有非空右子树的键值都大于 6;
- 条件 3:左、右子树本身也都是二叉搜索树;

总结:二叉搜索树的特点主要是较小的值总是保存在左节点上,相对较大的值总是保存在右节点上。这种特点使得二叉搜索树的查询效率非常高,这也就是二叉搜索树中“搜索”的来源。
二叉搜索树的封装
二叉搜索树有四个最基本的属性:指向节点的根(root),节点中的键(key)、左指针(right)、右指针(right)。

所以,二叉搜索树中除了定义 root 属性外,还应定义一个节点内部类,里面包含每个节点中的 left、right 和 key 三个属性。
// 节点类
class Node {
constructor(key) {
this.key = key;
this.left = null;
this.right = null;
}
}二叉搜索树的常见操作:
insert(key)向树中插入一个新的键。search(key)在树中查找一个键,如果节点存在,则返回 true;如果不存在,则返回false。preOrderTraverse通过先序遍历方式遍历所有节点。inOrderTraverse通过中序遍历方式遍历所有节点。postOrderTraverse通过后序遍历方式遍历所有节点。min返回树中最小的值/键。max返回树中最大的值/键。remove(key)从树中移除某个键。
插入数据
实现思路:
- 首先根据传入的 key 创建节点对象。
- 然后判断根节点是否存在,不存在时通过:this.root = newNode,直接把新节点作为二叉搜索树的根节点。
- 若存在根节点则重新定义一个内部方法
insertNode()用于查找插入点。
insert(key) 代码实现
// insert(key) 插入数据
insert(key) {
const newNode = new Node(key);
if (this.root === null) {
this.root = newNode;
} else {
this.insertNode(this.root, newNode);
}
}insertNode() 的实现思路:
根据比较传入的两个节点,一直查找新节点适合插入的位置,直到成功插入新节点为止。
-
当 newNode.key < node.key 向左查找:
-
情况 1:当 node 无左子节点时,直接插入:
-
情况 2:当 node 有左子节点时,递归调用 insertNode(),直到遇到无左子节点成功插入 newNode 后,不再符合该情况,也就不再调用 insertNode(),递归停止。
-
-
当 newNode.key >= node.key 向右查找,与向左查找类似:
-
情况 1:当 node 无右子节点时,直接插入:
-
情况 2:当 node 有右子节点时,依然递归调用 insertNode(),直到遇到传入 insertNode 方法 的 node 无右子节点成功插入 newNode 为止。
-
insertNode(root, node) 代码实现
insertNode(root, node) {
if (node.key < root.key) { // 往左边查找插入
if (root.left === null) {
root.left = node;
} else {
this.insertNode(root.left, node);
}
} else { // 往右边查找插入
if (root.right === null) {
root.right = node;
} else {
this.insertNode(root.right, node);
}
}
}遍历数据
这里所说的树的遍历不仅仅针对二叉搜索树,而是适用于所有的二叉树。由于树结构不是线性结构,所以遍历方式有多种选择,常见的三种二叉树遍历方式为:
- 先序遍历;
- 中序遍历;
- 后序遍历;
还有层序遍历,使用较少。
总结
以遍历根(父)节点的顺序来区分三种遍历方式。比如:先序遍历先遍历根节点、中序遍历第二遍历根节点、后续遍历最后遍历根节点。
先序遍历
代码实现:
// 先序遍历(根左右 DLR)
preorderTraversal() {
const result = [];
this.preorderTraversalNode(this.root, result);
return result;
}
preorderTraversalNode(node, result) {
if (node === null) return result;
result.push(node.key);
this.preorderTraversalNode(node.left, result);
this.preorderTraversalNode(node.right, result);
}中序遍历
代码实现:
// 中序遍历(左根右 LDR)
inorderTraversal() {
const result = [];
this.inorderTraversalNode(this.root, result);
return result;
}
inorderTraversalNode(node, result) {
if (node === null) return result;
this.inorderTraversalNode(node.left, result);
result.push(node.key);
this.inorderTraversalNode(node.right, result);
}后序遍历
代码实现:
// 后序遍历(左右根 LRD)
postorderTraversal() {
const result = [];
this.postorderTraversalNode(this.root, result);
return result;
}
postorderTraversalNode(node, result) {
if (node === null) return result;
this.postorderTraversalNode(node.left, result);
this.postorderTraversalNode(node.right, result);
result.push(node.key);
}查找数据
查找最大值或最小值
在二叉搜索树中查找最值非常简单,最小值在二叉搜索树的最左边,最大值在二叉搜索树的最右边。只需要一直向左/右查找就能得到最值
代码实现:
// min() 获取二叉搜索树最小值
min() {
if (!this.root) return null;
let node = this.root;
while (node.left !== null) {
node = node.left;
}
return node.key;
}
// max() 获取二叉搜索树最大值
max() {
if (!this.root) return null;
let node = this.root;
while (node.right !== null) {
node = node.right;
}
return node.key;
}查找特定值
查找二叉搜索树当中的特定值效率也非常高。只需要从根节点开始将需要查找节点的 key 值与之比较,若 node.key < root 则向左查找,若 node.key > root 就向右查找,直到找到或查找到 null 为止。这里可以使用递归实现,也可以采用循环来实现。
代码实现:
// search(key) 查找二叉搜索树中是否有相同的key,存在返回 true,否则返回 false
search(key) {
return this.searchNode(this.root, key);
}
// 通过递归实现
searchNode(node, key) {
if (node === null) return false;
if (key < node.key) {
return this.searchNode(node.left, key);
} else if (key > node.key) {
return this.searchNode(node.right, key);
} else {
return true;
}
}
// 通过 while 循环实现
search2(key) {
let node = this.root;
while (node !== null) {
if (key < node.key) {
node = node.left;
} else if (key > node.key) {
node = node.right;
} else {
return true;
}
}
return false;
}平衡树
二叉搜索树的缺陷:当插入的数据是有序的数据,就会造成二叉搜索树的深度过大。
平衡树
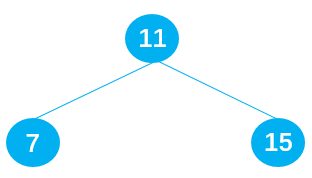
二叉搜索树的缺陷:当插入的数据是有序的数据,就会造成二叉搜索树的深度过大。比如原二叉搜索树由 11 7 15 组成,如下图所示:
当插入一组有序数据:6 5 4 3 2 就会变成深度过大的搜索二叉树,会严重影响二叉搜索树的性能。
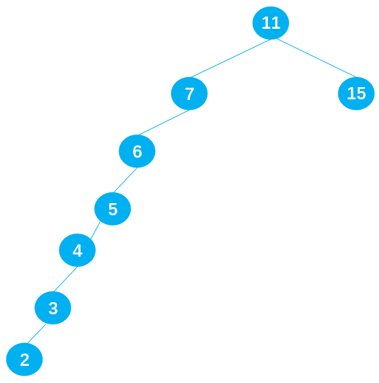
非平衡树
- 比较好的二叉搜索树,它的数据应该是左右均匀分布的。
- 但是插入连续数据后,二叉搜索树中的数据分布就变得不均匀了,我们称这种树为非平衡树。
- 对于一棵平衡二叉树来说,插入/查找等操作的效率是 O(log n)。
- 而对于一棵非平衡二叉树来说,相当于编写了一个链表,查找效率变成了 O(n)。
树的平衡性
为了能以较快的时间 O(log n)来操作一棵树,我们需要保证树总是平衡的:
- 起码大部分是平衡的,此时的时间复杂度也是接近 O(log n) 的;
- 这就要求树中每个节点左边的子孙节点的个数,应该尽可能地等于右边的子孙节点的个数;
常见的平衡树
- AVL 树:是最早的一种平衡树,它通过在每个节点多存储一个额外的数据来保持树的平衡。由于 AVL 树是平衡树,所以它的时间复杂度也是 O(log n)。但是它的整体效率不如红黑树,开发中比较少用。
- 红黑树:同样通过一些特性来保持树的平衡,时间复杂度也是 O(log n)。进行插入/删除等操作时,性能优于 AVL 树,所以平衡树的应用基本都是红黑树。