Questions regarding pgBouncer #1411
Description
Which example are you working with?
I'm not working with an example but I'm trying to setup a basic, single replica cluster with pgBouncer for connection pooling to avoid database disconnects on fail overs. The cluster was created with the following command:
pgo create cluster -n crunchy-test hacluster --pod-anti-affinity="preferred" --replica-count=1 --pgbouncer
What is the current behavior?
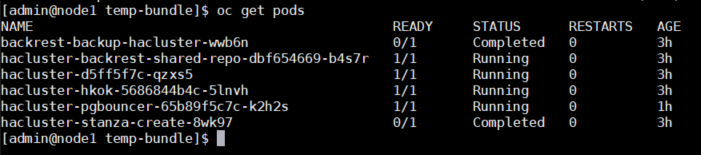
All of the services and pods associated with the cluster correctly run, however the pgBouncer doesn't seem to connect to either the primary or secondary database.
What is the expected behavior?
Unless there is additional required configuration that I am missing (I'm new to pgBouncer and working with PostgreSQL), I believe I should be able to use psql to connect through the pgBouncer Service to the databases such as userdb using psql -U pgbouncer -p 5432 -h hacluster-pgbouncer userdb
Other information (e.g. detailed explanation, related issues, etc)
From within the pgBouncer pod I am able to use psql to connect directly to the hacluster service using: psql -U postgres -p 5432 -h hacluster userdb. I am also able to connect to the 'virtual database' pgBouncer has. I was testing a few queries to see if I was missing something configuration wise, but if I should try something else here please let me know:



Trying to test creating a connection to the userdb within the pgbouncer container resulted in this:

Next, I tested from the hacluster-replica container:

I may be missing something obvious here, or maybe its my lack of understanding on how pgBouncer works, but from the documentation and all that I can find online, adding the --pgbouncer flag seems like it should automatically do all the configuration needed. For an application I should be able to point it to the pgBouncer Service and I guess either provide the pgbouncer credentials or by using pgo create user use those credentials for the application. One additional change I made was adding the replica configuration option to pgbouncer.ini with: {{.PG_REPLICA_SERVICE_NAME}} = host={{.PG_REPLICA_SERVICE_NAME}} port={{.PG_PORT}} auth_user={{.PG_USERNAME}} dbname={{.PG_DATABASE}}
Additionally, I noticed in the Environment variables for pgBouncer deployment that PG_PRIMARY_SERVICE_NAME and PG_REPLICA_SERVICE_NAME were both empty. Should these fields be populated?

Please tell us about your environment:
- Operating System:
Docker images are CentOS7, cluster OS is RHEL7 - Where is this running ( Local , Cloud Provider): Local 3 node OpenShift3.11 Cluster.
- Storage being used (NFS, Hostpath, Gluster, etc): NFS
- Container Image Tag: centos7-4.2.2 and centos7-12.2-4.2.2
- PostgreSQL Version: 12.2
- Platform (Docker, Kubernetes, OpenShift): OpenShift
- Platform Version: 3.11
If possible please run the following on the kubernetes or OpenShift (oc) commands and provide the result:
kubectl describe yourPodName
kubectl describe pvc
kubectl get nodes
kubectl log yourPodName