
Among the biggest problems with RAG applications is their computation retrieval time. Reducing the time involves finding efficient methods for calculating cosine similarity between user query embedding vector and the million, billion, or even trillion other embedding vectors stored in your vector database.
Chunkdot, under the MIT license, is specifically designed for this purpose, offering multi-threaded matrix multiplication for both dense and sparse matrices. It’s suitable for computing the K most similar items for a large number of items by segmenting the item matrix representation (embeddings) and using Numba to accelerate the calculations.
There are many datasets available on HuggingFace that provide embedding vectors of over one million entries such as this dataset from Qdrant. You can use it to test Chunkdot performance. However, for a detailed performance measurement, we will be using the NumPy library to generate random embedding vectors of various dimensions.
We will compare two approaches, one from Chunkdot and the second, a pseudocode of cosine similarity. We’ll observe how performance is affected by increasing the size and dimension. I’ll be using a Kaggle (No GPU) Notebook for this task to ensure consistency.
- 60x Speed Up Your RAG App Today
- Table of Contents
- Setting the stage
- Coding Pseudocode Algorithm
- Coding Chunkdot Algorithm
- Coding Computation Time Function
- Testing for 10k Vector Embeddings
- Testing for 100k Vector Embeddings
- Testing for 1 Million Vector Embeddings
- Visualizing Scalability Impact
- Features of Chunkdot
- What’s Next
Chunkdot requires a similar installation process as any other library.
# installing chunkdot
pip install chunkdotBefore running anything, we must first check the available memory in our Kaggle environment.
# Checking available memory
!free -h
Checking available memory is crucial for Chunkdot. As the vector database size increases, so does the computation memory. To prevent exceeding the available memory, it’s important to monitor the remaining memory in our hardware. In my case the free space is 25GB excluding Buff/Cache.
Let’s import the necessary libraries.
# to matrix generate matrices
import numpy as np
# importing cosine similarity module from chunkdot
from chunkdot import cosine_similarity_top_k
# to calculate computation time
import timeitWe will first construct a pseudocode algorithm that calculates cosine similarities between the user query vector with other millions of vectors that may be stored in the database or locally.
def cosine_pseudocode(query_v, doc_v, num_indices):
"""
Retrieve indices of the highest cosine similarity values between
the query vector and embeddings.
Parameters:
query_v (numpy.ndarray): Query vector.
doc_v (list of numpy.ndarray): List of embedding vectors.
num_indices (int): Number of Top indices to retrieve.
Returns:
list of int: Indices of the highest cosine similarity values.
"""
cosine_similarities = [] # Initialize an empty list to store cosine similarities
query_norm = np.linalg.norm(query_v) # Calculate the norm of the query vector
# Iterate over each documents embedding vectors in the list
for vec in doc_v:
dot_product = np.dot(vec, query_v.T) # Calculate dot product between embedding vector and query vector
embedding_norm = np.linalg.norm(vec) # Calculate the norm of the embedding vector
cosine_similarity = dot_product / (embedding_norm * query_norm) # Calculate cosine similarity
cosine_similarities.append(cosine_similarity) # Append cosine similarity to the list
cosine_similarities = np.array(cosine_similarities) # Convert the list to a numpy array
# Sort the array in descending order
sorted_array = sorted(range(len(cosine_similarities)), key=lambda i: cosine_similarities[i], reverse=True)
# Get indices of the top two values
top_indices = sorted_array[:num_indices]
# Return the indices of highest cosine similarity values
return top_indicesThis cosine similarity function, independent of any library except NumPy, takes three inputs:
-
query_v the embedding vector of the user query
-
doc_v the embedding vectors of documents stored somewhere
-
num_indices the index number from documents for similar top_k results
Now that we’ve coded the pseudocode algorithm, the next step is to code the Chunkdot cosine similarity function.
def cosine_chunkdot(query_v, doc_v, num_indices, max_memory):
"""
Calculate cosine similarity using the chunkdot library.
Parameters:
query_v (numpy.ndarray): Query vector.
doc_v (numpy.ndarray): List of Embedding vectors.
num_indices (int): Number of top indices to retrieve.
max_memory (float): Maximum memory to use.
Returns:
numpy.ndarray: Top k indices.
"""
# Calculate Cosine Similarity
cosine_array = cosine_similarity_top_k(embeddings=query_v, embeddings_right=doc_v,
top_k=num_indices, max_memory=max_memory) # Calculate cosine similarity using chunkdot
# Get indices of the top values
top_indices = cosine_array.nonzero()[1]
# return the top similar results
return top_indicesThis Chunkdot function takes four inputs:
-
query_v the embedding vector of the user query
-
doc_v the embedding vectors of documents stored somewhere
-
num_indices the index number from documents for similar top_k results
-
max_memory represents the available memory you have for computation, with the value in bytes. For example, 1E9 means 1GB, and 10E9 means 10GB, and so on.
Let’s test both of our functions on a sample dataset to observe their outputs.
doc_embeddings = np.random.randn(10, 100) # 10 document embeddings (100 dim)
user_query = np.random.rand(1,100) # 1 user query (100 dim)
top_indices = 1 # number of top indices to retrieve
max_memory = 5E9 # maximum memory to use (5GB)
# retrieve indices of the highest cosine similarity values using pseudocode
print("top indices using pseudocode:", cosine_pseudocode(user_query, doc_embeddings, top_indices))
# retrieve indices of the highest cosine similarity values using chunkdot
print("top indices using chunkdot:", cosine_chunkdot(user_query, doc_embeddings, top_indices, max_memory))
### OUTPUT ###
top indices using pseudocode: [4]
top indices using chunkdot: [4]
### OUTPUT ###I’ve generated 10 random embedding vectors for document embeddings, each of dimension 100, and a user query which is a single embedding vector having the same dimension. The top_indices parameter is set to 1, which means it will return the index of only one similar item from the document embeddings based on the highest cosine similarity. Memory usage has been set to 5E9, which is equal to 5GB. Both of our functions return the same index, 4, indicating that we have accurately coded both functions.
We also need to create a timing function that can measure the computation time taken by both of these functions to output the results.
# calculate time taken
def calculate_execution_time(query_v, doc_v, num_indices, max_memory, times):
# calculate time taken to execute the pseudocode function
pseudocode_time = round(timeit.timeit(lambda: cosine_pseudocode(query_v, doc_v, num_indices), number=times), 5)
# calculate time taken to execute the chunkdot function
chunkdot_time = round(timeit.timeit(lambda: cosine_chunkdot(query_v, doc_v, num_indices, max_memory), number=times), 5)
# print the time taken
print("Time taken for pseudocode function:", pseudocode_time, "seconds")
print("Time taken for chunkdot function:", chunkdot_time, "seconds")We’ve already reviewed the parameters being passed into this function. The only new parameter here is times, which tells the function how many times you want to run the code. Let’s test the efficiency of Chunkdot performance on a larger scale.
We will begin with a reasonable number of document embeddings, 10000, which is comparable to a small-scale domain-specific RAG application. I have set the dimension of each embedding vector as1536 , which is equivalent to OpenAI embedding model text-embedding-3-small .
Let’s calculate the computational time for each approach by running them 100 times.
doc_embeddings = np.random.randn(10000, 1536) # 10K document embeddings (1536 dim)
user_query = np.random.rand(1,1536) # user query (1536 dim)
top_indices = 1 # number of top indices to retrieve
max_memory = 5E9 # maximum memory set to 5GB
# compute the time taken to execute the functions
calculate_execution_time(user_query, doc_embeddings, top_indices, max_memory, 100)For 10k document embeddings, dimension of 1536, running both the algorithms 100 times, here it the comparison:
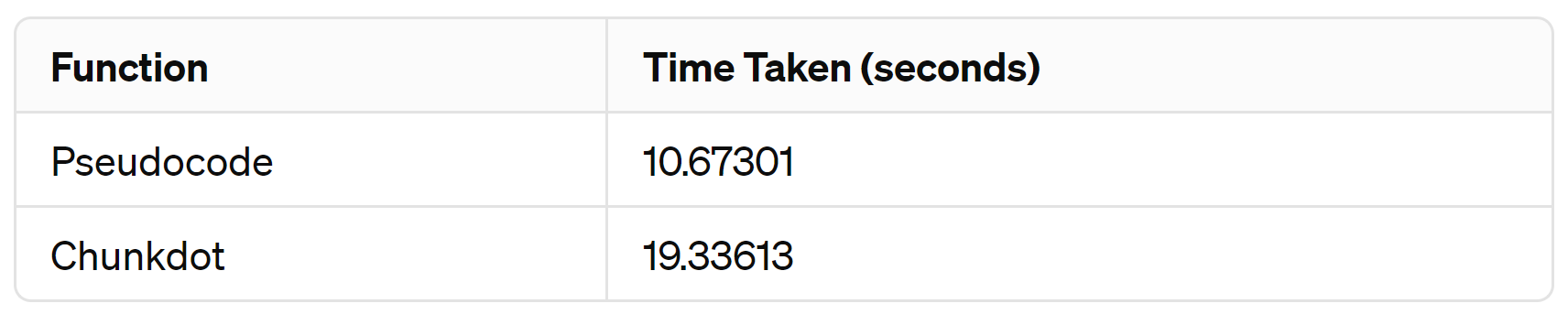
Chunkdot takes more time compared to our pseudocode. This is because it first creates chunks and performs computation on each chunk before merging them. Therefore, for this small-scale example, it may not be a suitable solution. However, you will see the benefits of Chunkdot when we work with a larger example later on.
For 10K our pseudocode approach wins but now let’s increase our document embedding vectors upto 100K vectors, which is comparable to a mid-scale RAG application.
Let’s calculate the computational time for each approach, but this time we are setting the times parameter to 1 (running the code for once) because the number of vectors is quite large, and there is no need to perform the calculation multiple times.
doc_embeddings = np.random.randn(100000, 1536) # 100K document embeddings (1536 dim)
user_query = np.random.rand(1,1536) # user query (1536 dim)
top_indices = 1 # number of top indices to retrieve
max_memory = 5E9 # maximum memory set to 5GB
times = 1 # number of times to execute the functions
# compute the time taken to execute the functions
calculate_execution_time(user_query, doc_embeddings, top_indices, max_memory, times)For 100k document embeddings, dimension of 1536, running both the algorithms single time, here it the comparison:

Chunkdot takes less time compared to our pseudocode, almost half. Now we are seeing the promising impact of Chunkdot.
Working with a task involving millions of embeddings, the first thing you need to check is how much memory the document embedding vectors occupy.
# 1 Million document embeddings (1536 dim)
doc_embeddings = np.random.randn(1000000, 1536)
# user query (1536 dim)
user_query = np.random.rand(1,1536)
# Check the memory size of doc_embeddings and user_query embedding
print(doc_embeddings.nbytes / (1024 * 1024 * 1024),
user_query.nbytes / (1024 * 1024))
Our document embeddings approximately take up 12GB. Let’s check the remaining space available to us.

We have available memory of up to 17GB. To avoid any memory errors, we will set a safe value for the max_memory parameter, i.e., 12GB. Let’s see the results.
# 1 Million document embeddings (1536 dim)
doc_embeddings = np.random.randn(1000000, 1536)
# user query (1536 dim)
user_query = np.random.rand(1,1536)
top_indices = 1 # number of top indices to retrieve
max_memory = 12E9 # maximum memory set to --- 12GB ---
times = 1 # number of times to execute the functions
# compute the time taken to execute the functions
calculate_execution_time(user_query, doc_embeddings, top_indices, max_memory, times)
ChunkDot does indeed reduce computation effectively. When you’re aiming to build a serious RAG app, you should consider starting with at least a million queries. Working with embedding models of higher dimensions, up to 4000. This approach will become even more efficient.
Let’s visualize the impact of increasing the number of document embedding vectors, starting from 10,000 to a very large number.
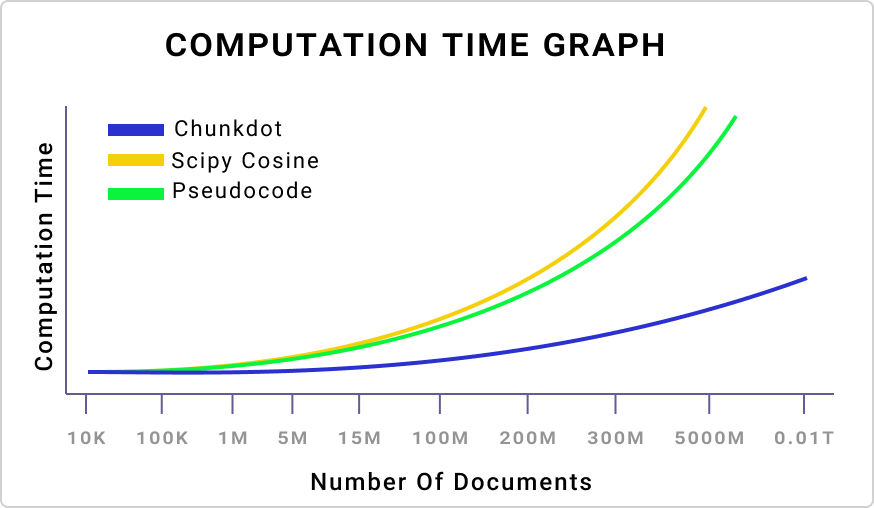
I plotted three methods, and Chunkdot is the most superior among all based on increasing the number of document embeddings. Now, let’s see how the dimension of embedding vectors affects computation time.

I used 100K documents while increasing the dimension of vectors, and the same behavior was observed as we saw when increasing the number of documents.
Chunkdot has a feature where you can display a progress bar, which helps you keep track of how much computation is remaining.
doc_embeddings = np.random.randn(100000, 1536) # 100K document embeddings (1536 dim)
user_query = np.random.rand(1,1536) # user query (1536 dim)
top_indices = 100 # number of top indices to retrieve
max_memory = 5E9 # maximum memory set to 5GB
# with progress bar
output_array = cosine_similarity_top_k(user_query, doc_embeddings,
top_k=top_indices,
show_progress=True)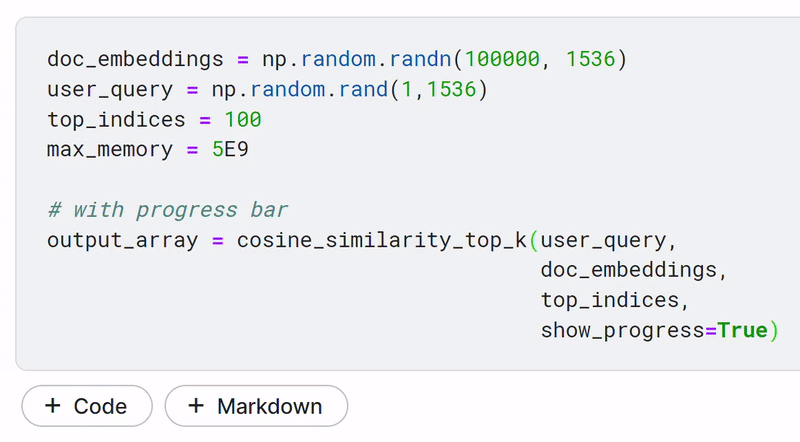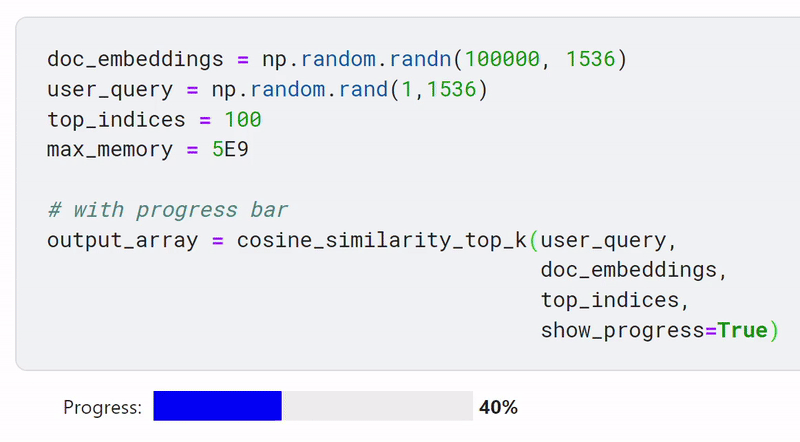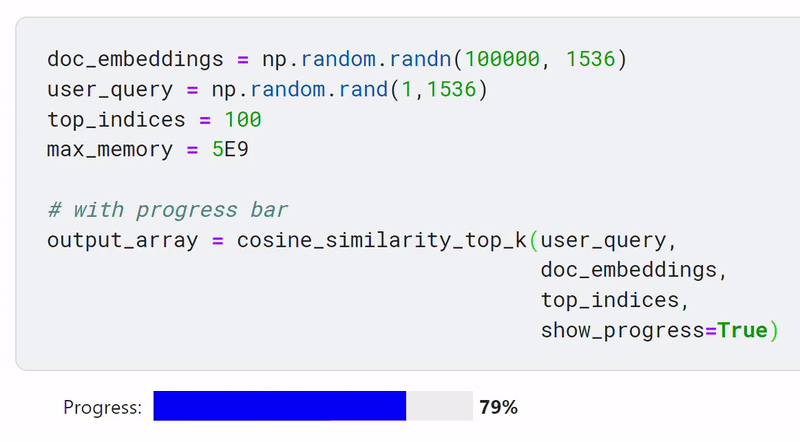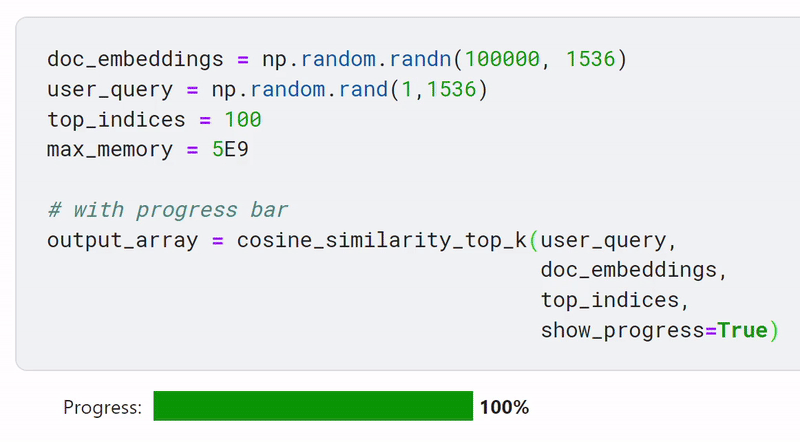
The output of Chunkdot is a sparse matrix, which you can convert into an array using:
# converting the ouput
output_array.toarray()You can use Chunkdot for only document embeddings, which will return the top_k most similar elements for each element of document embeddings.
# total 5 documents embeddings
embeddings = np.random.randn(5, 256)
# return top 2 most similar item index for each
cosine_similarity_top_k(embeddings, top_k=2).toarray()### OUTPUT ###
array([[1. , 0. , 0. , 0. , 0.09924064],
[0. , 1. , 0. , 0.09935381, 0. ],
[0.02358785, 0. , 1. , 0. , 0. ],
[0. , 0.09935381, 0. , 1. , 0. ],
[0.09924064, 0. , 0. , 0. , 1. ]])
### OUTPUT ###Similarly you can return the top most dissimilar items by providing negative value to top_k parameter
# total 5 documents embeddings
embeddings = np.random.randn(5, 256)
# return top 2 most dissimilar item index for each
# Top_K = -2
cosine_similarity_top_k(embeddings, top_k=-2).toarray()### OUTPUT ###
array([[ 0. , 0. , -0.04357524, 0. , -0.05118288],
[ 0. , 0. , 0. , 0.01619543, -0.01836534],
[-0.04357524, 0. , 0. , -0.02466613, 0. ],
[ 0. , 0.01619543, -0.02466613, 0. , 0. ],
[-0.05118288, -0.01836534, 0. , 0. , 0. ]])
### OUTPUT ###This may not be your case, but in case you handle sparse embeddings up to a dimension of 10K, you can use the density parameter to reduce the computation more efficiently.
# for creating sparse embeddings
from scipy import sparse
# creating spare matrix with 100K documents (10K dim each)
# defining density of 0.005
embeddings = sparse.rand(100000, 10000, density=0.005)
# using all you system's memory
cosine_similarity_top_k(embeddings, top_k=50)If you want to learn how the Chunkdot algorithm works, check out this amazing blog from the author. One of the biggest benefits of Chunkdot is that it works on CPU cores. In the future, they plan to integrate GPU support, which will significantly reduce the time for calculations. In case your local environment does not have enough RAM, you can use platforms like Kaggle or GitHub Codespaces, where cloud CPU cores and RAM come at a very low cost compared to GPU costs. Don’t forget to check out the official GitHub repository along with their blog, as it explains extremely well how Chunkdot works.