- Login/Sign Up for IBM Cloud
- Hands-On Guide
- Slides
- Workshop Replay
- Click Here to fill the survey (We really appreciate any feedback :D)
- Follow Our Meetup Page to get updates on our events
- Check IBM Developer to learn and explore a variety technologies and services that you're interested in
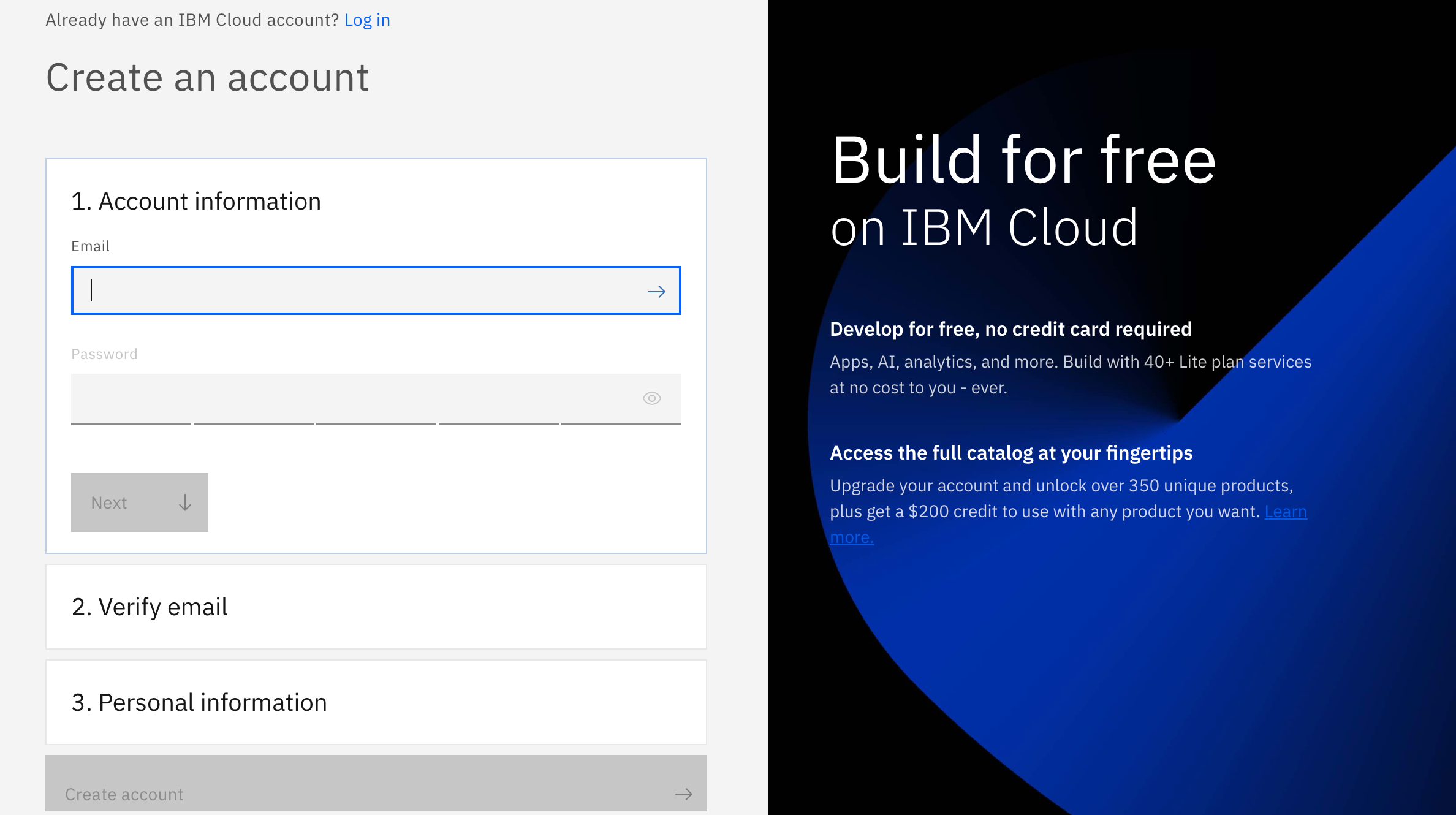
There are 3 steps to create your account on IBM Cloud:
1- Put your email and password.
2- You get a verification link with the registered email to verify your account.
3- Fill the personal information fields.
Automation and artificial intelligence (AI) are transforming businesses and will contribute to economic growth via contributions to productivity. They will also help address challenges in areas of healthcare, technology & other areas. At the same time, these technologies will transform the nature of work and the workplace itself. In this code pattern, we will focus on building state of the art systems for churning out predictions which can be used in different scenarios. We will try to predict fraudulent transactions which we know can reduce monetary loss and risk mitigation. The same approach can be used for predicting customer churn, demand and supply forecast and others. Building predictive models require time, effort and good knowledge of algorithms to create effective systems which can predict the outcome accurately. With that being said, IBM has introduced Auto AI which will automate all the tasks involved in building predictive models for different requirements. We will get to see how Auto AI can churn out great models quickly which will save time and effort and aid in faster decision making process.
When the reader has completed this code pattern, they will understand how to :
- Quickly set up the services on cloud for model building.
- Ingest the data and initiate the Auto AI process.
- Build different models using Auto AI and evaluate the performance.
- Choose the best model and complete the deployment.
- Generate predictions using the deployed model by making REST calls.
- Compare the process of using Auto AI and building the model manually.

- User logs into Watson Studio, creates a project and initiates an instance of Auto AI & Object Storage.
- User uploads the data file in the CSV format to the object storage.
- User initiates the model building process using Auto AI and create pipelines.
- User evaluates different pipelines from Auto AI and selects the best model for deployment.
- User generates accurate predictions by making ReST call to the deployed model.
-
IBM Watson Studio: Analyze data using RStudio, Jupyter, and Python in a configured, collaborative environment that includes IBM value-adds, such as managed Spark.
-
IBM Auto AI:The AutoAI graphical tool in Watson Studio automatically analyzes your data and generates candidate model pipelines customized for your predictive modeling problem.
-
IBM Cloud Object Storage: An IBM Cloud service that provides an unstructured cloud data store to build and deliver cost effective apps and services with high reliability and fast speed to market. This code pattern uses Cloud Object Storage.
- Artificial Intelligence: Any system which can mimic cognitive functions that humans associate with the human mind, such as learning and problem solving.
- Data Science: Systems and scientific methods to analyze structured and unstructured data in order to extract knowledge and insights.
- Analytics: Analytics delivers the value of data for the enterprise.
- Python: Python is a programming language that lets you work more quickly and integrate your systems more effectively.
Follow these steps to setup and run this code pattern using Auto AI.
- Create an account with IBM Cloud
- Create a new Watson Studio project
- Add Data
- Add Asset as Auto AI
- Create and define experiment
- Import the csv file
- Run experiment
- Analyze results
- Deploy to Cloud
- Model testing
Sign up for IBM Cloud. By clicking on create a free account you will get 30 days trial account.
Sign up for IBM's Watson Studio.
Click on New Project and select per below.

Define the project by giving a Name and hit 'Create'.

Clone this repo
Navigate to data and save the file on the disk. Review the data glossary from the data folder for more details. Note: Citation is needed to use this dataset for any other projects.
Click on Assets and select Browse and add the csv file from your file system.

Click on Add to project and select AutoAI experiment.

Note: The Lite account for AutoAI comes with 50 capacity units per month and AutoAI consumes 20 capacity units per hour.
Click on New AutoAI experiment and give a name to the experiment.

Click on Associate a Machine Learning service instance to this project and select the Machine Learning service instance and hit reload. If you do not have Machine Learning service instance, then follow the steps on your screen to get one.
The Create button at the bottom right gets highlighted, go ahead and hit Create.

We need to import the csv file into the experiment. Note that, only csv file format is supported in AutoAI. Click on Browse or Select from project to choose the fraud_dataset.csv file to import.

We have to select the target variable, in this case it is Fraud_Risk. Notice that Prediction Type and Optimized Metric get highlighted which tells us that we are working on Binary Classification use case and the evaluation metric is ROC (Receiver Operating Characteristics) & AUC (Area Under The Curve) which is used for classification usecases.

We can click on experiment settings to adjust the holdout sample and training sample under source settings.

We can click on prediction setting to modify the Prediction type, Positive Class & Optimized metric if required. In this case, we will leave'em as is and hit save and close.

Click on Run experiment.
The AutoAI experiment has been completed in 97 seconds to generate four pipelines. The duration of experiment depends completly on the size of the dataset. AutoAI selects the appropriate machine learning algorithm (in the fifth stage of the process under Model Selection) which is best suited for the dataset.
Each pipeline is run with different parameters, pipeline 3 is run on a sequence of HPO (hyper parameters optimization) & FE (feature engineering) where as pipeline 4 includes HPO (hyper parameters optimization), FE (feature engineering) and a combination of both. All these are done on the fly! Isn't it amazing that we just have to sit and watch while AutoAI takes care of things for us and generates awesome machine learning models!! There's very minimal intervention required to get things going and in no time we have the generated pipelines to choose from.

Click on pipeline 3 (which is ranked 1) to see the evaluation metrics on the left side.

Click on model evaluation to review the performance of the model on the hold out sample and cross validation score. We can observe that our model has done very well by scoring > 95% on Recall, average Precision scores & Area under the curve scores. These scores also mean that our model is able to remember and identify fraudulent transactions with great precision.

Click on feature importance to identify the significant features influencing the outcome. Any variable which starts with Newfeature is a variable generated on the fly by the model as part of feature engineering.

Click on feature transforms to understand the transformation of original features to new features. Feature engineering is one of the important factors in the model building process which has a direct impact on the overall accuracy of the model. We can observe that total features are 24 where as the original dataset had 13 variables which means 11 new features have been created by AutoAI which is one of the reasons for high accuracy of the model.
![]()
After all the analysis of model performance, its time to select the model for deployment. We will go ahead and select pipeline 3 which is Rank 1 and hit on Save as model. We can select any of the pipelines to be saved which has highest Accuracy or any other evaluation metrics.

The saved model can be found under Models under the project in Watson Studio. Click on three dots on the right side below Actions and hit Promote.
Click the Promote to deployment space. Choose an existing deployment space or create a new one. Click Add Deployment.





In the page that opens, fill in the fields: Specify a name for the deployment. Select “Web service” as the Deployment type. Click Save.
Define the deployment by giving a name and hit Save. Note that, the model will get deployed as web service as a ReST API.

After you save the deployment, click on the deployment name from the left navigation pane to view the deployment details page. The deployment will get initialized and the status will show as ready when it is complete.

We can click on deployed model to see three tabs, Overview, Implementation and Test. Overview tab will give all details about the deployment like name, type, status et'al. Implementation tab will give scoring endpoint and code snippets to invoke the model. Test tab will give options to test the model.

Now that we have created and deployed the model as a web service, how do we test it?? We have to click on Test tab which will have two options which are form and json. We can use form if we are to test one record at a time where we can give the values to each attribute manually and hit Predict to generate predictions. The output of 0 under values indicate that it is a fraudulent transaction. The output can be either 0 or 1 as per the data glossary provided in the data folder.

For predicting multiple records, we have to update the values in the json file and use the option to input json data & then hit Predict to generate real time predictions.

A sample json file has been provided for testing purpose. The format for scoring the model has to be same as given in json file. Navigate to data-for-testing and save the file on the disk. Copy and paste the values in the test tab as shown above to generate predictions.
Go ahead and give it a try on different datasets as per your requirement and realize the ease of creating and deploying models quickly using AutoAI offering by IBM.
Follow the below steps to use Jupyter Notebook for building the model. This is to compare the manual process of model building with the automated process using AutoAI.
Create an account with IBM Cloud and then create a project in Watson Studio. Add the data as an asset. These three steps are given above in detail.
- Open IBM Watson Studio.
- Go to the project and click on Add
- Click on
Create notebookto create a notebook. - Select the
From URLtab. - Enter a name for the notebook.
- Optionally, enter a description for the notebook.
- Enter this Notebook URL: https://github.com/IBM/predict-fraud-using-auto-ai/blob/master/notebook/Fraud_Detect.ipynb
- Select the runtime (8 vCPU and 32GB RAM)
- Click the
Createbutton.
After the notebook is imported, click on Not Trusted and select the option as Yes to trust the source of the notebook.

This notebook has been created to demonstrate the steps for building the model using Watson Studio platform. For other usecases, the notebook has to be created from scratch.
Click on 0010 icon at the top right side which will bring up the data assets tab.

Click on Insert to code dropdown and select the option Insert Pandas Dataframe.

When a notebook is executed, what is actually happening is that each code cell in the notebook is executed, in order, from top to bottom.
Each code cell is selectable and is preceded by a tag in the left margin. The tag
format is In [x]:. Depending on the state of the notebook, the x can be:
- A blank, this indicates that the cell has never been executed.
- A number, this number represents the relative order this code step was executed.
- A
*, this indicates that the cell is currently executing.
There are several ways to execute the code cells in your notebook:
- One cell at a time.
- Select the cell, and then press the
Playbutton in the toolbar.
- Select the cell, and then press the
- Batch mode, in sequential order.
- From the
Cellmenu bar, there are several options available. For example, you canRun Allcells in your notebook, or you canRun All Below, that will start executing from the first cell under the currently selected cell, and then continue executing all cells that follow.
- From the
After we run the cells in the notebook which includes data ingestion, data analysis, splitting the data, building the model and generating feature importance, its time to review and analyze the performance. There could be so many other activities like handling missing values, outlier management, feature engineering and hyper parameters optimization which are omitted for demo purpose.
Check the model accuracy and confusion matrix to identify precision and recall scores. We can observe that model has > 92% accuracy on test data and the Precision/Recall scores are also high.

Feature importance as per the model is below. The model has highlighted some of the attributes which has high impact on the outcome. Features might or might not be fairly compared to access the impact on outcome.

We have used shapley values which is a very effective model evaluation technique. Shapley values calculate the importance of a feature by comparing what a model predicts with and without the feature. However, since the order in which a model sees features can affect its predictions, this is done in every possible order, so that the features are fairly compared.

We can observe that attributes like Married, Applicant Income & Credit history available are having high impact on the outcome which is to detect fraud as per shapley values.

With this, we have come to the end of this code pattern where we can compare the ease of using AutoAI to build predictive models vs creating a new jupyter notebook to build and evaluate predictive models. There's considerable reduction of time in building and deploying the models using AutoAI because it handles missing values, outliers, feature engineering & hyper parameters optimization on the fly and selects the best algorithm as per the dataset. AI Model building process has been reduced from Days to Hours thanks to AutoAI. If you are a developer or a data scientist who wants to build the model quickly and deploy it for being production ready, then AutoAI is for you which will help in taking decisions faster and gives a detailed overview of the attribute relationships within the data.
Fraud Prediction using skewed data
The dataset which is referenced in this code pattern is created and owned by R.K.Sharath Kumar, Data Scientist, IBM India Software Labs.
This code pattern is licensed under the Apache Software License, Version 2. Separate third party code objects invoked within this code pattern are licensed by their respective providers pursuant to their own separate licenses. Contributions are subject to the Developer Certificate of Origin, Version 1.1 (DCO) and the Apache Software License, Version 2.
Check the ASL FAQ link for more details
- Login/Sign Up for IBM Cloud
- Hands-On Guide
- Slides
- Workshop Replay
- Click Here to fill the survey (We really appreciate any feedback :D)
- Follow Our Meetup Page to get updates on our events
- Check IBM Developer to learn and explore a variety technologies and services that you're interested in