Looking Backward: Streaming Video-to-Video Translation with Feature Banks
Feng Liang,
Akio Kodaira,
Chenfeng Xu,
Masayoshi Tomizuka,
Kurt Keutzer,
Diana Marculescu
Our StreamV2V could perform real-time video-2-video translation on one RTX 4090 GPU. Check the video and try it by yourself!
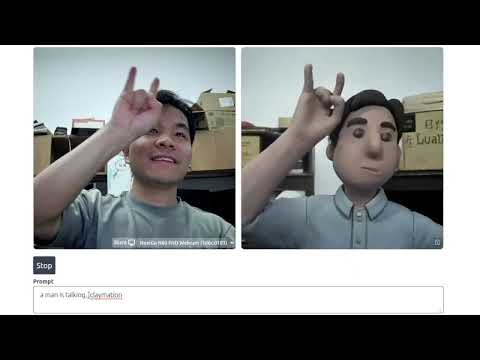
For functionality, our StreamV2V supports face swap (e.g., to Elon Musk or Will Smith) and video stylization (e.g., to Claymation or doodle art). Check the video and reproduce the results!

Although StreamV2V is designed for the vid2vid task, it could seamlessly integrate with the txt2img application. Compared with per-image StreamDiffusion, StreamV2V continuously generates images from texts, providing a much smoother transition. Check the video and try it by yourself!

Please see the installation guide.
Please see getting started instruction.
Please see the demo with camera guide.
Please see the demo continuous txt2img.
StreamV2V is licensed under a UT Austin Research LICENSE.
Our StreamV2V is highly dependended on the open-source community. Our code is copied and adapted from < StreamDiffusion with LCM-LORA. Besides the base SD 1.5 model, we also use a variaty of LORAs from CIVITAI.
If you use StreamV2V in your research or wish to refer to the baseline results published in the paper, please use the following BibTeX entry.
@article{liang2024looking,
title={Looking Backward: Streaming Video-to-Video Translation with Feature Banks},
author={Liang, Feng and Kodaira, Akio and Xu, Chenfeng and Tomizuka, Masayoshi and Keutzer, Kurt and Marculescu, Diana},
journal={arXiv preprint arXiv:2405.15757},
year={2024}
}
@article{kodaira2023streamdiffusion,
title={StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation},
author={Kodaira, Akio and Xu, Chenfeng and Hazama, Toshiki and Yoshimoto, Takanori and Ohno, Kohei and Mitsuhori, Shogo and Sugano, Soichi and Cho, Hanying and Liu, Zhijian and Keutzer, Kurt},
journal={arXiv preprint arXiv:2312.12491},
year={2023}
}