Accepted at Towards learning with limited labels Workshop, ICML 2018, Stockholm, Sweden. (Link)
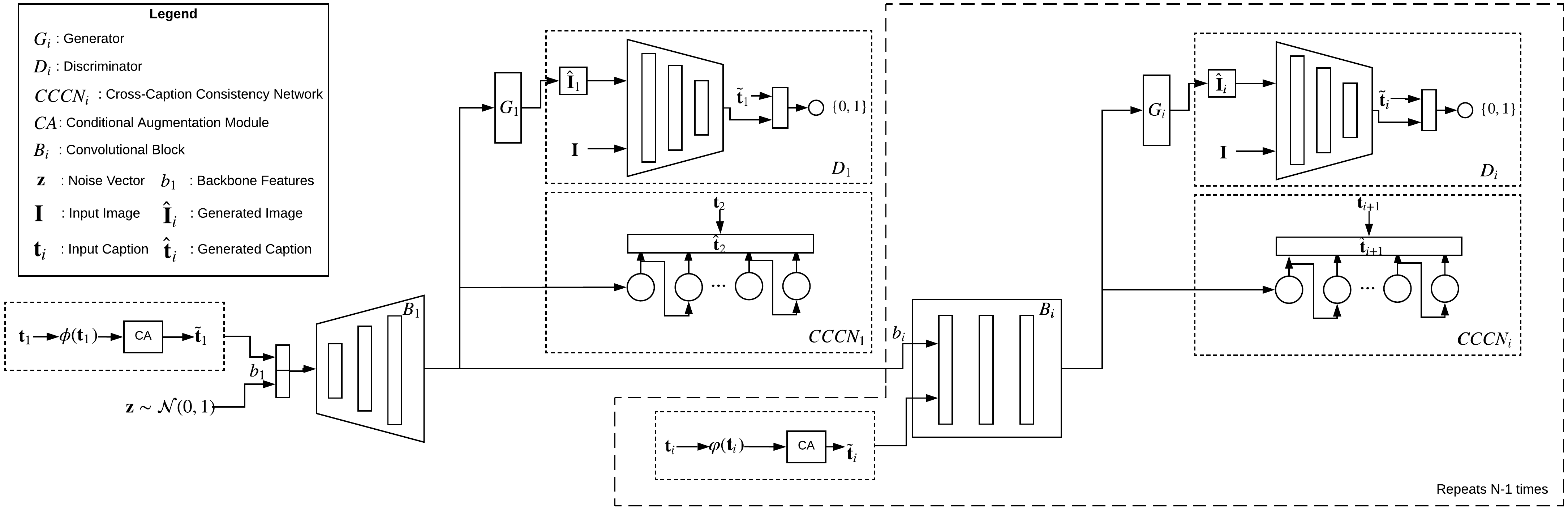
Existing methods for generating an image from its description, use one single caption to generate a plausible image. A single caption by itself, would not be able to capture the variety of concepts that might be present in the image. We propose a generative model that will iteratively improve the concepts, and thereby the quality of the generated image by making use of multiple captions about a single image. This is achieved by ensuring `cross-caption cycle consistency' between the captions and the intermediate image representations. We report quantitative and qualitative results to bring out the efficacy of the proposed approach in zero-shot image generations, where images are generated from descriptions of novel classes that are not seen during training.

Build on top of:
- Pytorch
- Python 2.7
Main File
- main.py
References
- StackGAN v2: Code