Optionally use UInt8 for various chars #88
Conversation
Codecov Report
@@ Coverage Diff @@
## master #88 +/- ##
==========================================
+ Coverage 74.76% 75.24% +0.48%
==========================================
Files 11 11
Lines 1153 1224 +71
==========================================
+ Hits 862 921 +59
- Misses 291 303 +12
Continue to review full report at Codecov.
|

|
Can this be done in a way that does not require ASCII? Like maybe with an AsciiChar type that we use if the given delim is in fact ascii. |
|
But that does mean we pay compilation cost |
8a1b708 to
aaed63c
Compare
467132b to
35bd9e1
Compare
|
Alright, this is ready for review. It needs a VERY careful review, because I'm quite nervous about some of the changes I made in particular about how the global config for things like The main difference here is how I've changed the handling of all "global default" choices for Having said that, in terms of performance, things are looking very good. With this PR here and #95, I get the following performance numbers, which are excellent: The benchmarks with missing data look slightly less good (and are not posted here), but then we can still give the But the short version of a long story is that we are now essentially en par with R fread single threaded. We'll probably get a little bit worse again once we address #79, but the profiler also indicated a number of other areas where there might still be room for improvements.
Done, one can now either use a
I think like 98% of users will use ASCII characters for this, and so in all those cases we'll end up with one specialized code path that uses the |
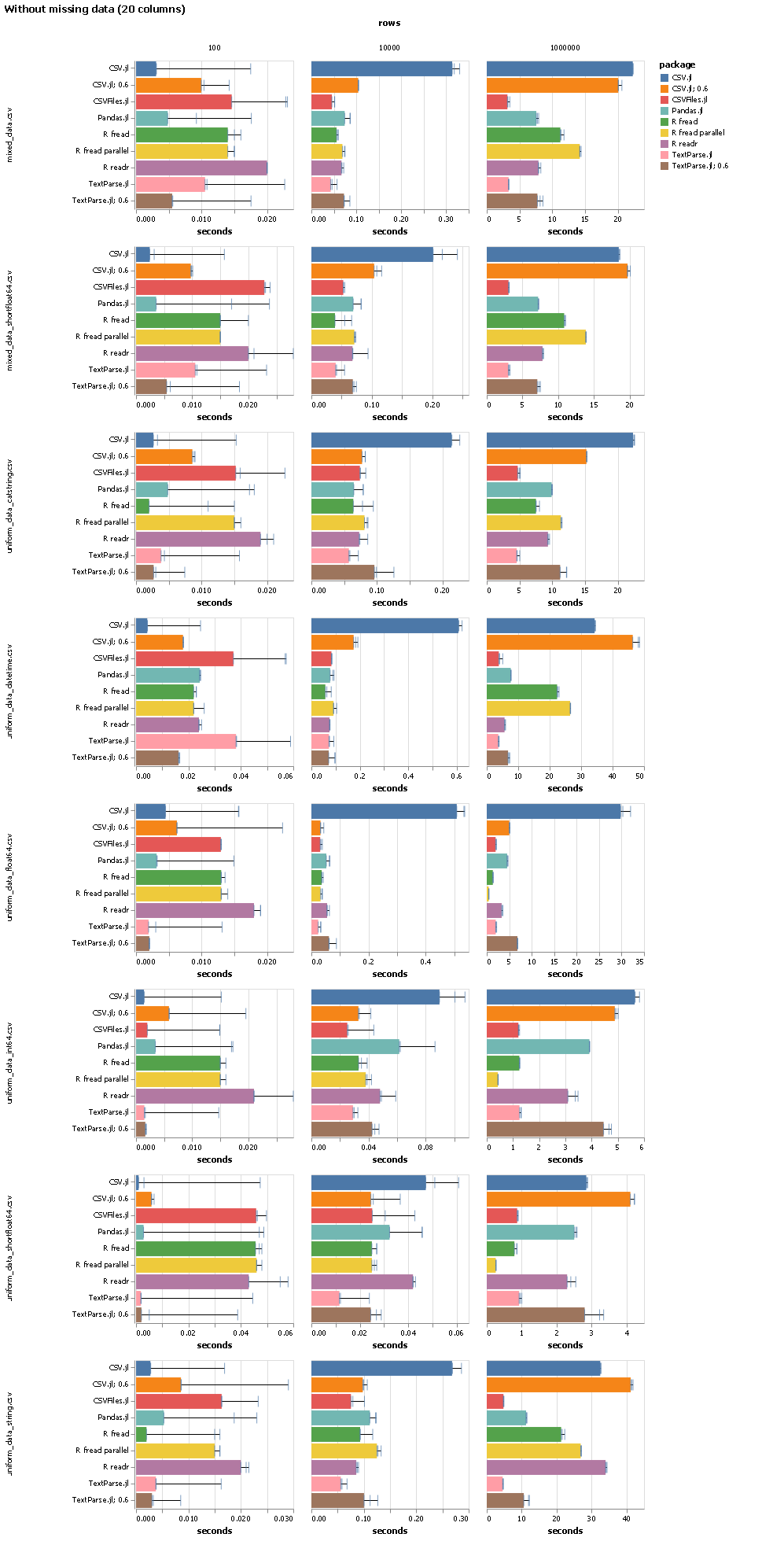
|
Awesome!! Is there a comparison of how much speed up this PR gives over TextParse master? I'm just curious. |
This PR: |
|
Good stuff @davidanthoff ! |
Before I go on with this, I wanted to get some feedback whether folks are ok with this. If we limit things like
delimto ASCII characters, we can speed up things by quite a bit again. I tested this branch with my comprehensive test suite, and while I don't remember the precise improvement, it was pretty sizable.If folks are ok with that, I would probably also change some of the other special characters to ASCII only, which should give us a bit more performance, and then it would be ready to merge.
@shashi any thoughts?