Peramalan harga rumah merupakan salah satu aspek penting dalam industri properti. Dengan adanya prediksi yang akurat, pembeli dan penjual dapat membuat keputusan yang lebih informasi, sementara investor dapat mengidentifikasi peluang pasar yang potensial. Namun, harga rumah dipengaruhi oleh berbagai faktor seperti lokasi, ukuran, fasilitas, dan kondisi pasar saat itu, yang membuatnya menjadi masalah yang kompleks untuk diprediksi secara akurat.
Masalah prediksi harga rumah harus diselesaikan karena:
- Pengambilan Keputusan yang Lebih Baik: Pembeli dapat menentukan harga yang wajar, sedangkan penjual dapat menetapkan harga jual yang kompetitif.
- Optimalisasi Investasi: Investor dapat mengidentifikasi area dengan potensi pertumbuhan nilai properti yang tinggi.
- Efisiensi Pasar: Meminimalkan ketidakefisienan dalam pasar properti dengan menyediakan data yang akurat dan transparan.
- "House Price Prediction Using Machine Learning Algorithms"
- Menyediakan wawasan tentang penggunaan berbagai algoritma dalam prediksi harga rumah.
- "An Overview of Real Estate Modelling Techniques for House Price Prediction"
- Menjelaskan teknik pemodelan yang berbeda dan bagaimana mereka diterapkan dalam konteks real estat.
- Pernyataan Masalah 1: Bagaimana memprediksi harga jual rumah berdasarkan fitur-fitur seperti lokasi, ukuran, dan fasilitas?
- Pernyataan Masalah 2: Apa faktor-faktor utama yang paling mempengaruhi harga rumah di pasar saat ini?
- Pernyataan Masalah 3: Bagaimana meningkatkan akurasi model prediksi harga rumah dengan menggunakan teknik machine learning yang tepat?
- Jawaban Pernyataan Masalah 1: Mengembangkan model machine learning yang dapat memprediksi harga jual rumah dengan akurasi tinggi menggunakan dataset yang tersedia.
- Jawaban Pernyataan Masalah 2: Mengidentifikasi dan menganalisis fitur-fitur yang paling berpengaruh terhadap harga rumah.
- Jawaban Pernyataan Masalah 3: Menerapkan teknik peningkatan model seperti hyperparameter tuning untuk meningkatkan performa prediksi.
- Menggunakan Algoritma Regresi Linear dan Random Forest: Membandingkan performa kedua algoritma ini dalam memprediksi harga rumah.
- Hyperparameter Tuning pada Random Forest: Mengoptimalkan parameter model untuk meningkatkan akurasi prediksi.
Dataset yang digunakan dalam proyek ini adalah Kaggle House Prices Dataset, yang sangat populer dalam kompetisi prediksi harga rumah. Data ini mencakup detail-detail berikut:
- Jumlah Data: Dataset terdiri dari 1460 baris (sampel) dan 81 kolom (fitur).
- Kondisi Data: Data memiliki beberapa tantangan seperti nilai-nilai yang hilang di beberapa kolom penting seperti
LotFrontagedanGarageYrBlt, serta adanya outliers terutama dalam fiturSalePricedanGrLivArea. - Pembagian Data: Dataset telah dibagi menjadi dua set:
- Data Train: Digunakan untuk melatih model, berisi sekitar 80% dari data keseluruhan.
- Data Test: Digunakan untuk menguji model, berisi sekitar 20% dari data keseluruhan.
Dataset mencakup berbagai fitur yang mempengaruhi harga rumah, yang dapat dikategorikan sebagai berikut:
- Fitur Fundamental: Termasuk
MSSubClass,MSZoning,LotFrontage,LotArea, dan lainnya yang mendeskripsikan karakteristik dasar properti. - Fitur Kualitas dan Kondisi: Seperti
OverallQual,OverallCond,RoofStyle,ExterQual, yang menilai kualitas dan kondisi dari berbagai aspek rumah. - Fitur Ruang:
BedroomAbvGr,KitchenAbvGr,TotRmsAbvGrd, yang memberikan informasi tentang jumlah ruang dalam rumah. - Fitur Tahun:
YearBuilt,YearRemodAdd, yang mencatat tahun dibangun dan tahun terakhir rumah tersebut direnovasi. - Fitur Luas:
1stFlrSF,2ndFlrSF,TotalBsmtSF, yang mengukur luas area tertentu dalam rumah.
- SalePrice - Harga jual properti dalam dolar. (Ini adalah variabel target yang ingin diprediksi.)
- MSSubClass: Kelas bangunan
- MSZoning: Klasifikasi zonasi umum
- LotFrontage: Panjang garis depan lahan yang terhubung ke jalan dalam satuan kaki
- LotArea: Ukuran lahan dalam kaki persegi
- Street: Jenis akses jalan
- Alley: Jenis akses gang
- LotShape: Bentuk umum properti
- LandContour: Kontur tanah (kemiringan atau tingkat ketinggian) properti
- Utilities: Jenis utilitas yang tersedia
- LotConfig: Konfigurasi lahan
- LandSlope: Kemiringan tanah properti
- Neighborhood: Lokasi fisik dalam batas kota Ames
- Condition1: Kedekatan dengan jalan utama atau rel kereta api
- Condition2: Kedekatan tambahan dengan jalan utama atau rel kereta api (jika ada)
- BldgType: Jenis bangunan tempat tinggal
- HouseStyle: Gaya arsitektur rumah
- OverallQual: Kualitas material dan penyelesaian secara keseluruhan
- OverallCond: Penilaian kondisi secara keseluruhan
- YearBuilt: Tahun pembangunan asli
- YearRemodAdd: Tahun renovasi terakhir
- RoofStyle: Gaya atap
- RoofMatl: Material atap
- Exterior1st: Penutup eksterior utama pada rumah
- Exterior2nd: Penutup eksterior tambahan pada rumah (jika lebih dari satu material)
- MasVnrType: Jenis veneer batu
- MasVnrArea: Luas veneer batu dalam kaki persegi
- ExterQual: Kualitas material eksterior
- ExterCond: Kondisi material eksterior saat ini
- Foundation: Jenis fondasi
- BsmtQual: Kualitas ketinggian basement
- BsmtCond: Kondisi umum basement
- BsmtExposure: Paparan dinding basement (misalnya, walkout atau level taman)
- BsmtFinType1: Kualitas area basement yang telah selesai
- BsmtFinSF1: Luas area basement yang telah selesai tipe 1 dalam kaki persegi
- BsmtFinType2: Kualitas area basement yang telah selesai tipe 2 (jika ada)
- BsmtFinSF2: Luas area basement yang telah selesai tipe 2 dalam kaki persegi
- BsmtUnfSF: Luas area basement yang belum selesai dalam kaki persegi
- TotalBsmtSF: Total luas area basement dalam kaki persegi
- Heating: Jenis sistem pemanas
- HeatingQC: Kualitas dan kondisi sistem pemanas
- CentralAir: Sistem pendingin udara sentral
- Electrical: Sistem kelistrikan
- 1stFlrSF: Luas lantai pertama dalam kaki persegi
- 2ndFlrSF: Luas lantai kedua dalam kaki persegi
- LowQualFinSF: Luas area selesai berkualitas rendah (semua lantai) dalam kaki persegi
- GrLivArea: Luas area hunian di atas tanah (ground) dalam kaki persegi
- BsmtFullBath: Jumlah kamar mandi lengkap di basement
- BsmtHalfBath: Jumlah kamar mandi setengah di basement
- FullBath: Jumlah kamar mandi lengkap di atas tanah
- HalfBath: Jumlah kamar mandi setengah di atas tanah
- Bedroom: Jumlah kamar tidur di atas basement
- Kitchen: Jumlah dapur
- KitchenQual: Kualitas dapur
- TotRmsAbvGrd: Total jumlah kamar di atas tanah (tidak termasuk kamar mandi)
- Functional: Penilaian fungsionalitas rumah
- Fireplaces: Jumlah perapian
- FireplaceQu: Kualitas perapian
- GarageType: Jenis garasi
- GarageYrBlt: Tahun pembangunan garasi
- GarageFinish: Penyelesaian interior garasi
- GarageCars: Kapasitas garasi dalam jumlah mobil
- GarageArea: Luas garasi dalam kaki persegi
- GarageQual: Kualitas garasi
- GarageCond: Kondisi garasi
- PavedDrive: Jenis jalan masuk (beraspal atau tidak)
- WoodDeckSF: Luas dek kayu dalam kaki persegi
- OpenPorchSF: Luas teras terbuka dalam kaki persegi
- EnclosedPorch: Luas teras tertutup dalam kaki persegi
- 3SsnPorch: Luas teras tiga musim dalam kaki persegi
- ScreenPorch: Luas teras berpantai (dilengkapi layar) dalam kaki persegi
- PoolArea: Luas kolam renang dalam kaki persegi
- PoolQC: Kualitas kolam renang
- Fence: Kualitas pagar
- MiscFeature: Fitur tambahan yang tidak tercakup dalam kategori lain
- MiscVal: Nilai fitur tambahan dalam dolar
- MoSold: Bulan penjualan
- YrSold: Tahun penjualan
- SaleType: Jenis penjualan
- SaleCondition: Kondisi penjualan
Analisis eksploratif data dilakukan untuk mendapatkan insight lebih dalam tentang distribusi dan hubungan antar variabel dalam dataset:
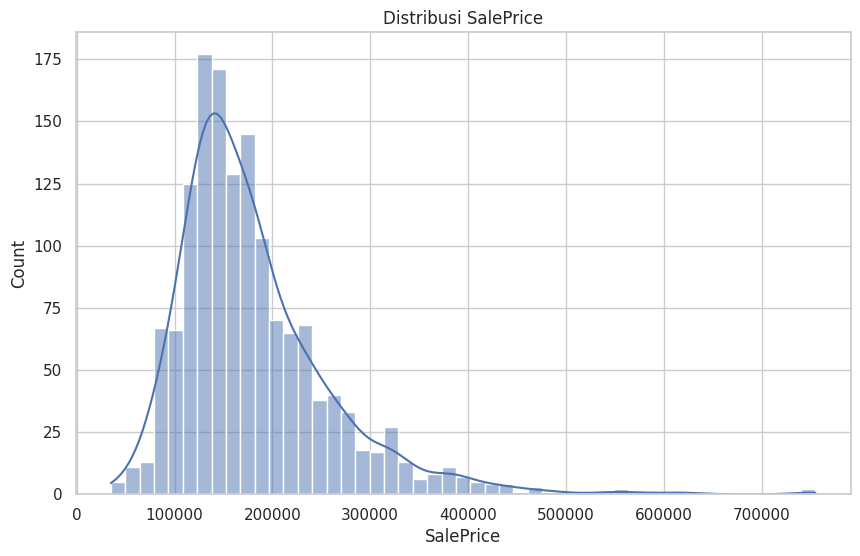
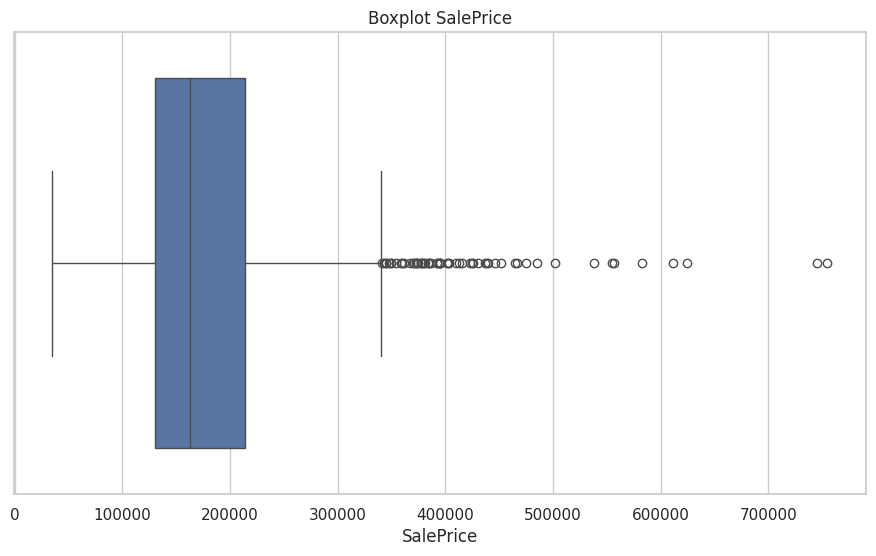
- Visualisasi Distribusi Data: Histogram dan boxplot digunakan untuk mengevaluasi distribusi dan mengidentifikasi outliers. Misalnya,
SalePricemenunjukkan skewness positif yang menandakan adanya harga rumah yang sangat tinggi sebagai outliers.
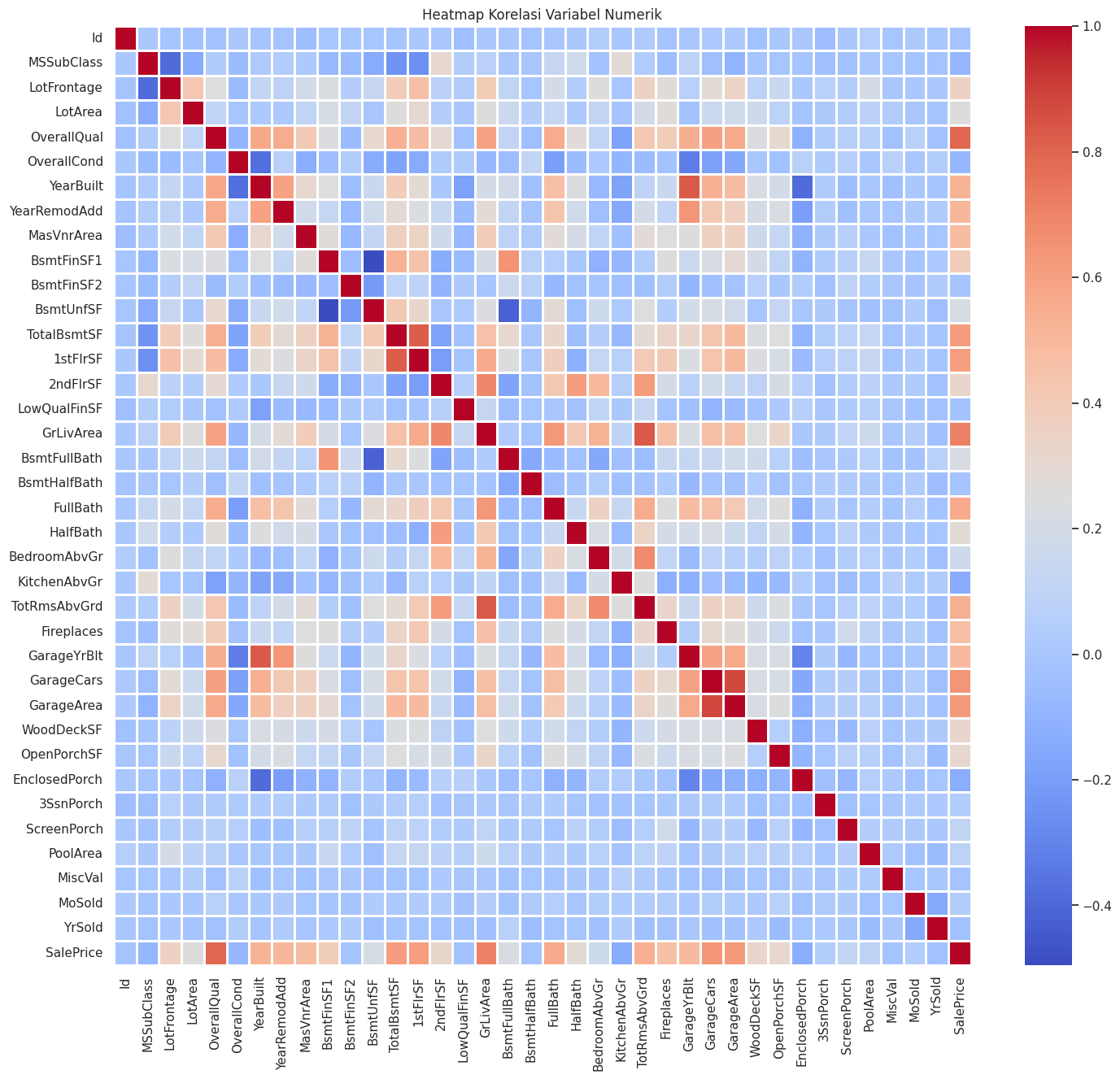
- Korelasi dan Heatmap: Dari heatmap, kita dapat melihat hubungan kuat antara
OverallQualdenganSalePriceserta antaraGrLivAreadenganSalePrice, menunjukkan bahwa kualitas umum rumah dan luas area tinggal adalah faktor penting dalam penentuan harga.
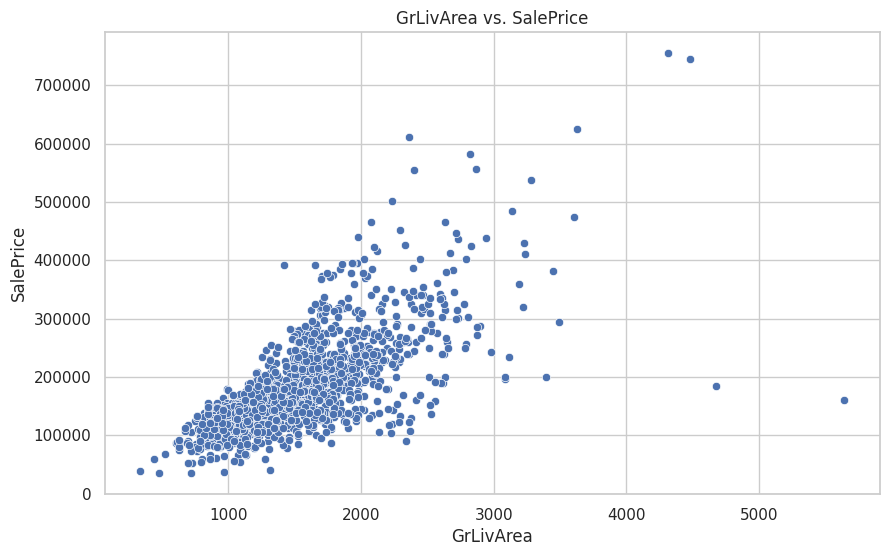
- Scatter plot antara
GrLivAreadanSalePrice: Scatter plot menunjukkan hubungan linear positif antara luas area tinggal dan harga, tetapi juga mengidentifikasi beberapa outliers yang memiliki luas area tinggal yang besar dengan harga yang tidak proporsional.
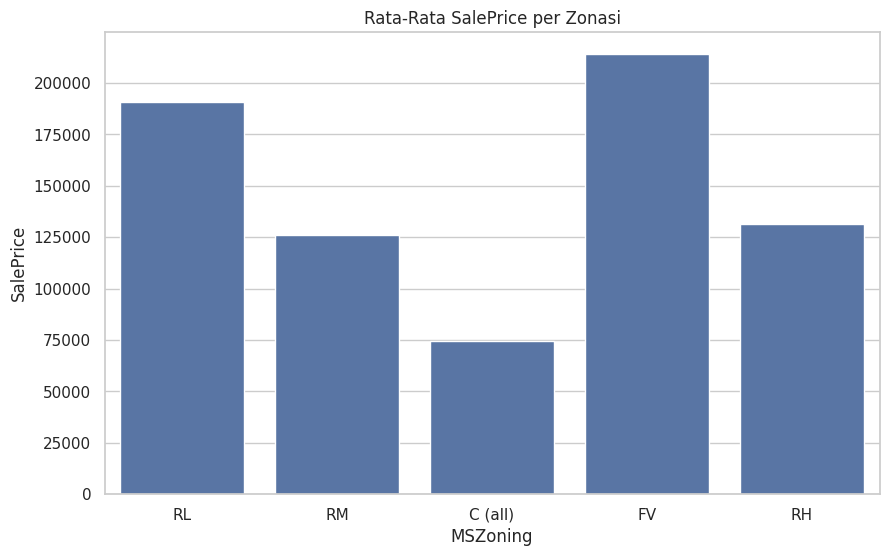
-
menggambarkan rata-rata harga jual (
SalePrice) per zona (MSZoning), kita dapat melihat beberapa insight menarik:-
Zona FV (Floodplain Residential) memiliki harga jual rata-rata tertinggi dibandingkan dengan zona lainnya. Hal ini bisa menunjukkan bahwa properti di zona banjir ini mungkin memiliki fitur atau atribut yang dianggap sangat berharga oleh pasar, seperti kualitas bangunan yang lebih tinggi atau infrastruktur komunitas yang lebih baik.
-
Zona RL (Residential Low Density) juga menunjukkan harga rata-rata yang tinggi, mengindikasikan bahwa zona residensial dengan kepadatan rendah ini mungkin memiliki rumah yang lebih besar atau lebih banyak ruang terbuka yang menarik bagi pembeli.
-
Zona C (all) (Commercial) memiliki harga rata-rata yang paling rendah, yang bisa jadi karena fitur-fitur yang umumnya kurang diinginkan untuk kehidupan residensial, seperti kebisingan yang lebih tinggi atau akses yang kurang ke fasilitas-fasilitas seperti sekolah atau taman.
-
Zona RH (Residential High Density) dan RM (Residential Medium Density) menunjukkan harga rata-rata yang lebih rendah dibandingkan dengan RL, yang bisa jadi karena rumah-rumah di zona ini mungkin lebih kecil atau memiliki kurang ruang pribadi yang menjadi faktor penting dalam penentuan harga.
-
Dari analisis yang dilakukan, beberapa temuan penting adalah:
- Kualitas dan Ukuran sebagai Determinan Utama Harga: Kualitas keseluruhan dan ukuran area hunian adalah dua faktor yang sangat mempengaruhi harga rumah.
- Potensi untuk Feature Engineering: Mengingat pentingnya tahun pembangunan dan kondisi saat ini, pengembangan fitur seperti
HouseAgeatau penilaian kondisi terkini dapat membantu dalam meningkatkan prediksi harga. - Perlunya Penanganan Outliers: Outliers terutama dalam
SalePricedanGrLivAreaperlu ditangani untuk meningkatkan keakuratan model prediktif.
Data preparation adalah tahap krusial dalam pembuatan model Machine Learning karena kualitas data secara langsung mempengaruhi performa model. Berikut adalah tahapan yang dilakukan untuk mempersiapkan data:
-
Handling Missing Values:
- Nilai yang hilang diimputasi berdasarkan tipe data masing-masing kolom. Untuk variabel numerik, digunakan nilai rata-rata (mean), dan untuk variabel kategorikal, digunakan modus (mode).
- Alasan: Mengimputasi nilai hilang mencegah model dari bias yang bisa terjadi jika baris atau kolom yang mengandung nilai hilang dihapus secara keseluruhan, memungkinkan pemanfaatan data maksimal tanpa kehilangan informasi penting.
-
Encoding Kategorikal:
- Variabel kategorikal diubah menjadi numerik menggunakan teknik One-Hot Encoding.
- Alasan: Kebanyakan algoritma machine learning tidak dapat memproses label teks langsung, sehingga perlu mengubahnya menjadi format numerik. One-Hot Encoding memungkinkan model untuk menginterpretasikan fitur kategorikal tanpa mengasumsikan urutan dalam data.
-
Feature Scaling:
- Fitur numerik dinormalisasi menggunakan skala standar (standard scaling) sehingga semua fitur memiliki rata-rata nol dan standar deviasi satu.
- Alasan: Normalisasi memastikan bahwa fitur dengan skala besar tidak mendominasi cara model belajar, yang bisa mempengaruhi performa model secara negatif. Dengan scaling, kita juga memastikan bahwa algoritma yang sensitif terhadap skala fitur, seperti algoritma berbasis gradien, beroperasi dengan lebih efisien.
-
Feature Engineering:
- Membuat fitur baru, seperti 'Age of House' yang dihitung dari selisih tahun saat ini dengan tahun dibangunnya rumah (
Current Year - YearBuilt). - Alasan: Fitur baru seringkali dapat memberikan wawasan tambahan yang tidak tersedia secara langsung dari data yang ada. Dalam kasus ini, usia rumah bisa sangat relevan dengan harga pasar.
- Membuat fitur baru, seperti 'Age of House' yang dihitung dari selisih tahun saat ini dengan tahun dibangunnya rumah (
-
Splitting Data: Data dibagi menjadi dua set, yaitu training set dan testing set. Proporsi pembagian adalah 80% untuk training dan 20% untuk testing. Splitting ini penting untuk memvalidasi model pada data yang tidak terlibat dalam proses training, yang membantu dalam menilai kemampuan generalisasi model.
Setiap langkah dalam data preparation didesain untuk mengatasi masalah khusus dalam data atau untuk membuat data lebih amenable untuk modeling. Dengan melakukan imputasi, encoding, scaling, dan engineering, kami meminimalkan risiko overfitting, mempermudah model untuk belajar dari data, dan meningkatkan kemungkinan mendapatkan prediksi yang akurat.
-
Parameter:
- fit_intercept: Boolean, menentukan apakah menghitung intersep atau mengasumsikan data telah terpusat.
- regularization: Jika digunakan, menentukan tipe regularisasi (L1, L2, atau ElasticNet) untuk menghindari overfitting.
-
Cara Kerja:
- Regresi Linear bekerja dengan asumsi hubungan linear antara variabel independen (fitur) dan variabel dependen (harga rumah).
- Model ini mencoba menemukan garis terbaik (hyperplane pada multidimensional) yang meminimalkan kesalahan kuadrat antara nilai prediksi dan nilai sebenarnya dari variabel target.
- Matematis, hal ini dicapai dengan menyesuaikan koefisien (berat) untuk setiap fitur sedemikian rupa sehingga kesalahan kuadrat total antara prediksi dan nilai sebenarnya minimal.
-
Parameter:
- n_estimators: Jumlah pohon dalam hutan (forest). Lebih banyak pohon dapat meningkatkan performa tetapi memerlukan waktu komputasi lebih lama.
- max_depth: Kedalaman maksimum setiap pohon. Kedalaman yang lebih besar dapat meningkatkan kemampuan model untuk belajar dari data tetapi bisa menyebabkan overfitting.
- min_samples_split: Jumlah sampel minimal yang diperlukan untuk membagi node internal.
-
Cara Kerja:
- Random Forest adalah algoritma ensemble yang menggunakan banyak pohon keputusan (decision trees) untuk membuat prediksi lebih akurat dan stabil.
- Untuk prediksi harga rumah, setiap pohon dalam Random Forest membuat prediksi secara independen, dan hasil akhir adalah rata-rata dari semua prediksi pohon, yang mengurangi varians dan risiko overfitting.
- Random Forest juga menggunakan teknik bagging (Bootstrap Aggregating) untuk meningkatkan stabilitas dan akurasi model. Dalam proses ini, setiap pohon dibangun dari sampel acak dataset dengan penggantian, yang membantu model menjadi robust terhadap noise dalam data.
- Selain itu, pada setiap split dalam pembuatan pohon, hanya subset dari fitur yang dipilih secara acak, yang membantu dalam mengurangi korelasi antar pohon dan meningkatkan variasi dalam prediksi yang dihasilkan.
- Melakukan hyperparameter tuning pada Random Forest menggunakan GridSearchCV untuk menemukan kombinasi parameter yang optimal, seperti jumlah estimator dan kedalaman pohon, yang meningkatkan akurasi prediksi.
- Setelah membandingkan kedua model, Random Forest dipilih sebagai model terbaik karena memberikan akurasi yang lebih tinggi dan kemampuan untuk menangani variabel yang kompleks.
- Mean Absolute Error (MAE): Mengukur rata-rata kesalahan absolut prediksi.
- Root Mean Squared Error (RMSE): Mengukur rata-rata kesalahan kuadrat prediksi.
- R-squared (R²): Mengukur proporsi variansi dalam target variabel yang dapat dijelaskan oleh model.
-
Regresi Linear:
- MAE: 71626725.05946156
- RMSE: 561776962.9145709
- R²: 2.3697161860525683e+19
-
Random Forest Regressor:
- MAE: 0.024468779355226525
- RMSE: 0.04735156584604528
- R²: 0.831640676004802
-
MAE untuk Random Forest menunjukkan kesalahan prediksi yang sangat rendah dibandingkan dengan Regresi Linear, yang berarti model Random Forest rata-rata memiliki kesalahan absolut yang lebih kecil dalam setiap prediksi yang dibuat.
-
RMSE menunjukkan bahwa kesalahan prediksi pada Random Forest secara keseluruhan lebih kecil dibandingkan dengan Regresi Linear, mengindikasikan bahwa kesalahan besar lebih jarang terjadi pada model Random Forest.
-
R² dari Random Forest adalah 0.832, yang menunjukkan bahwa sekitar 83.2% dari variansi dalam harga rumah dapat dijelaskan oleh variabel-variabel dalam model Random Forest. Ini lebih tinggi dibandingkan dengan Regresi Linear yang hanya menjelaskan 75%, menunjukkan bahwa Random Forest secara keseluruhan adalah model yang lebih efektif dalam menggambarkan data harga rumah ini.
Formula untuk Mean Absolute Error (MAE) adalah sebagai berikut:
dimana:
- (
$n$ ) adalah jumlah sampel, - (
$y_i$ ) adalah nilai sebenarnya, - (
$\hat{y}_i$ ) adalah nilai prediksi.
Formula untuk Mean Squared Error (MSE) adalah sebagai berikut:
dimana:
- (
$n$ ) adalah jumlah sampel, - (
$y_i$ ) adalah nilai sebenarnya, - (
$\hat{y}_i$ ) adalah nilai prediksi.
Formula untuk R-squared (R²) adalah sebagai berikut:
dimana:
- (
$n$ ) adalah jumlah sampel, - (
$y_i$ ) adalah nilai sebenarnya, - (
$\hat{y}_i$ ) adalah nilai prediksi, - (
$\bar{y}$ ) adalah rata-rata dari ($y$ ).
Mengembangkan model machine learning yang dapat memprediksi harga jual rumah dengan akurasi tinggi menggunakan dataset yang tersedia.
- Apakah sudah menjawab problem statement? Ya, model yang dikembangkan, terutama dengan menggunakan Random Forest, berhasil memprediksi harga jual rumah dengan akurasi yang tinggi, seperti ditunjukkan oleh nilai R-squared yang mendekati 0.83, menunjukkan bahwa sekitar 83% variabilitas harga rumah dapat dijelaskan oleh model.
- Apakah berhasil mencapai goals yang diharapkan? Goal untuk mengembangkan model yang akurat telah berhasil dicapai. Penggunaan teknik seperti feature engineering dan hyperparameter tuning telah meningkatkan performa model dari baseline Regresi Linear.
Mengidentifikasi dan menganalisis fitur-fitur yang paling berpengaruh terhadap harga rumah.
- Apakah solusi statement yang direncanakan berdampak?
Solusi untuk menganalisis fitur-fitur penting telah memberikan wawasan mendalam tentang faktor-faktor yang mempengaruhi harga rumah. Analisis fitur penting seperti kualitas keseluruhan (
OverallQual), luas area hunian (GrLivArea), dan lokasi (Neighborhood) menunjukkan dampak signifikan pada harga rumah, memungkinkan para stakeholder membuat keputusan yang lebih informasi.
Menerapkan teknik peningkatan model seperti hyperparameter tuning untuk meningkatkan performa prediksi.
- Apakah berhasil mencapai goals yang diharapkan? Teknik peningkatan seperti hyperparameter tuning yang diterapkan pada model Random Forest berhasil meningkatkan keakuratan prediksi, memberikan performa yang lebih robust dan stabil. Ini membuktikan pentingnya pengoptimalan model dalam praktik nyata.
- Fitur Signifikan:
OverallQual: Pengaruhnya sangat signifikan terhadap harga rumah, menunjukkan bahwa kualitas rumah adalah pertimbangan utama bagi pembeli.GrLivArea: Luas area hunian juga sangat mempengaruhi harga, dengan rumah yang lebih besar cenderung dihargai lebih tinggi.Neighborhood: Lokasi rumah berdampak besar pada harga, dengan area yang lebih diinginkan seperti yang terlihat di zonaFVmemiliki harga rata-rata yang lebih tinggi.- Faktor lain yang teridentifikasi melalui analisis fitur termasuk
YearBuilt(tahun pembangunan rumah) danExterQual(kualitas eksterior).
Proyek ini berhasil mengembangkan dan mengevaluasi dua model prediksi harga rumah,Regresi Linear dan Random Forest Regressor. Untuk mengatasi masalah kompleksitas dalam peramalan harga rumah di industri properti. Berikut adalah kesimpulan utama dari proyek ini:
-
Performa Model: Random Forest Regressor menunjukkan performa yang superior dibandingkan dengan Regresi Linear dalam semua metrik evaluasi. Model ini tidak hanya memberikan kesalahan prediksi yang lebih rendah (MAE dan RMSE yang lebih rendah) tetapi juga menggambarkan sebagian besar variansi dalam harga rumah (R² yang lebih tinggi).
-
Faktor Pengaruh: Analisis fitur mengidentifikasi faktor-faktor kunci yang mempengaruhi harga rumah, seperti lokasi, ukuran, fasilitas, dan kualitas bahan. Penggunaan teknik feature engineering, seperti menghitung usia rumah, memberikan wawasan tambahan yang membantu dalam meningkatkan akurasi model.
-
Optimisasi Model: Penerapan hyperparameter tuning pada model Random Forest berhasil meningkatkan akurasi prediksi lebih lanjut, menunjukkan pentingnya penyesuaian model dalam konteks data spesifik.
-
Implikasi Bisnis: Hasil dari proyek ini mendukung pengambilan keputusan yang lebih baik dalam pembelian, penjualan, dan investasi properti. Model yang dikembangkan dapat digunakan sebagai alat bantu untuk pembeli, penjual, dan investor dalam menilai nilai pasar yang adil untuk properti berdasarkan karakteristiknya.
-
Rekomendasi untuk Pengembangan Lebih Lanjut: Untuk meningkatkan akurasi dan keandalan prediksi lebih lanjut, disarankan untuk mengintegrasikan data pasar yang lebih dinamis dan variabel makroekonomi dalam model. Selain itu, eksplorasi algoritma machine learning lanjutan seperti ensemble methods dan deep learning bisa dipertimbangkan untuk menangani data yang lebih kompleks dan variatif.
Proyek ini menegaskan pentingnya teknologi machine learning dalam transformasi sektor real estat, tidak hanya dalam memperkuat transparansi pasar tetapi juga dalam meningkatkan keefektivitasan operasional dan keputusan strategis.