This is my graduation project from 2012. At that time, I was amazed by the search speed of Everything, so I decided to implement my own search engine.
If you don't know what Everything is, please check here.
Everything is a proprietary free Windows desktop search engine that can quickly search for files and folders on NTFS volumes by name.
I apologize for my lack of experience in MFC and C++ at that time.
If you want to know how to retrieve all the files on an NTFS volume and hash them, please read QSearch/Volume.h.
Oh, the language in the pictures is still Chinese ^_^

- Save the image above as -> *.jpg
- Rename the .jpg file to .7z
- Extract *.7z -> (QSearch.exe config.ini)
I hope to refactor it someday, but I no longer use Windows now.
- Reading NTFS MFT
- Building a hash table
- File system paths
- GUI and worker threads
- Multiple search methods
- MFC interface
- Early April - Mid-April: Determine research direction
- Late April - End of April: Preparation of various knowledge points, simple tests
- Early May: Designing the program and debugging and running the development
- Mid-May - End of May: Writing the graduation thesis
- Reasonable CPU and memory usage
- Stable software that provides different search options
- Extremely fast file location compared to Windows search functionality
Abstract
This article introduces the enumeration of all file and folder names on a Windows NTFS disk formatted in C++, the construction of a hash table using the STL, and the GUI and worker threads of MFC. It implements a simple search similar to Google keyword search based on user input, and instantly returns all matching files/folders and recursively obtains the system path of the file/folder.
Keywords: NTFS, fast, keyword, search, file path
The directory structure of Windows, in an NTFS volume, arranges files in the directory in the form of a B+ tree. When searching for a file in the directory, the B+ tree search method is used to first search the root node (starting from the root directory) and then compare the file name to be searched with the file names in the child nodes of the root node to determine which child node's storage area to search in. The search continues with the child node as the current root node until the file is found. [1]
Although the search provided by the Microsoft system can search for text content, the speed is very unsatisfactory.
In most cases, we just want to know which folder on the computer the file is stored in, and this program solves this problem very well.
NTFS (New Technology File System) is the standard file system for Windows NT and later versions of Windows.
NTFS replaces the File Allocation Table (FAT) file system and provides a file system for Microsoft's Windows series of operating systems.
NTFS has made several improvements to the FAT and HPFS (High Performance File System), such as support for metadata and the use of advanced data structures to improve performance, reliability, and disk space utilization. [2]
With the popularity of Windows 2000/XP based on the NT kernel, many individual users have started to use NTFS.
NTFS also stores data files in clusters, but the size of clusters in NTFS does not depend on the size of the disk or partition.
Reducing the cluster size not only reduces wasted disk space, but also reduces the possibility of disk fragmentation.
NTFS supports file encryption management, providing users with a higher level of security. [3]
Read all file names on the disk as data and match them based on user input keywords.
Return the matched file names along with their system paths to facilitate file opening.
The specific design ideas are shown in Figure 3-1.
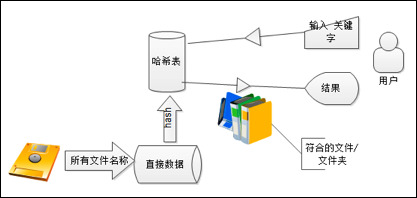
The biggest advantage of a hash table is that it greatly reduces the time required for data storage and retrieval, and can be considered as constant time; the only cost is the consumption of more memory.
However, in the current situation where more and more available memory is available, the approach of trading space for time is worth it.
In addition, easy coding is also one of its characteristics.
The most important part of the program is to read the USN.
USN stands for Update Service Number Journal or Change Journal, which is a function of recording information about modified information in an NTFS volume, and can be used to monitor the number of files and directories that have been modified in a partition, and record the modification time and content of the monitored objects.
When the USN log is enabled, for each NTFS volume, when there is information about adding, deleting, and modifying files, NTFS records it in the USN log and stores it in the format of USN_RECORD.
The USN log is like a table of contents for a book. It provides an index. When the content of the article changes, the USN log records when the modification was made, but it does not record what was specifically modified inside, so the index file is very small.
When you want to find a specific paragraph in the article, you don't need to scroll the mouse wheel frantically, just look at the table of contents, and you only need to press Ctrl + click to locate.
Similarly, when you want to find a specific file, you can directly find out if the file exists by searching the USN log (that is, the index) without searching the entire file system.
PS: Although Windows is not "everything is a file" (one of the basic philosophies of Unix/Linux), folders also exist in the form of files, so you can also use USN to locate them.
Since the NTFS format is Microsoft's patent, it provides a series of API functions for convenient access.
As an old but classic Visual C++ 6.0 programming tool, it did not have the NTFS format at that time, so VC2005 was chosen as the integrated development environment, and it can only run on Windows systems after 2000.
The following are API functions provided by Microsoft, included in the <Winioctl.h> header file.
Call the following function to find the disk in NTFS format:
GetVolumeInformation(
lpRootPathName: PChar; // Drive code string
lpVolumeNameBuffer: PChar; // Drive volume label name
nVolumeNameSize: DWORD; // Length of drive volume label name
lpVolumeSerialNumber: PDWORD; // Drive volume serial number
var lpMaximumComponentLength: DWORD; // Maximum file name length allowed by the system
var lpFileSystemFlags: DWORD; // File system identifier
lpFileSystemNameBuffer: PChar; // Format type
nFileSystemNameSize: DWORD // Length of file operating system name
);The lpFileSystemNameBuffer, which is what we need, will return strings like "FAT32" or "NTFS".
Then, using a loop, count the NTFS format drive letters from A to Z and initialize them.
HANDLE hVol = CreateFile(
"Drive letter string", // Must be in the form of \.\C: (A-Z)
GENERIC_READ | GENERIC_WRITE, // Can be
FILE_SHARE_READ | FILE_SHARE_WRITE, // Must include FILE_SHARE_WRITE
NULL, // Not needed here
OPEN_EXISTING, // Must include OPEN_EXISTING, CREATE_ALWAYS may cause errors
FILE_ATTRIBUTE_READONLY, // FILE_ATTRIBUTE_NORMAL may cause errors
NULL); // Not needed hereA few points to note:
- CreateFile returns a handle that will be used later.
- Since the drive letter must be in the form of
\\.\C:, in theC++language, the backslash//represents/. - Administrator privileges are required (UAC will pop up in Vista and Win7).
If hVol != INVALID_HANDLE_VALUE, it means that the handle is obtained successfully and you can proceed to the next step.
Use FSCTL_CREATE_USN_JOURNAL as the control code for DeviceIoControl.
Cujd is a pointer to the input buffer, pointing to the CREATE_USN_JOURNAL_DATA structure.
Use FSCTL_QUERY_USN_JOURNAL as the control code for DeviceIoControl.
lpOutBuffer returns a USN_JOURNAL_DATA, which is a structure.
typedef struct {
DWORDLONG UsnJournalID;
USN FirstUsn;
USN NextUsn;
USN LowestValidUsn;
USN MaxUsn;
DWORDLONG MaximumSize;
DWORDLONG AllocationDelta;
} USN_JOURNAL_DATA, *PUSN_JOURNAL_DATA;UsnJournalID, FirstUsn, and NextUsn will be used later.
Since the USN is stored in the form of USN_RECORD, its structure is as follows:
typedef struct {
DWORD RecordLength; // Record length
WORD MajorVersion; // Major version
WORD MinorVersion; // Minor version
DWORDLONG FileReferenceNumber; // File reference number
DWORDLONG ParentFileReferenceNumber; // Parent directory reference number
USN Usn; // USN
LARGE_INTEGER TimeStamp; // Timestamp
DWORD Reason; // Reason
DWORD SourceInfo; // Source information
DWORD SecurityId; // Security
DWORD FileAttributes; // File attributes
WORD FileNameLength; // File name length
WORD FileNameOffset; // File name offset
DWORD ExtraInfo1;
DWORD ExtraInfo2; DWORD ExtraInfo3; // Hypothetically added in version 2.3
WCHAR FileName[1]; // Pointer to the first character of the file name
} USN_RECORD, *PUSN_RECORD;Note the FileReferenceNumber, ParentFileReferenceNumber, FileNameLength, and FileName, which are crucial variables.
Use DeviceIoControl() with FSCTL_ENUM_USN_DATA.
while (0 != DeviceIoControl(hVol,
FSCTL_ENUM_USN_DATA,
&med,
sizeof(med),
Buffer,
BUF_LEN,
&usnDataSize,
NULL)) {
DWORD dwRetBytes = usnDataSize - sizeof(USN);
// Find the first USN record
UsnRecord = (PUSN_RECORD)(((PCHAR)Buffer) + sizeof(USN));
while (dwRetBytes > 0) {
// Get the information
CString CfileName(UsnRecord->FileName, UsnRecord->FileNameLength / 2);
pfrnName.filename = nameCur.filename = CfileName;
pfrnName.pfrn = nameCur.pfrn = UsnRecord->ParentFileReferenceNumber;
// Vector
VecNameCur.push_back(nameCur);
// Build the hash...
frnPfrnNameMap[UsnRecord->FileReferenceNumber] = pfrnName;
// Get the next record
DWORD recordLen = UsnRecord->RecordLength;
dwRetBytes -= recordLen;
UsnRecord = (PUSN_RECORD)(((PCHAR)UsnRecord) + recordLen);
}
// Get the next page of data
med.StartFileReferenceNumber = *(USN *)&Buffer;
}In this loop, each time a file name is obtained, it is inserted into both the vector and the hash table (explained later).
DeviceIoControl(hVol,
FSCTL_DELETE_USN_JOURNAL,
&dujd,
sizeof(dujd),
NULL,
0,
&br,
NULL)Save the data as Allfile.txt first for analysis, as shown in Figure 4-1.
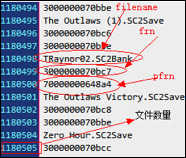

Using the D drive on my computer as a test, all files were enumerated.
As shown in the figure, there are approximately 400,000 files, with over 1 million data entries, and a file size of about 20MB.
This gives a rough estimate of the amount of memory the program occupies, which is about 50MB, even with only 1GB of memory, it is within a reasonable range.
With the raw data, the analysis is as follows:
For example, for the file "Linux Programming Practice.isz", its system path is: D:\Ghost\Linux\Linux Programming Practice.isz. Looking at the results in the file:
D:\
Frn: 5000000000005
Pfrn: NULL
...
...
Ghost
Frn: 20000000000fd
Pfrn: 5000000000005
...
...
Linux
Frn: e0000000010d2
Pfrn: 20000000000fd
...
...
Linux Programming Practice.isz
Frn: 190000000003b2
Pfrn: e0000000010d2
It can be concluded that:
Linux Programming Practice.isz -> Pfrn == Linux -> Frn
Linux -> Pfrn == Ghost -> Frn
Ghost -> Pfrn == D:\ -> Frn
D:\ -> Pfrn stops
So by using a recursive function (a function that directly or indirectly calls itself), you can get the complete path.
typedef struct _name_cur {
CString filename;
DWORDLONG pfrn;
} Name_Cur;Vector:
A sequential container.
Elements in the vector can be accessed using their position index.
Elements can be added to the vector using push_back or insert functions.
Adding or removing elements in the middle of the vector may cause all iterators pointing to elements after the insertion or deletion point to become invalid.
Using a vector to store <filename, current directory>, binary search or other fast search methods are not suitable here. The linear traversal from begin to end of the vector is more suitable for this requirement.
typedef struct pfrn_name {
DWORDLONG pfrn;
CString filename;
} Pfrn_Name;
typedef map<DWORDLONG, Pfrn_Name> Frn_Pfrn_Name_Map;Here, using the map library functions provided by the STL, map is a collection of key-value pairs.
The map type can usually be understood as an associative array: it uses keys as subscripts to obtain a value, just like the built-in array types.
The essence of association is that the value of an element is associated with a specific key, not obtained by the position of the element in the array.
- Considering that there may be some bugs if I implement my own hash function, it is better to use the stable map provided by the STL to implement it.
- "Don't Reinvent the Wheel" - Don't reinvent something that already exists.
- For example, Google's Android uses the mature Linux kernel because Google didn't have the ability to develop a kernel on its own. I think a world-class giant like Google should have the ability, but they adhere to the principle of not reinventing the wheel.
In the loop mentioned in 4.1.5, each time a USN_RECORD information is obtained, the filename, pfrn, and frn are inserted into the vector and the hash table, respectively.
pfrnName.filename = nameCur.filename = CfileName;
pfrnName.pfrn = nameCur.pfrn = UsnRecord->ParentFileReferenceNumber;
VecNameCur.push_back(nameCur);
frnPfrnNameMap[UsnRecord->FileReferenceNumber] = pfrnName;
At the beginning of the project, VC2005 provides command-line (console) projects and GUI projects.
Command-line programming is very convenient, fast, and practical, and relatively simple.
If the console can meet the requirements, there is no need for a GUI.
Sometimes the target platform may not be able to display a graphical user interface.
However, GUI has more obvious advantages, such as menu systems and better interactivity.
In addition, the mouse is very useful in menu selection and moving data between fields during data entry, so GUI is the way to go.
Therefore, when writing the program, I first experimented with some intermediate data in the console, and when there were no problems, I switched to the GUI.
MFC: Microsoft Foundation Classes, which is commonly referred to as MFC, is Microsoft's greatest contribution to "reducing the boredom, annoyance, and difficulty of Windows program design."
MFC makes it very easy to create dialog boxes.
It also implements a message dispatching system, handling WPARAM and LPARAM, which is prone to errors.
MFC is even the driving force behind some people's entry into C++.
This program is implemented using the MFC provided by Microsoft, as shown in Figure 4-2:
The KISS principle stands for "Keep It Simple and Stupid," and simplicity and ease of operation are the most important principles in design.
The KISS principle is probably the most respected in design, and in home design, interface design, and operation design, complex things are increasingly being criticized, while simple things are increasingly being recognized, such as the design of these UIs and our Chinese web pages.
IKEA's simple and efficient home design and production philosophy, Microsoft's "What You See Is What You Get" concept, and Google's simple and direct business style all follow the "KISS" principle. [7]
Under the KISS principle, simplicity is pursued as much as possible.
Add Editbox button listbox menu[8] controls to implement the following features:
- Editbox
- Get the user input string to be searched
- Button
- Get the string from the EditBox
- Show a prompt if the string is too short
- Add a magnifying glass image to indicate the functionality
- Listbox
- Display the matching file names and paths, double-click to open the file
- Since the path may be long, add a horizontal scrollbar
- Double-clicking on a file path in the Listbox will open the selected file
- Menu
- Menu options to select case sensitivity and search order
Benefits of threads: Threads are cheap.
Threads start quickly, exit quickly, and have a smaller impact on system resources.
Also, considering:
- Due to I/O limitations, using multiple threads to read the MFT simultaneously from the same disk is not very meaningful.
- Accessing the MFT of different partitions on the same disk may actually affect the speed. For computers with multiple disks, it should greatly improve efficiency. However, users with multiple disks may have RAID disk arrays. The best solution should be to read the disks in order from A to Z.
- Initially, when creating MFC, it was executed sequentially, resulting in the interface not being displayed until all data was counted, which easily made users lose patience.
- Finally, I decided to have one UI thread and one worker thread to count the data in the background.
MFC has long supported multithreading.
In a typical MFC program, support for multithreading is hidden behind a lot of amazing work.
MFC even attempts to reinforce certain Win32 concepts related to multithreading.
Both the GUI and worker threads are started using AfxBeginThread(), but MFC uses the overloading nature of C++ functions to provide two different declarations for this function. The compiler automatically chooses the correct one based on the parameters you provide. [9]
Use AfxBeginThread to start a thread.
pParam is an arbitrary 4-byte value that is passed to the new thread.
It can be an integer, a pointer, or simply 0.
Only the first two parameters are needed here, the thread function in the object and a pointer to that object.
In the task manager, you can see two threads, as shown in Figure 4-3:

When the worker thread completes its task, it will automatically end and return to a single thread.
Nowadays, more and more programs minimize to the system tray icon when the close button in the upper right corner is clicked. To truly exit the program, you need to right-click the tray icon and select exit.
To implement minimizing without exiting the program, it is convenient to search for files.
- Minimize and show in the taskbar.
- Clicking close exits to the system tray icon without showing in the taskbar; double-clicking restores the window display.
- Add a menu to the system tray icon.
In practical applications, it is not possible to remember the file name or path clearly, for example, "test.2012-5-14.txt" is often entered as "test.txt," so fuzzy searching is needed.
Since in the console, a hash table was created using <filename, pfrn>, if fuzzy searching is to be implemented, the hash table is not necessary, and the vector container can be directly used.
Based on the actual situation, there is no need for strict wildcards. * ? can solve most search problems, and users generally may not know how to use wildcards, let alone regular expressions.
So, using a space as a substitute for * ? and implementing a search method where keywords are separated by spaces, similar to Baidu and Google, is a good solution.
There are generally three situations:
- Users may not remember the case of the file name or path.
- Sometimes, when there are too many files, strict case sensitivity may be needed to filter the correct files.
- Users may not remember the order of the keywords.
So, the following two options are provided:
- Case-sensitive search
- Unordered search
Based on common situations, the default is case-insensitive search with ordered search.
- Considering that some folders are used to store private files.
- System folders, such as
c:\windows\*, are generally not needed by users and searching for them will only increase unnecessary files and burden the system.
So it is necessary to add an option to exclude folders, as shown in Figure 4-4.
The corresponding function is:
bool isIgnore(vector<string>* pignorelist) {
string tmp = CW2A(path);
for (vector<string>::iterator it = pignorelist->begin(); it != pignorelist->end(); ++it) {
size_t i = it->length();
if (!tmp.compare(0, i, *it, 0, i)) {
return true;
}
}
return false;
}After obtaining the matched file names, the next step is to obtain the system paths of the files.
Pass the full name of the matched file obtained above to the hash table frnPfrnNameMap constructed in 4.2.2, and recursively obtain the path.
CString Volume::getPath(DWORDLONG frn, CString& path) {
// Lookup 2
Frn_Pfrn_Name_Map::iterator it = frnPfrnNameMap.find(frn);
if (it != frnPfrnNameMap.end()) {
if (0 != it->second.pfrn) {
getPath(it->second.pfrn, path);
}
path += it->second.filename;
path += (_T("\\"));
}
return path;
}In theory, the time complexity is as follows:

On an AMD Athlon(tm) II X2 245 2.9GHz processor, the result is almost instant.
Since the number of computer files is huge—usually on the order of 100,000 to 1,000,000—the memory usage of the program itself can be neglected.
With 234,708 files, it takes up about 43MB.
For systems with at least 2GB of memory, it is not a burden.
The USN log file on the O drive cannot be initialized. Through debugging, it was found that:
DeviceIoControl returns 0, GetLastError 0x70
Checking MSDN, the reason is ERROR_SHARING_PAUSED
It turned out that I forgot to initialize the following code, and the program can access the O drive correctly:
CREATE_USN_JOURNAL_DATA cujd;
cujd.MaximumSize = 0; // 0 means using the default value
cujd.AllocationDelta = 0; // 0 means using the default valueInitially, in terms of string processing, I used the string from the standard library as the processing method, but I ran into a lot of trouble when converting between the double-byte wchar in Unicode and char. Finally, I used CString as the default string and initialized it with _T("") to solve the problem.
You cannot set breakpoints inside #ifdef. Later, I noticed that the #define was written before the include.
At the beginning, I designed it with a procedural thinking and got stuck in passing the same handle as a parameter. Later, I switched to using class methods to improve it.
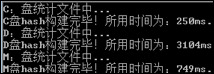
When building the hash function, I thought of three methods and conducted experiments. I used the time function to measure the time taken, and the results are as follows:
- After modifying the code, read the usn at once, save it to a temporary file, and then read and build the hash table.
- On average, it takes about 27 seconds each time it runs.
- Use a vector to store the data in memory and release it later.
- The result is impressive, the time is nearly 10 times faster!!! As shown in Figure 7-1:
It is completely within an acceptable range.
The first run takes significantly longer, but after that, the files are pre-read from the disk cache, and the speed increases.
The hotspots should be the disk seek time and file reading.
In 4.3.2, when opening the corresponding file, I initially used the system() system function, but it would pop up a black console window, and the main window would be locked until the file was closed before it could continue executing, which was very detrimental to the user experience.
I changed it to use the ShellExecute function, which creates a new process and allows the main window to continue executing.
After version 1.0 was released, some users complained that there was no progress indication during the background file counting, so they didn't know when it would be completed.
Therefore, I added a progress bar at the bottom of the main interface to enhance interaction, as shown in Figure 7-2:
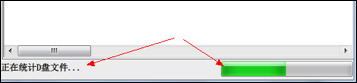
Of course, the thread function also made necessary modifications:
With this, the basic functionality of the program is complete. It has been tested on multiple computers and different systems (XP and later versions of Windows) and has not encountered any freezes or crashes.
Due to time constraints, there are still many features that have not been implemented, such as the inability to stretch the interface and the inability to dynamically count file data.
- [1] Hardware White Paper. NTFS File System Specification[OL]. Baidu Wenku, 2011: 30.
- [2] Beiyu. Research on Several Technologies of NTFS File System[OL]. 2007: 7.
- [3] Baby. Interactive Encyclopedia[OL]. http://www.hudong.com/wiki/ntfs
- [4] Microsoft. MSDN Library[OL]. 2012:
- [5] Stanley B.Lippman / Josée LaJoie / Barbara E.Moo. C++ Primer[M]. - Addison-Wesley Professional , 2006 : 10.3
- [6] Eric S. Raymond. Translator: Jiang Hong, He Yuan, Cai Xiaojun. The Art of UNIX Programming[m]. Electronic Industry Press- Society, 2006:
- [7] Chen Hao. Some Principles of Software Design[OL]. http://coolshell.cn/articles/4535.html
- [8] Sun Xin. In-depth Explanation of VC++[m]. Electronic Industry, 2006
- [9] Jim Beveridge / Robert Wiener. Multithreading Applications in Win32: The Complete Guide to Threads
- [10] Addison-Wesley Professional, 1996: 223-243