

VisualGo is a toolset of different machine learning algorithms to extract the current go board state from an image. It features two models, which first find the go board in the given image and then predict the current state. The basic pipeline of the whole model looks like the following:
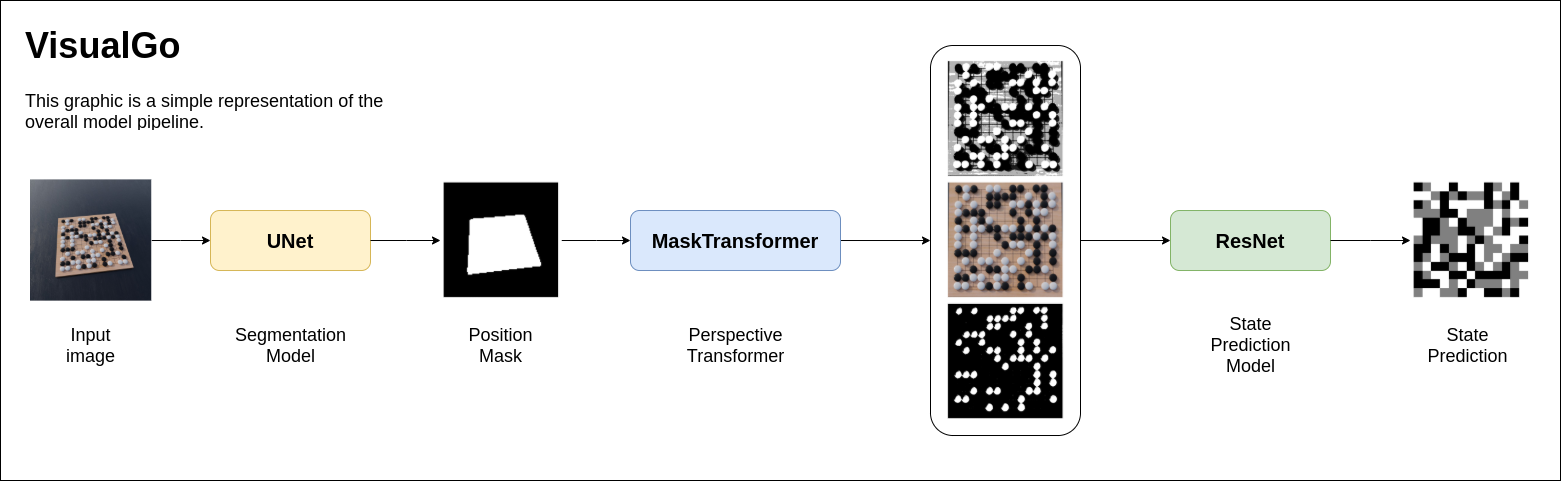
As seen in the figure above, the model is divided into two sub-models and a handcrafted transformer, which performs a perspective warp and threasholding on the images using the predicted masks.
The Segmentation Model is a basic UNet architecture [1] trained on ~800 rendered images of go boards. They are resized to 128x128 pixels and feeded into the network in batches of 16 images. It is a basic binary segmentation problem, hence the performance of the model is pretty good.
The State Prediction Model is a residual tower trained on the transformed images from the Segmentation Model.
This repository contains a set of notebooks explaining every model in depth and analysing their perfomance using Captum.
Here is a basic table of contents:
- EDA: Exploratory Data Analysis of the VisualGo Dataset
- Segmentation: Exploring the Segmentation model architecture and investigating the model quality using Captum
- MaskTransformer: Explaining the Transformer
- Position: Exploring the Position model architecture and investigating the model quality using Captum
I highly recommend checking them out with the binder link I set up.
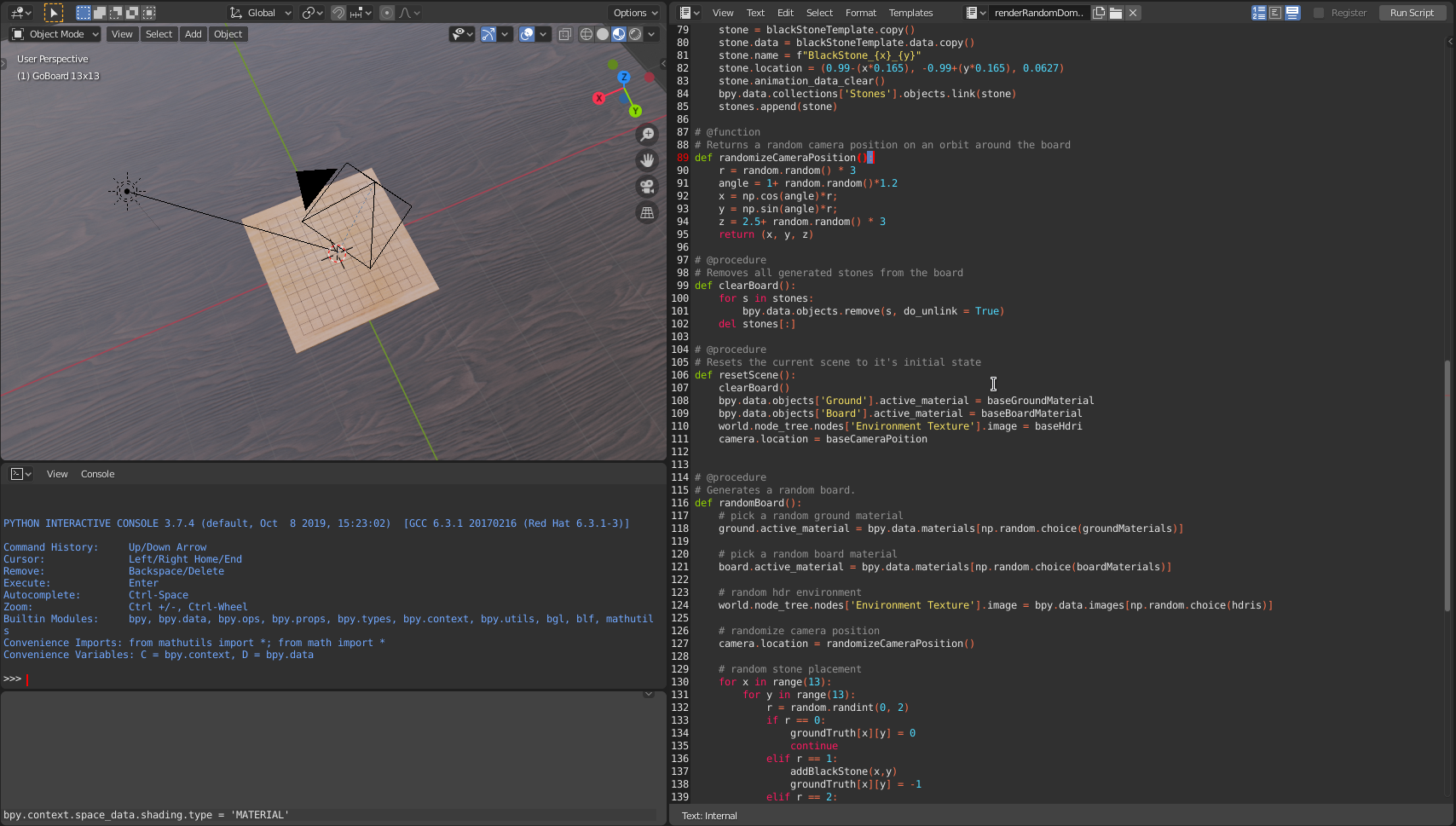

As already mentioned, the images are actually photorealistic renders of random go boards with randomized materials, camera positions and lighting (a deeper insight on how the data was generated is given in the EDA notebook).
You can find the dataset in its final form on kaggle.
It was rendered using blender and the following script.
- The awesome AlphaGo Movie
- Some other repositories (please check them out):
- https://github.com/maciejczyzewski/neural-chessboard
- https://github.com/pmauchle/ChessVision <-- this one actually uses almost the same approach :D
- https://github.com/maciejczyzewski/neural-chessboard
- [1] U-Net: Convolutional Networks for Biomedical Image Segmentation, Olaf Ronneberger, Philipp Fischer, Thomas Brox
- [2] Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization, Ramprasaath R. Selvaraju, Michael Cogswell, et al.