It has been difficult for Whitworth University recreation department to develop ideal schedules that allow each intramural team to play at least once or twice a week and match up with another team. I discovered the best optimum pair solutions by applying the Bipartite Matching Algorithm. Data received from the quadratics survey are saved in CSV files.
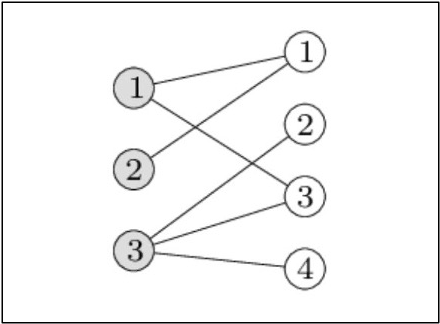

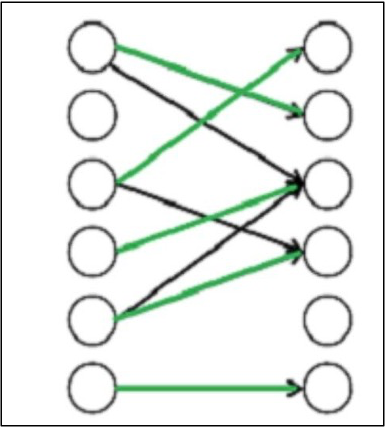
Finding the maximum matching in a bipartite graph is possible through bipartite matching. In order to expand the size of the matching, the algorithm iteratively searches the network for augmenting pathways. In a graph, a matching is a collection of edges where no two edges meet at the same endpoint. A matching with the most edges is referred to as a maximum matching.
The method begins by looking for a random matching M. A path that alternates between edges in M and edges not in M and starts and finishes at mismatched vertices is known as an augmenting path. In the event that such a path is discovered, the algorithm increases the matching by flipping the edges along the path, producing a greater matching. When there is no longer an augmenting path, the procedure is repeated, at which time the algorithm has discovered a maximum matching.
Pseudocode looks something like this:
- Initialize the matching M to be the empty set.
- While there exists an augmenting path P in the graph: a. Find an augmenting path P from the unmatched left vertices to the unmatched right vertices. b. Add the augmenting path P to the matching M.
- Return the matching M.
- Utilize the information I received in CS classes that were algorithm-focused
- Solve real world occuring problems
- Provides programming utility and efficiency towards the client (Todd Sandberg, Director of University recreation department)
- Create an executable files that can be accessed by the client (needs to be done)
- Analyze the data and give the most optimal schedule through bipartite matching
- Recreate the Bipartite matching algorithm (Modified to match our needs and goals)
- Make sure the program works for every cases including:
- Any amount of sports
- Any given days
- Any amount of teams
For now:
- Make sure that Python are installed in the device
- Install some extensions (Panda, Numpy, Xlsx)
- Copy the csv path to the data
- Run the program by clicking run
- 35 different excel files should be generated by now
- 35 files are earned through 7 days X 5 different sports
- I'm assuming that the U-Rec have some experience with working with executable or .py files
- As I got to know Through my friend who works at U-rec, The U-Rec has some software training such as fusion software that are more complex. This executable file would be easily implemented by U-Rec
- Program assumption:
- I assume that the name of each time are unique
- U-Rec will not change the way they gather all the data (Qualdratics Survey)
- Each team needs to have game at least 1-2x
- This is only generated for regular season (excluding playoffs)
- Check: returning a (n)^2 2Dimensional list where n is the number of teams
- common: Finding common time between 2 teams through boolean (pairing compatibilty [True/False])
- filter: Returning a list of size (number of team) that is set to -1 as default
- findpossiblematch: Checking the pairing compatibility of each teams and change the value of -1 to the index of the team that each team is playing against
- common_time : After finding the compatible pairings and it has been stabilized, then common time between two teams will be determined
- Others:
- Reading and Printing the data to excel sheet
- Panda commands
- https://www.geeksforgeeks.org/maximum-bipartite-matching/ (Bipartite matching explenation)
- https://xlsxwriter.readthedocs.io/working_with_pandas.html - xlsx writer extension
- Panda library
I have contacted the U-Rec and they agreed to use this program next semester. It will help the efficiency of creating a stable schedule.