How to use LAMB optimizer ? #1123
Description
Hi Great Team,
I just want to know what is the right way to use NVLAMB optimizer. I check the code here
And I write a test example with PolyWarmUpScheduler, but it seems there is something wrong with the combination of optimizer and lr_scheduler.
from lamb_amp_opt.fused_lamb import FusedLAMBAMP
from schedulers import PolyWarmUpScheduler
import torch
import matplotlib.pyplot as plt
device = torch.device("cuda")
lr = 1
total_steps = 100
warmup_proportion = 0.1
model = torch.nn.Linear(10,1).to(device)
# optimizer = torch.optim.Adam(m.parameters(),lr = lr)
optimizer = FusedLAMBAMP(model.parameters(),lr=lr,)
lr_scheduler = PolyWarmUpScheduler(optimizer,
warmup=warmup_proportion,
total_steps=total_steps,
base_lr=lr,
device=device)
lrs = []
loss_fct = torch.nn.MSELoss()
for _ in range(total_steps):
output = model(torch.rand(2,10).to(device))
labels = torch.rand(2,1).to(device)
loss = loss_fct(output,labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
lr_scheduler.step()
lrs.append(optimizer.param_groups[0]['lr'].item())
plt.plot(lrs)
This is what I got
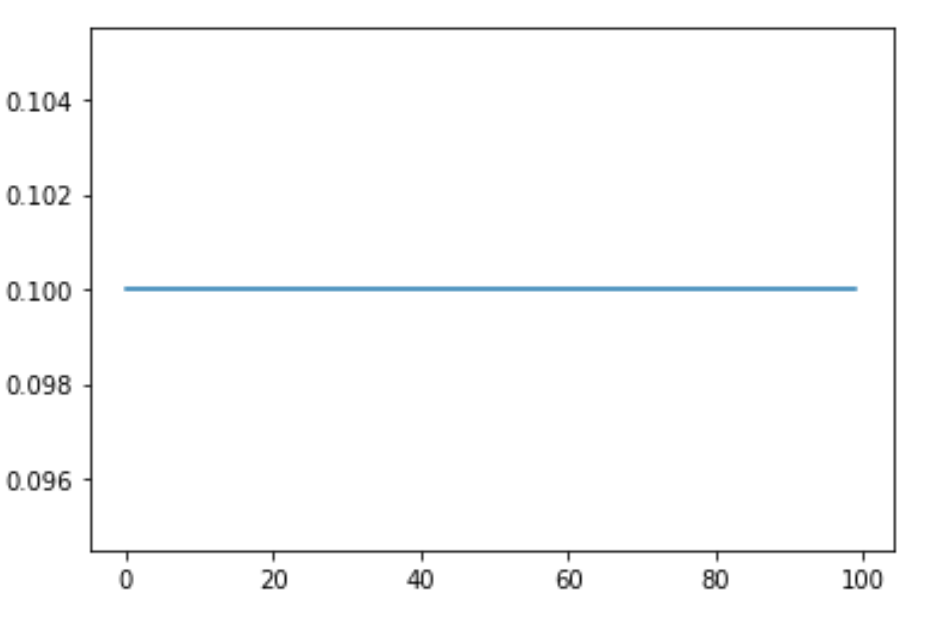
And I also check official Adam optimizer. Nothing changed.
Do I misunderstand something about LAMB optimizer and PolyWarmUpScheduler ? Thanks so much !