Java driver rows vs columns
In CQL3 columns can be rows as well depending on your column family schema. Here is a simple example. Say that you have a simple table created as follows.
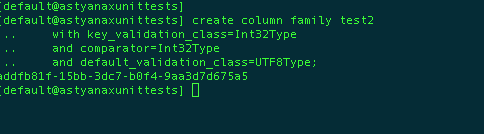
Note the use of the simple key validator, comparator and default validator.
In CQL3, the schema definition looks like this.

Note the PRIMARY KEY definition int the 2nd schema. The clustering key corresponds to the column comparator, and since clustering key is part of the primary key, this makes unique storage columns appear as distinct rows in CQL3.
An an example, suppose we had the following data (at the storage level)

Note that there are 2 distinct rows. First row has 5 columns and the second row has 3 columns.
In CQL3 the rows and columns will appear as so
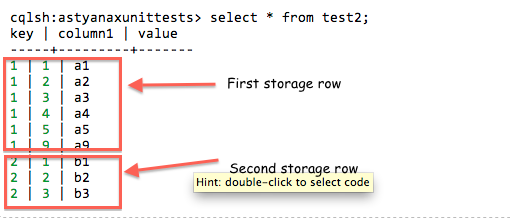
Note that there are 8 distinct rows here that map to your 8 distinct columns.
In Astyanax, rows and columns directly map to the storage rows format. Hence, in order to keep things consistent in Astyanax and also avoid a lot of confusion, we have preserved the original semantics for rows and columns. i.e Astyanax's view of rows and columns is the same regardless of the driver being used underneath. This approach helps application owners keep their biz logic and DAO models the same and avoids a re-write of all the numerous DAOs at Netflix.
See ColumnFamily-Clustering-Column for more details on how to run queries for this kind of schema.