Home
- What does Artificial Intelligence mean to you? What examples do you think of?
- Google's AlphaGo
- Self-driving cars
- Video game AI
- What else?
- What do you expect to get out of this? Why are you here?
- Have you done anything already? What have you looked at?
- What is the difference between AlphaGo and Deep Blue?
- What is the fundamental difference between chess and Go? Why is Go so hard?
- Brute force searching / expert rules and algorithms / machine learning / genetic algorithms
- Buzzwords associated with AI you may have heard:
- Deep Learning
- Machine Learning
- Computer Vision
- Neural Network
- Convolution Network
- Genetic Algorithm
- Big Data

- Prerequisites:
- Familiarity with calculus, especially a conceptual understanding of what a derivative is.
- What a vector is -> quick intro -- just know what they are, not even how to math with them. The term may be used a bit.
- (optional) Familiarity with derivatives in multi-dimensional spaces, aka gradients
Artificial intelligence is a difficult topic to talk about. There are many different types of AI, and many different definitions of what AI is. The focus of this workshop is on machine learning, especially with neural networks. We will explain what machine learning is, what neural networks are, and how neural networks and machine learning are used to solve tough problems in the real world. After an introduction, we will as a group walk through a fairly simple example of using a neural network to learn to classify images of letters, correctly identifying the letter in the image. After that, you are on your own to follow the labs for several other AI examples. Toward the end, we will discuss more about AI and how our perspective may have changed in this short time we have. We hope you all have fun!
So what is machine learning and how does it work?
- AI includes many aereas, as we discussed
- video game AI
- 'classic' AI algorithms -> not always considered AI anymore
- can be as broad as "a computer doing something that seems smart"
-
Machine Learning is using a computer to learn over time how to solve a problem. In other words, it was not programmed to solve the problem, it was programmed to learn to solve the problem on its own.
- Many real problems are very difficult to program a solution for (ex: How do you play go? There are experts in go, but we can't easily formulate their intuition, knowledge and experience as a series of computations)
- This is the heart of AI: programming is an exercise in reforming what we know ourselves in a form a computer can use to do something. Things that are easy to formulate as a series of steps lend themselves well to computer programs. However, as you probably are aware, things we take for granted are often very difficult to represent as a computer program.
- recognizing faces
- understanding spoken words and their meaning
- walking
- By letting the computer find its own way to solve a problem, we no longer have to do all the hard work ourselves. However, this isn't a silver bullet. There are many problems that are better left to programmers, and there is still a lot of work in formulating a given problem as a ML task, as we will see.
- Think of learning as finding the representation of a function that you do not know
- Concrete ex: linear/polynomial regression
- Imagine the function of the best action to take at any given time in a video game
- Any function: input -> output
- Input is a 64x64 image, output is which animal is in the image.
- Input is a list of 1000 characters, output is the next character.
- Input is a list of 144 characters, output is which TV show it is about, or just if it is about a TV show.
- This is the basic understanding to ML.
- what other function representations could we use? say to drive a car?

- Machine learning is the idea that we can use computers to 'learn' these representations. But how does r computer learn?
- We use a model - ex: linear function - with a number of tweakable parameters - ex: slope & intercept
- We could try randomly picking parameters and picking the best out of 100
- We could try randomly mutating parameters à la genetic algorithms
- how do we determine the "best" model? what are our criteria?
- In regression, we use a loss function to represent how good or bad our model is.
- Loss functions such as mean squared error (MSE)
- Other functions such as cross-entropy
- We then calculate a model with the least error
- with linear regression, we can write out an explicit formula for the cost, given y=mx+b
- and solve the cost function to find the minimum
- For more complex regression tasks, we can't explicitly solve for the minimum cost. But we can still try to find it.

- Introducing stochastic gradient descent (SGD):
- 'Climbing a hill' of the loss function (or descending. depending on how you look at it)
- At any given point, we need to find a direction to move to, and we take a small step in that direction
- SGD uses gradients to determine which direction to step towards
-
Recall derivative is the 'slope' of a function at a given point, x, or the rate of change (f'(x))
-
For a 2D function like a quadratic, the derivative indicates the tangent line or the rate of change
-
Gradient -> indepth explanation
- Vector of all of the partial derivatives -> rate of change with regards to one variable
- Can be thought of as a tangent plane rather than tangent line
- Is a vector that points in the direction of greatest change
-
Let's use a linear regression tasks as an example:
-
we pick random parameters, m, and b, for f(x)=mx+b
-
for some input, calculate the output of the network and the loss function (called the forward pass)
-
evaluate the gradient of our loss function with respect to our parameters, m and b (aka. calculate the derivative) (called the backward pass)
-
change parameters m and b along the gradient
- (the gradient is a 2D vector, containing some part m and some part b. If we think of our parameters m and b as a 2D vector as well, <m,b>, then this step is just <m,b> + gradient)
- if we take small enough steps, we are assured that our loss will improve when we do this
- GOTO 2:
-
-
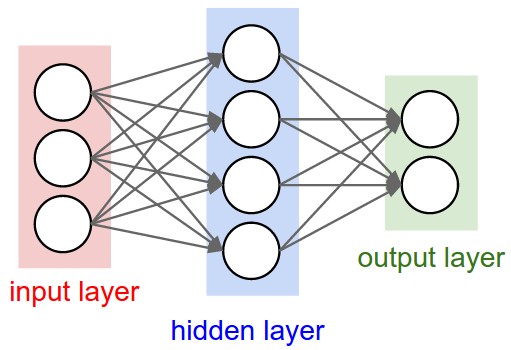
- This is where neural networks come in
- What is a neural network?
- Simple construction of simple mathematical units called neurons
- Construct large networks of these neurons
- When we arrange them in layers, the computation of the network is computationally simple, aka not complex, or simply fast
- Most importantly, the derivative is easy to compute as well.
- Call them Artificial Neural Networks, aka ANN
- What is a neural network?
- "Deep Learning" is mostly a buzzword. It simply means using an ANN with more than 1 layer.
- anything described as "Deep" in AI is referring to this property of having many layers in an ANN.
- layers in between the input and output are called hidden layers because their state is not directly visible.
- one or more hidden layers = deep
- By using ANNs, SGD is simple
- The backpropagation algorithm can calculate the derivative of the error function with regards to the parameters.
- ANN is simply being used as a model and is certainly not the only model.
- Ex: linear regression can be modeled as an ANN
- The 'function space' can have millions of dimensions to it - aka parameters - whereas linear regression only has 2 dimensions: slope & intercept

Rectified Linear Function
- Typically use neurons that are rectified Linear Units or "ReLU"'s for short.
- linear functions are easy to deal with in calculus (aka gradients)
- cheap to compute (matrix multiplication input*W where W is matrix of weights)
- disadvantage: a linear transformation applied to a linear transformation = a single linear transformation
- solution: activation function -> apply a non-linear transformation between layers
- typically use tanh, or sigmoid (logistic function), squishes the output to (0,1) / (-1, 1)
- Many different classes of ANNs
- What do you use as your neurons? -> linear with sigmoid activation?
- how are they organized? stacked layers? completely connected (every neuron connected to every other neuron)? can the network output be used as an input?
- How many neurons do you have? How many layers do you have?
- network types such as recurrent neural networks (RNNs) and convolution neural networks (CNNs) -> just classes of ANNs
- The takeaway is that ANNs are just a broad class of functions that have many parameters
- In order to train an ANN, you need a large number of sample points or data.
- ex Linear regression -> need many (x,y) sample points
- poor samples result in poor models -> basic concept of statistics
- We train an ANN by passing in large amounts of points, and for each point, calculate the gradient. Rinse. Repeat.
- if we see this same point again, we are likely to do better
- however, what may be good for one data point, may not be good for another
- typically use mini batch to solve some issues with this, as well as speed up computation
- pass in a list of data points, and calculate the average gradient of all the points
- if we see the same points again, we are likely to do better
- by randomizing mini batches, we learn what parameters are good in general, not for a specific data point.
As a group, we will work through the letter classification problem to get a concrete understanding of how this all works and the implications of what we've just talked about, as well as get practical experience with Python, TFLearn, and ANNs before you start working on your own.
- What challenges are there with ML?
- Does it work for every problem?
- What makes some problems better suited for ML vs. traditional AI or fixed programs?
- How do we deal with local optima? Is this even a problem?
- How does our intuition change as the dimensionality of a problem goes up?
- More and more knobs so to speak to fiddle with
- Can there be too many knobs? is so, how do we find the right amount?
- What do you know now that you didn't know 3 hours ago?
- More importantly, what do you understand now that you didn't 3 hours ago?
- If you had to sum up what you just did in a few sentences to someone, how would you do it?
- What aspects of AI fascinate you?
- What problems do you want to solve?
- What algorithms do you think are awesome?
- What sort of moral/ethical or legal issues can you see?
- Self-driving cars - who is at fault in an accident?
- Face recognition - what happens when it's wrong?
The first thing you will need to do is login and install some libraries on CSX. Follow the guide here
- Classic Classification Problem - recognizing handwritten characters from an image - (aka Optical Character Recognition)
- Reinforcement Learning - learn by doing, and failing several thousand times, to play a game
- Convolution Networks - advanced computer vision image recognition
- LSTM Generator - let your computer write for you!