Made PrimePY a LOT faster #9
Conversation
You probably dont want to merge this as it significantly changes the spirit of the piece of code, but I wanted to show that Python can be VERY in some cases.
|
This closes #3 by being almost twice as fast. Nice job! |
|
Btw, would have been nice to post the numbers you were getting with C# and C++ as well, for comparison. All machines are different, so we don't know what "25939 passes" actually means. |
|
This is tested on Arch Linux with kernel 5.11.6, 32GB DDR4 RAM, i7-9750H.
C++
C#
Python
|
|
This is quite impressive. But here's a question. It's using multiple libraries instead of using native Python. Do those additional libraries use native code instead of pure python? If they are, it feels a bit like cheating, and perhaps there should be two versions - one with pure Python and built-in libraries, and the other which takes advantage of extra libraries for better performance. |
Both Numpy and Numba use native code (although none of Numpy´s native code is actually executed). Numba contains quite a significant amount of native code, and actually produces machine-code at runtime. Is it cheating? Maybe, but not because the libraries use C code. The whole runtime is written in C, so using it as a qualifier is either meaningless or incredibly ambiguous. I think the benchmark for that should be whether we use specific-purpose native code, and that is NOT the case. I do, however, se a case for keeping two separate solutions, one using the pure STL (in which case we can expect performance that is on par with the dotnet performance) and one where we use Numba´s JIT (or another Python JIT for that matter). |
|
Fair reasoning! |
|
Well, think of Numba kinda like it used to be when people were writing C or C++ but the compilers weren't super optimized like today, and if they had something performance critical they would insert some assembly code to make it as fast as possible. It's sort of like that, except code written for Numba is much, much close to Python than assembly is to C. It's basically just Python with types. So in this respect i wouldn't consider using Numba cheating. It's still Python. It's like choosing a different compiler for your C code cause it's a bit better optimized. |
Thanks! I was afraid it would come across as a bit rant-ey. I´m happy my point got across despite that.
Don´t worry about it! It didn´t. I just wanted to make sure that I explained my position properly, and wanted to explain why I see it differently.
Yes, that´s where the largest speed gain is.
CPython doesn´t by default. There are interpreters (like Pypy and Jython) that do, but they are oftentimes slower than using Numba. They do provide a more "Pythonic" experience: Numba restricts the amount of Python we can write, so that it will be able to optimize it better. |
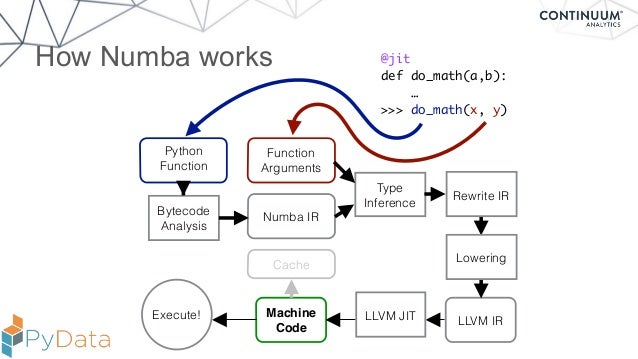
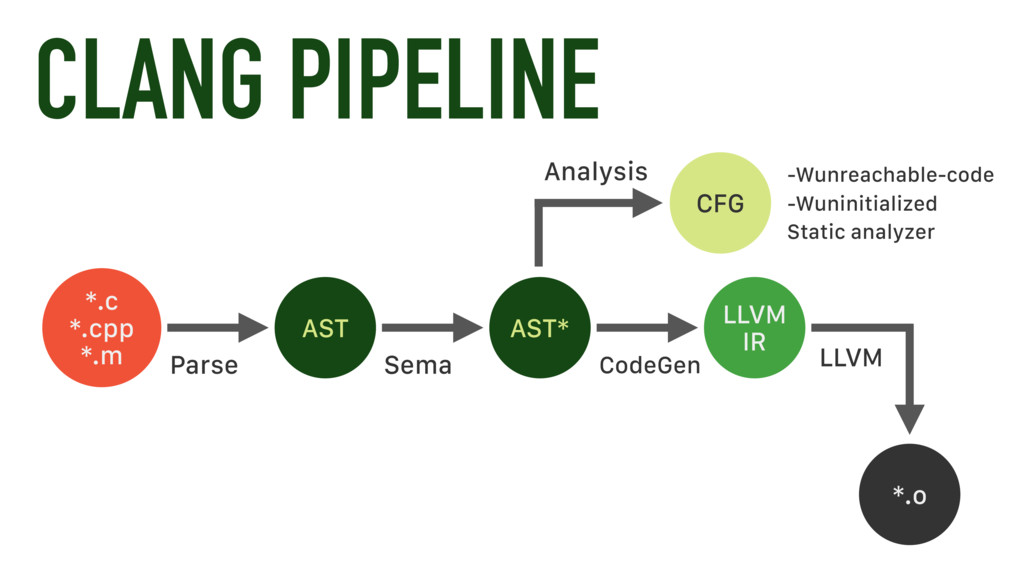
Python built-ins are implemented in C. The source code for Python can be found here. Many Numpy ops just link to the Python implementation (eg; numpy.sum() is just sum()). Numpy still gets called through the interpreter though; which means everything has to happen in memory + you cannot optimize around multiple / overlapping functions. For example, will literally create a 100000000 dimensional array in memory without any consideration to how sum will use it. This is pretty expensive, but if you decorate with numba, f() gets JIT compiled and no array generation occurs. The Numba JIT compilation is potentially* cheating in the sense that Numba is doing some extra manual translation work in the frontend. It's sort of comparable to clang (which is also just an LLVM frontend), but I think the translation from c/++ -> LLVM IR in clang is more deterministic / automatic. The Numba team literally re-implements builtins / Numpy functions in their own language and then maps the Python code "something they know how to compile" before translating the Numba IR to LLVM IR. So there is probably a side effect here where Numba implicitly re-writes poor Python implementations to be optimal before lowering to LLVM IR --in a way that is more rigid than clang. I could be wrong though.
Generally, the name of the game for compiling Python is to either translate Python -> C (which can then be compiled by clang/gcc) or translating Python -> LLVM IR (which can be compiled directly by LLVM backend). There's dozens of mature libraries / tools for JIT and AOT compilation, but the methodology is essentially bimodal. Usually the former for AOT and the latter for JIT. While it is possible make Python as fast as C languages in 2021 using JIT compilers, I concede that the comparison is somewhat beyond the scope of Dan's video. The C languages are designed to be compiled, and Python is designed to be interpreted. It would be equivalent to benchmark native Python vs. C++ using a 3rd party C interpreter. |
|
I'm wondering how this relates to #2? |
|
Closing due to lack of contributor response. Can be reopened on drag-race branch if desired. |
You probably dont want to merge this as it significantly changes the spirit of the piece of code, but I wanted to show that Python can be VERY in some cases.