El Expectation-maximization (EM) es un método estadístico de Clustering similar al K-means, pero con un enfoque probabilístico. Este método asume que todos los objetos (del data set) han sido generados a partir de ‘k’ distribuciones de probabilidad de las cuales desconocemos a priori sus parámetros.
Para saber más sobre el K-means, ir al siguiente tutorial:
http://jarroba.com/expectation-maximization-python-scikit-learn-ejemplos/
A continuación se muestra el Pseudocódigo del Expectation-maximization:

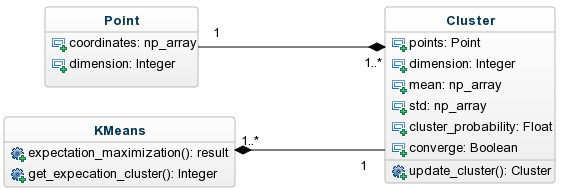
A continuación se muestra el diagrama de clases para la implementación del Expectation-maximization, en el que se ven involucradas las clases Point (Point.py) y Cluster (Cluster.py). En el script EM.py (que no es una clase aunque así se representa en el diagrama de clases) está el método Main que ejecuta el EM.
En el script EM_scikit.py se muestra una solución del EM utilizando la librería scikit-learn, por tanto no es una implementación propia (o desde cero) de este algoritmo.
El código que se encuentra en este repositorio hace uso de las librerías de numpy, matplotlib, scipy y scikit-learn. Para descargar e instalar (o actualizar a la última versión con la opción -U) estas librerías con el sistema de gestión de paquetes pip, se deben ejecutar los siguiente comandos:
$ pip install -U numpy
$ pip install -U matplotlib
$ pip install -U scipy
$ pip install -U scikit-learn
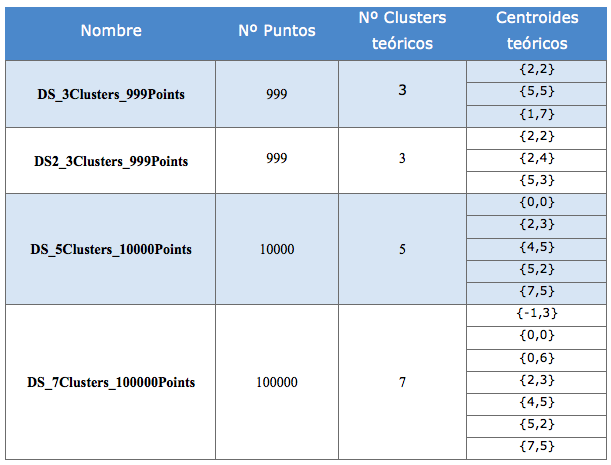
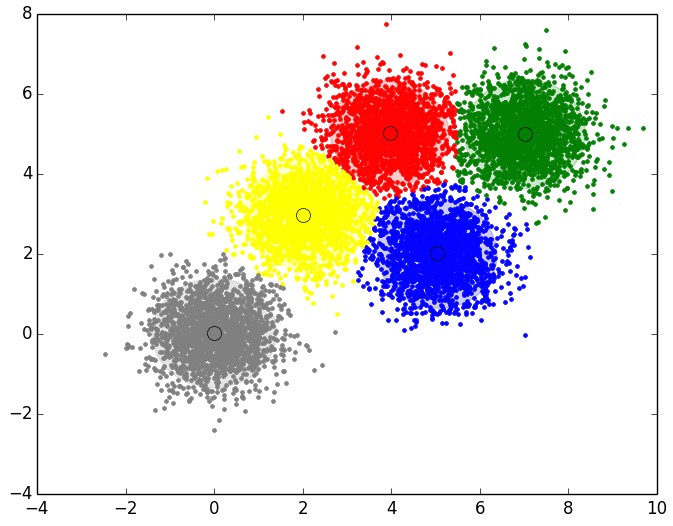
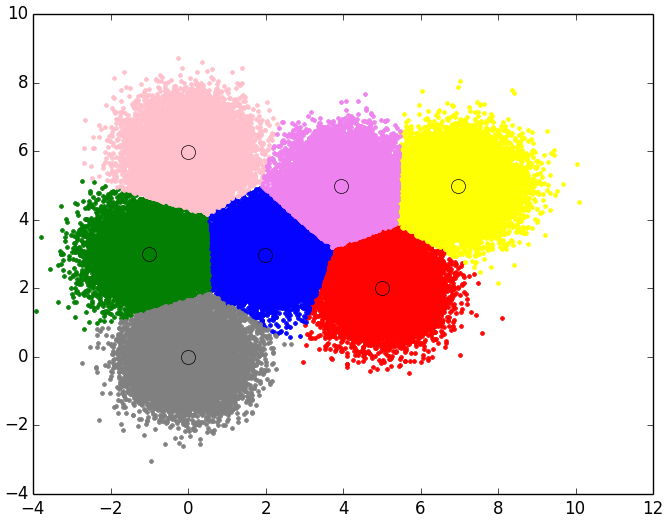
El orden de los clusters no tiene porque coincidir con los propuestos, pero los centroides si que deben de tener valores muy similares a los indicados:
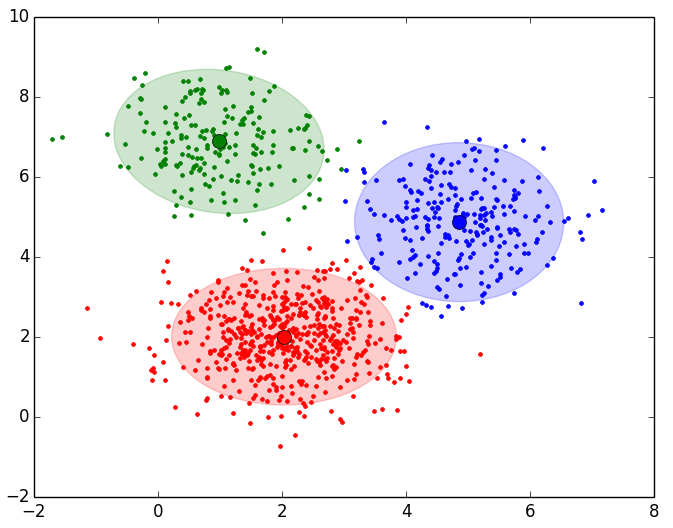
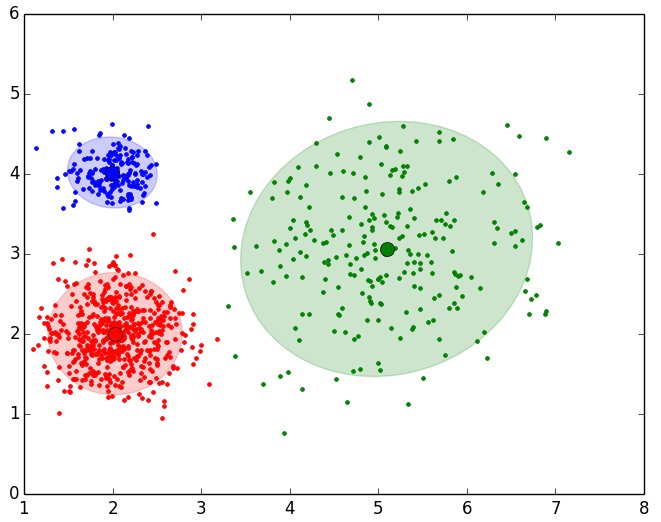
Para más detalles del proyecto vista la web de jarroba.com:
