$ where python
$ lite\tools\build_windows.bat ^
use_vs2017 ^
with_profile ^
with_precision_profile ^
with_extra注意:
- paddle_lit_opt无法在windows下直接运行,所以使用
python %CONDA_PREFIX%\Scripts\paddle_lite_opt --help来获知HOWTO。注:CONDA_PREFIX是Anaconda3的环境变量,Paddle-Lite的搭建可以选择Anaconda3来完成。 - 当前Paddle-Lite仅仅支持python3.5,python3.6与python3.7,其他版本可能存在兼容性问题
$ where python
$ lite\tools\build_windows.bat ^
use_vs2017 ^
with_profile ^
with_precision_profile ^
with_extra ^
with_opencl使用py37-paddle-dev.yaml来搭建paddlelite编译环境
name: py37-paddle-dev
# The conda channels to lookup the dependencies
channels:
- anaconda
- conda-forge
# The packages to install to the environment
dependencies:
- conda-build
- git
- llvmdev==10
- numpy
- pytest
- cython
- cmake
- bzip2
- make
- scipy
- pillow
- cudatoolkit-dev
- cudnn
- nccl=2.14
- ipython
- pip
- python=3.7
- black
- opencv
- matplotlib
- pandas
- mkl-devel
- intel-openmp
- protobuf搭建环境
$ conda env create --file py37-paddle-dev.yaml$ lite/tools/build_linux.sh --arch=x86 \
--toolchain=gcc \
--with_extra=ON \
--with_python=ON \
--python_version=`python --version | cut -d ' ' -f 2 | cut -d '.' -f -2` \
--with_log=ON \
--with_exception=ON \
--with_profile=ON \
--with_precision_profile=ON \
--with_static_mkl=OFF \
--with_avx=ON \
--with_opencl=ON$ lite/tools/build_linux.sh --arch=x86 \
--toolchain=gcc \
--with_extra=ON \
--with_python=ON \
--python_version=`python --version | cut -d ' ' -f 2 | cut -d '.' -f -2` \
--with_log=ON \
--with_exception=ON \
--with_profile=ON \
--with_precision_profile=ON \
--with_static_mkl=OFF \
--with_avx=ON \
--with_opencl=ON \
full_publish以mobilenet v1模型为样例
$ cd test
$ wget http://paddle-inference-dist.bj.bcebos.com/mobilenet_v1.tar.gz
$ tar xvzf mobilenet_v1.tar.gz
$ paddle_lite_opt --model_dir mobilenet_v1 \
--optimize_out_type naive_buffer \
--optimize_out mobilenet_v1_opencl \
--valid_targets opencl
$ python3 test_paddlelite_opencl.py$ cd test
$ wget http://paddle-inference-dist.bj.bcebos.com/mobilenet_v1.tar.gz
$ tar xvzf mobilenet_v1.tar.gz
$ paddle_lite_opt --model_dir mobilenet_v1 \
--optimize_out_type naive_buffer \
--optimize_out mobilenet_v1 \
--valid_targets x86
$ python3 test_paddlelite.pysetx GLOG_v 5
set GLOG_v=5export GLOG_v=5strace python xxx.py01. cd test
02. mkdir build
03. cd build
04. cmake -DWIN64=1 -G "Visual Studio 15 2017 Win64" ..
05. set curr_dir=%cd%
06. "C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Visual Studio 2017\Visual Studio Tools\VC\x64 Native Tools Command Prompt for VS 2017.lnk"
07. cd %curr_dir%
08. msbuild /p:Configuration=Release test_paddlelite_opencl.vcxproj
09. cd ..
10. build\Release\test_paddlelite_opencl.exe
01. sudo apt install libopencv-dev
02. sudo docker login
03. sudo docker pull redis:latest
04. sudo docker run -itd --name transformer -p 6379:6379 redis # default ip address: 127.0.0.1
OR service on host address used by outside network
sudo docker run -itd --name transformer -p `hostname -I | cut -d ' ' -f 1`:6379:6379 redis
05. sudo apt install redis-tools
06. redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> exit
07. sudo pip3 install --upgrade redis
08. cd test
09. wget http://paddle-inference-dist.bj.bcebos.com/mobilenet_v1.tar.gz
10. tar xvzf mobilenet_v1.tar.gz
11. paddle_lite_opt --model_dir mobilenet_v1 \
--optimize_out_type naive_buffer \
--optimize_out mobilenet_v1_opencl \
--valid_targets opencl
12. mkdir build
14. cd build
15. cmake ..
16. make
17. cd ..
18. python3 test_redis.py
19. ./build/test_redis
20. ./build/test_paddlelite_opencl
21. python3 test_paddlelite_opencl.py
$ cd test
$ pip3 install --upgrade paddle2onnx==0.8.2
$ paddle2onnx --model_dir mobilenet_v1 \
--opset_version 9 \
--save_file mobilenet_v1.onnx \
--enable_onnx_checker True
$ pip3 install --upgrade onnxruntime
$ python3 test_paddlelite_onnx.py访问Netron Release,下载最新的netron版本。
2022年5月31日当前最新版本是5.8.2,可以通过如下命令下载:
$ wget https://github.com/lutzroeder/netron/releases/download/v6.0.9/Netron-Setup-6.0.9.exesource: https://github.com/lutzroeder/netron/releases
$ docker login
$ docker pull snser/anaconda3:latest
$ docker run --name anaconda3 -itv your_path/Paddle-Lite:/workspace -w /workspace -d snser/anaconda3 /bin/bash
$ docker exec -it anaconda3 /bin/bash
$ conda env list
$ conda activate python3.7
$ lite/tools/build_linux.sh --arch=x86 \
--toolchain=gcc \
--with_extra=ON \
--with_python=ON \
--python_version=`python --version | cut -d ' ' -f 2 | cut -d '.' -f -2` \
--with_log=ON \
--with_exception=ON \
--with_profile=ON \
--with_precision_profile=ON \
--with_static_mkl=ON \
--with_avx=ON \
--with_opencl=ONEnglish | 简体中文

Paddle Lite 是一个高性能、轻量级、灵活性强且易于扩展的深度学习推理框架,定位于支持包括移动端、嵌入式以及边缘端在内的多种硬件平台。
当前 Paddle Lite 不仅在百度内部业务中得到全面应用,也成功支持了众多外部用户和企业的生产任务。
使用 Paddle Lite,只需几个简单的步骤,就可以把模型部署到多种终端设备中,运行高性能的推理任务,使用流程如下所示:
一. 准备模型
Paddle Lite 框架直接支持模型结构为 PaddlePaddle 深度学习框架产出的模型格式。目前 PaddlePaddle 用于推理的模型是通过 save_inference_model 这个 API 保存下来的。 如果您手中的模型是由诸如 Caffe、Tensorflow、PyTorch 等框架产出的,那么您可以使用 X2Paddle 工具将模型转换为 PaddlePaddle 格式。
二. 模型优化
Paddle Lite 框架拥有优秀的加速、优化策略及实现,包含量化、子图融合、Kernel 优选等优化手段。优化后的模型更轻量级,耗费资源更少,并且执行速度也更快。 这些优化通过 Paddle Lite 提供的 opt 工具实现。opt 工具还可以统计并打印出模型中的算子信息,并判断不同硬件平台下 Paddle Lite 的支持情况。您获取 PaddlePaddle 格式的模型之后,一般需要通过该 opt 工具做模型优化。opt 工具的下载和使用,请参考模型优化方法。
三. 下载或编译
Paddle Lite 提供了 Android/iOS/x86/macOS 平台的官方 Release 预测库下载,我们优先推荐您直接下载 Paddle Lite 预编译库,或者从 Release notes 处获取最新的预编译编译库。
Paddle Lite 已支持多种环境下的源码编译,为了避免复杂、繁琐的环境搭建过程,我们建议您使用 Docker 统一编译环境搭建 进行编译。当然,您也可以根据宿主机和目标设备的 CPU 架构和操作系统,在源码编译中找到相应的环境搭建及编译指南,自行完成编译环境的搭建。
四. 预测示例
Paddle Lite 提供了 C++、Java、Python 三种 API,并且提供了相应 API 的完整使用示例:
您可以参考示例中的说明快速了解使用方法,并集成到您自己的项目中去。
针对不同的硬件平台,Paddle Lite 提供了各个平台的完整示例:
- Android apps [图像分类] [目标检测] [口罩检测] [人脸关键点] [人像分割]
- iOS apps
- Linux apps
- Arm
- x86
- OpenCL
- Metal
- 华为麒麟 NPU
- 华为昇腾 NPU
- 昆仑芯 XPU
- 昆仑芯 XTCL
- 高通 QNN
- 寒武纪 MLU
- (瑞芯微/晶晨/恩智浦) 芯原 TIM-VX
- Android NNAPI
- 联发科 APU
- 颖脉 NNA
- Intel OpenVINO
- 亿智 NPU
- 支持多平台:涵盖 Android、iOS、嵌入式 Linux 设备、Windows、macOS 和 Linux 主机
- 支持多种语言:包括 Java、Python、C++
- 轻量化和高性能:针对移动端设备的机器学习进行优化,压缩模型和二进制文件体积,高效推理,降低内存消耗
| System | x86 Linux | ARM Linux | Android (GCC/Clang) | iOS |
|---|---|---|---|---|
| CPU(32bit) | ||||
| CPU(64bit) | ||||
| OpenCL | - | - | - | |
| Metal | - | - | - | |
| 华为麒麟 NPU | - | - | - | |
| 华为昇腾 NPU | - | - | ||
| 昆仑芯 XPU | - | - | ||
| 昆仑芯 XTCL | - | - | ||
| 高通 QNN | - | - | - | |
| 寒武纪 MLU | - | - | - | |
| (瑞芯微/晶晨/恩智浦) 芯原 TIM-VX | - | - | ||
| Android NNAPI | - | - | - | |
| 联发科 APU | - | - | - | |
| 颖脉 NPU | - | - | - | |
| Intel OpenVINO | - | - | - | |
| 亿智 NPU | - | - | - |
Paddle Lite 的架构设计着重考虑了对多硬件和平台的支持,并且强化了多个硬件在一个模型中混合执行的能力,多个层面的性能优化处理,以及对端侧应用的轻量化设计。
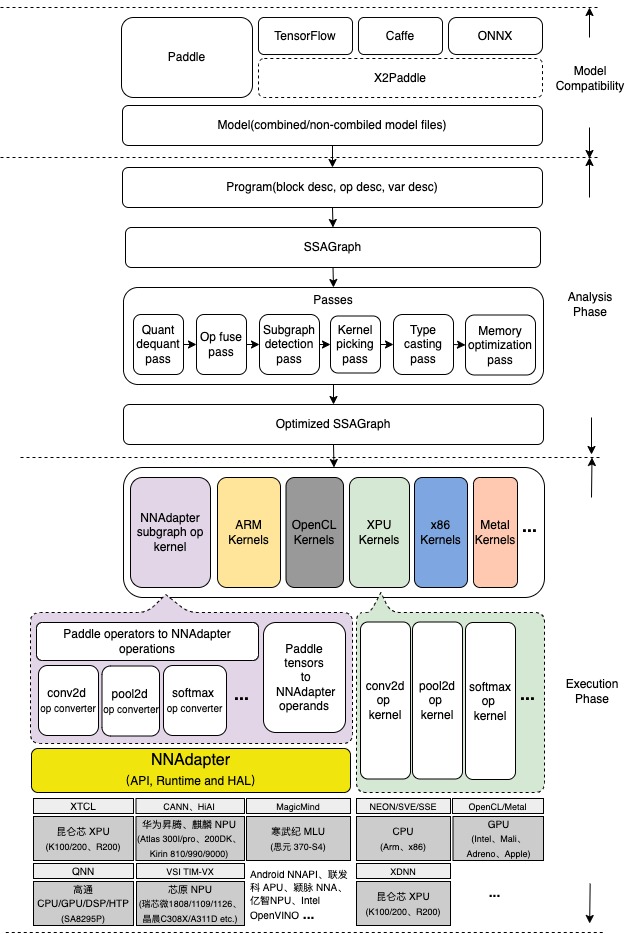
其中,Analysis Phase 包括了 MIR(Machine IR) 相关模块,能够对原有的模型的计算图针对具体的硬件列表进行算子融合、计算裁剪 在内的多种优化。Execution Phase 只涉及到 Kernel 的执行,且可以单独部署,以支持极致的轻量级部署。
如果您想要进一步了解 Paddle Lite,下面是进一步学习和使用 Paddle Lite 的相关内容:
- 完整文档: Paddle Lite 文档
- API文档:
- Paddle Lite 工程示例: Paddle-Lite-Demo
- 模型量化:
- 调试分析:调试和性能分析工具
- 移动端模型训练:点击了解一下
- 飞桨预训练模型库:试试在 PaddleHub 浏览和下载 Paddle 的预训练模型
- 飞桨推理 AI 硬件统一适配框架 NNAdapter:点击了解一下
- FAQ:常见问题,可以访问 FAQ、搜索 Issues、或者通过页面底部的联系方式联系我们
- 贡献代码:如果您想一起参与 Paddle Lite 的开发,贡献代码,请访问开发者共享文档
- AIStudio 实训平台端测部署系列课程:https://aistudio.baidu.com/aistudio/course/introduce/22690
- 欢迎您通过 Github Issues 来提交问题、报告与建议
- 技术交流微信群:添加 wechat id:baidupaddle或扫描下方微信二维码,添加并回复小助手“端侧”,系统自动邀请加入;技术群 QQ 群: 一群696965088(已满) ;二群,959308808;


微信公众号 官方技术交流QQ群
- 如果您对我们的工作感兴趣,也欢迎加入我们 !
Paddle Lite由 Apache-2.0 license 提供。