-Cortana: Windows assistant
-Siri: Apple's assistant and apple homepod assistant
-Google Assistant: Android assistant and Google Home assistant
-Alexa Amazon home assistant
Multilayer perceptron (MLP)
Convolutional neural network (CNN)
Recursive neural network (RNN)
Recurrent neural network (RNN)
Long short-term memory (LSTM)
Sequence-to-sequence models
Shallow neural networks
Nas redes Feedforward as camadas de rede são independentes umas das outras, assim, uma camada pode ter um número arbitrário de nós (sendo que, tipicamente, o número de nós arbitrários tem de ser superior ao de nós de input). Quando aplicadas a funções de aproximação, geralmente existe um input e um output. Por contraste, quando usadas como classificadores, o número de nós de input e output irá corresponder o número de características de input e o número de classes de output, respetivamente. Adicionalmente, terá de ter no mínimo uma camada oculta e todos os nós das camadas têm peso 1.
O principal objetivo das redes Feedforward é fazer uma aproximação de uma dada função f. Por exemplo, a função y = f(x) atribui a um dado valor de x um valor de y. Uma rede Feedforward define o mapeamento através de uma função y = f(x, θ), aprendendo os valores do parâmetro θ que resultam na melhor função de aproximação. Estas redes são representadas por uma série de diferentes funções. Cada rede é também acompanhada por um grafo acíclico dirigido:

Por exemplo, podemos ter três funções, f(1), f(2) e f(3) interligadas formando então f (x) = f(3)(f (2)(f (1)(x))). Neste caso, f(1) é primeira camada de input, f(2) a segunda e f(3) a camada de output. As camadas entre as camadas de input e output são conhecidas como “camadas ocultas”, sendo que o traning data não expressa o output desejado a estas camadas. A rede pode conter infinitas camadas de camadas ocultas com um qualquer número de unidades. Uma unidade representa um neurónio que obtém o input de unidades de camadas prévias e calcula o seu valor de ativação.
A utilidade no uso das redes Feedforward surge nos modelos lineares estarem limitados a utilizar apenas funções lineares, algo que não acontece com redes neuronais. Quando uma determinada amostra está impossibilitada de ser separada linearmente, os modelos lineares apresentam alguma dificuldade a fazer aproximações, contrastando com a facilidade apresentada nos modelos neuronais. As camadas ocultas são, portanto, usadas para aumentar a “não linearidade” e alterar a representação de uma data amostra para uma melhor generalização de uma função
Add additional weights to the network to create cycles in the network graph in an effort to maintain an internal state
By adding state to a neural network we will be able to explicitly learn and exploit context in sequence prediction problems,
like humans who can recognize something as they move towards that same thing, machines will also be able to recognize and make predictions base on movement and temporal data.
In our Case of study the RNN is used to convert input sequences into a sequence of character probabilities for the transcription.
In deep learning, a convolutional neural network (CNN, or ConvNet) is a class of deep neural networks, most commonly applied to analyzing visual imagery. They are also known as shift invariant or space invariant artificial neural networks (SIANN), based on their shared-weights architecture and translation invariance characteristics. They have applications in image and video recognition, recommender systems,[3] image classification, medical image analysis, and natural language processing.
Na área de redes neuronais, CNN (redes de convolução) são uma das principais categorias para análise e classificação de imagens, como tal o uso deste tipo de rede torna-se bastante reincidente quando o objetivo é detetar objetos, reconhecer individuos ou até ler textos manuscritos. Na nossa abordagem ao reconhecimento de voz, iremos dissecar a utilidade desta rede quando o assunto de estudo se trata não de uma simples imagem de duas dimensões (alturaxlargura), mas sim de reconhecer uma voz, algo dependente de uma quantidade descomunal de variaveis.
Uma convolução é a primeira camada de acesso a dados, que extrai com base num input uma amostra. Com essa amostra são depois extrapolados detalhes acerca do input aplicando um filtro/kernel. Um kernel é uma matrix menor que a matrix de input, também denominada de matrix de convolução, cuja função é iterar a matriz de input aplicando-lhe um produto.
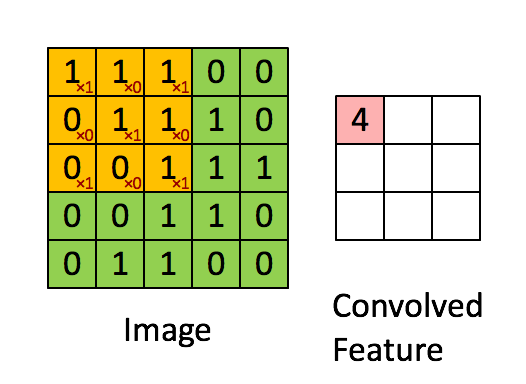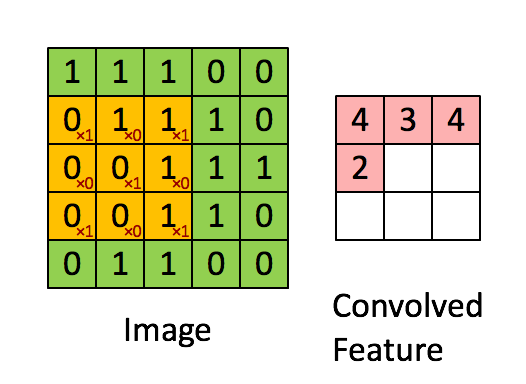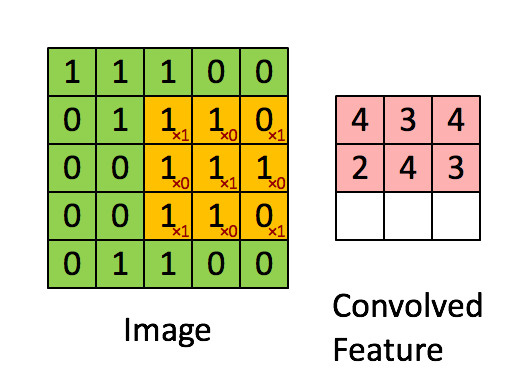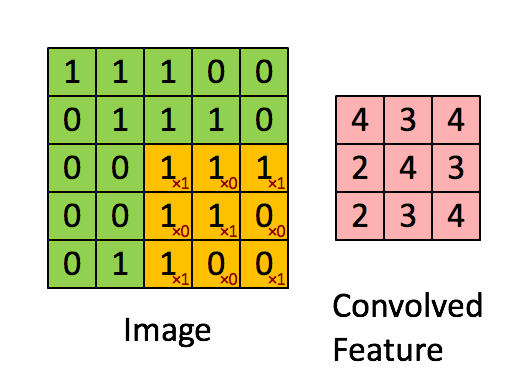
Quando o objetivo é extrair do output multiplas propriedades usamos vários kernels do mesmo tamanho, de modo a que o resultado destes filtros seja empilhavel.

Numa última fase da convolução é aplicada á matrix filtrada uma função de activação (normalmente sendo esta uma função de ReLu ou de Tanh) com o intuito de deslinearizar o output.

Utilizando algoritmos estas redes podem reconhecer padrões e correlações em dados de grande volume.
No estudo de reconhecimento de voz e principalmente no estudo de reconecimento de imagem podemos chegar à conclusão que as redes de convulução são muito mais poderosas na classificação de dados do que uma rede feed forward, isto acontece com base nas extrações de amostras de um determinado input, ou seja, quando temos um elevado número de inputs as redes de convulução tendem a ser muito eficientes pois reduzem este número de inputs em grande escala. Especificamente em reconhecimento de voz frequentemente classificamos os dados em espectogramas, fazendo isto os nossos dados ficam a parecer-se bastante como imagens que podemos classificar para descobrirmos os seus padrões, o que nos leva a concluir que redes de convulução são uma melhor escolha devido ao número de inputs.
Back-propagation (conhecido como backprop) é um algoritmo vastamente utilizado no treino de redes Feedforward na área de Machine Learning. Existem também generalizações para redes ANN (Artificial Neural Networks).
A técnica de backprop calcula eficazmente o gradiente da função de erro com os respetivos pesos da rede para cada par de input e output. Desta forma, torna-se possível utilizar o gradiente para o treino de redes de várias camadas, alterando os pesos para minimizar a erro. Normalmente, são usadas a descida do gradiente ou o SGD (Stochastic Gradient Descent). A técnica em questão acaba por ser a essência do treino de redes neuronais.
O algoritmo de Back-propagation calcula a descida do gradiente da função de erro com o respetivo peso através da regra da cadeia, iterando para trás, camada a camada, da última cadeia, evitando cálculos redundantes. Através da função de erro da iteração anterior, os pesos da rede neuronal são ajustados. O ajuste dos pesos visa a garantir a menor margem de erro possível tornando assim o modelo o mais estável possível.

{kind=link}
-https://nordicapis.com/5-best-speech-to-text-apis/
-https://machinelearningmastery.com/recurrent-neural-network-algorithms-for-deep-learning/
-https://www.quora.com/Which-neural-network-type-is-best-for-speech-recognition-and-speech-synthesis
-https://www.coursera.org/lecture/nlp-sequence-models/different-types-of-rnns-BO8PS
-https://medium.com/towards-artificial-intelligence/introduction-to-the-architecture-of-recurrent-neural-networks-rnns-a277007984b7
-https://medium.com/@datamonsters/artificial-neural-networks-for-natural-language-processing-part-1-64ca9ebfa3b2
-https://towardsdatascience.com/beginners-guide-to-understanding-convolutional-neural-networks-ae9ed58bb17d
-https://towardsdatascience.com/feed-forward-neural-networks-c503faa46620
-https://dzone.com/articles/the-very-basic-introduction-to-feed-forward-neural
-https://towardsdatascience.com/how-does-back-propagation-in-artificial-neural-networks-work-c7cad873ea7
-https://medium.com/datathings/neural-networks-and-backpropagation-explained-in-a-simple-way-f540a3611f5e
-https://en.wikipedia.org/wiki/Backpropagation
-https://towardsdatascience.com/what-the-hell-is-perceptron-626217814f53