Learn to scrape a basic website step-by-step using Python. It is very easy to do and you can refer to my work.
You will learn:
- Basic python
- How to scrape basic data from a website
- DataHandling
Here are the steps we will follow:
The tools which were used are (BeautifulSoup, pandas, requests, python)
- We are going to scrape http://quotes.toscrape.com/page/1/ ( I would recommend you to use this website).
- We will get a list of quotes for each quote we will grab there author name
Here's how we will do it:
- Use requests to download the webpage
- Use BeautifulSoup to parse and extract info.
- Convert to a pandas dataframe
pip install requests
To install the library (to be done in the terminal )
import requests
To import it
pip install BeautifulSoup4
To install beautifulsoup
from bs4 import BeautifulSoup
To import it
response = requests.get('http://quotes.toscrape.com/page/1/')
Downloads the page
page_contents = response.text
doc = BeautifulSoup(page_contents,'html.parser')
It parses the document using beautifulsoup
print(response.status_code)
To check if the page was downloaded successfuly ( It should return 200 if it was successful )
If you are getting '401' as an output.
This can occur for a number of reasons, including:
- The server requires a specific type of authentication that has not been provided in the request.
- The provided credentials are invalid or have expired.
- The resource is protected by a login page, and the client has not provided the necessary credentials to access the resource.
Try logging in to that website to gain authentication or you will need to use the requests.auth.HTTPBasicAuth class in the requests library.
print(len(page_contents))
It is not recommended to print it, but you can check the length
Now you have to locate the tags you want to scrape from the website. In my case, I want to scrape all of the quotes. The quotes are inside the 'span' tag.

To locate all of the span tags use this function
span_tags = doc.find_all('span')
Now there are 32 span tags inside the webpage ( useprint(len(span_tags)) to check ) but we don't want all of those tags, obviously. We want the span tags which only have the quotes. So we can be more specific by checking their 'classes'
To check that you can right click and click on 'inspect elements' and then select on the quote. You can see that they all have the 'class'='text'. So to be more specific we can use this function. span_tags = doc.find_all('span',{'class':'text'})
Now if we check the length, you will see 10 as the output, that means we are going in the right direction
Now if we print them (print(span_tags)), you should see this as an output.

Now what we want is the text(quotes) inside the tag. You can use the .text function to check that. print(span_tags[0].text)
You should see this as an output
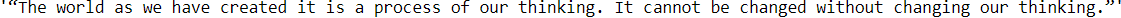
Now what we will do is create a list quotes = [] and create a for loop which will convert the tag into the text format which we want and append it to the list and then print it outside the for loop. Make sure to print it outside the for loop
##A loop which seperates the quotes which we want and puts it in a list
quotes = []
for tag in span_tags:
quotes.append(tag.text)
##Converts the tag into text and appends it to the list
print(quotes)
Output:

We will repeat the same for the author names.
small_tags = doc.find_all('small') ## Finds all the small tags insie the html document
##A loop which seperates the author names which we want and puts it in a list
author_names = []
for tag in small_tags:
author_names.append(tag.text)
print(author_names)
Output:

You can check in which tag are the author names located in using doc.find_all('Tag_Name')
Now we are almost done. We just need to install the pandas library and convert our data into a pandas dataframe
pip install pandas
To install pandas library i
import pandas as pd
To import it
##Create a dict and put in the list names which we created
dict = {'QUOTES_LIST' : quotes,
'AUTHORS_LIST': author_names}
##Creates the data frame
table_df = pd.DataFrame(dict)
##Converts to a csv file
table_df.to_csv('file_name.csv', index=None)
Thank you for reading. If you found this helpful please recommend my work to others and star this repo.