Project Report
对于一个神经细胞,如果它有n个突触,那么突触权重的数组可以表示为:
[w0, w1, w2, w3, ..., w(n-1)]
根据神经网络的定义,它所对应的输入数据也必须是n维,输入数据的数组可以表示为:
[x0, x1, x2, x3, ..., x(n-1)]
所以输入汇总值 y = w0 * x0 + w1 * x1 + w2 * x2 + ... + w(n-1) * x(n-1), 是个矩阵乘法
为了简化问题,不放偏置b,也不考虑激活函数,所以最终输出 Y = y
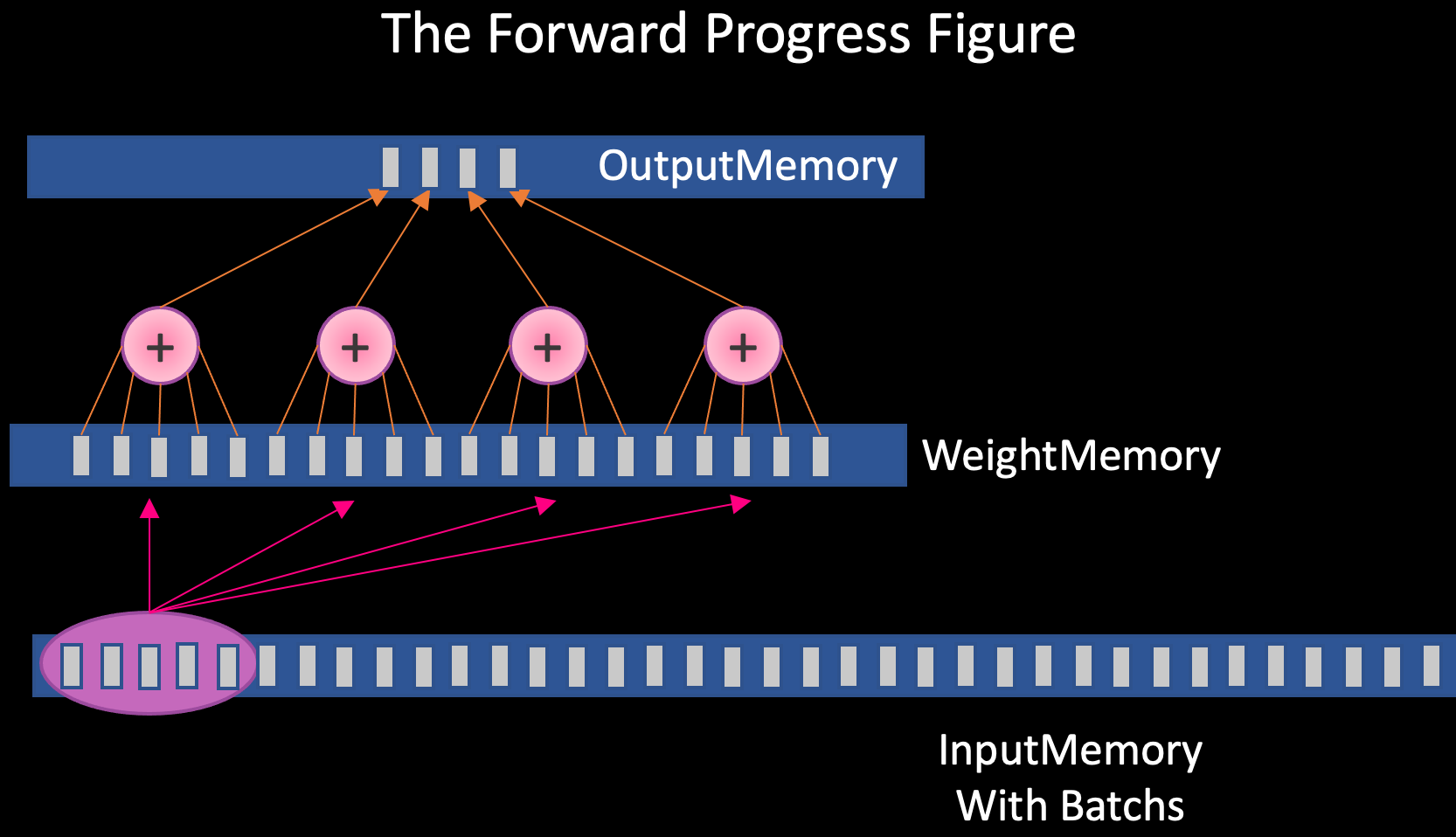
PyTorch的算子插件可访问每个Tensor的内(显)存,内存的分布如图所示,已知神经元数量CellNum,「神经元编号CellID,批次编号BatchID,神经元突触编号i」统一从0开始数,可知:
神经元突触权重的内存地址(偏移量)= CellID * n + i
突触输入数据的内存地址(偏移量)= BatchID * n + i
神经元输出数据的内存地址(偏移量)= BatchID * CellNum + CellID
把地址偏移量加上对应的基址就是目标地址了
顾名思义,反向传播就是前向传播倒着来!
具体来说,你可以把上面的图中每个神经细胞想象成一个花洒🚿,然后沿轴突->树突的方向去泼💦
单位时间内,越粗的树突泼出来的递质量越大(正比)💧(为了简单问题没考虑激活函数)
哈哈哈,形象吧~听起来有点像狂犬病病毒逆着神经末梢传播?
当然,它的数学原理是链式求导法则
前向传播没啥需要特别注意的,对于CUDA编程一个GPU线程(可能是Core)模拟一个神经细胞就行,然后循环遍历Batch;对于CPU就for循环嵌套😂
反向传播在CUDA编程时还真得注意一下访问冲突问题,不能多个神经元同时往一个输出内存去泼(如果能就好了,也许多量子位的计算机可以?)
我想了个主意就是用Kaso(幻想)神经元,Kaso输出内存也是一排神经元(其实是下层的神经元),这样就能并行化避免访问冲突了
其实并行时的每个Thread,它里面也是串行的for循环遍历每个突触进行求和,所以神经元数量越多,CUDA可能越比CPU有优势
GPU的串行处理能力比CPU弱吗?弱在哪?指令集少还是算的慢?
| 硬件环境 | CPU(vCPU数目) | Intel(R) Core(TM) i9-9820X CPU @ 3.30GHz(10核) |
| GPU(型号,数目) | NVIDIA Geforce RTX 2080Ti 1块(4352核) | |
| 软件环境 | OS版本 | Ubuntu 20.04 LTS Desktop |
| 深度学习框架 python包名称及版本 |
Python 3.8 PyTorch 1.7.0 |
|
| CUDA版本 | 10.1 | |
本实验中测量的推理时间不包含Tensor内存拷贝、Python解释过程消耗的时间
代码位置:ROOT/Research_myLinear_Forward.py
运行命令(Benchmark功能只在Linux下可用,如果用Windows请修改Benchmark相关代码):
cd myLinear_CUDA_backend
python3 setup.py install
cd .. && python3 Research_myLinear_Forward.py
请修改Research_myLinear_Forward.py代码以设定推理硬件、Batchsize、神经元数量
当Bachsize = 4
| 实现方式 | 性能评测(神经元数为5) | 性能评测(神经元数50) | 性能评测(神经元数为500) |
|
CPU only |
去除首次运行时间后,99次平均5.13ms | 去除首次运行时间后,99次平均7.52ms | 去除首次运行时间后,99次平均24.17ms |
|
With CUDA |
去除首次运行时间后,99次平均12.95ms | 去除首次运行时间后,99次平均12.41ms | 去除首次运行时间后,99次平均12.41ms |
代码位置:ROOT/Research_Kakuritsu_Forward.py
运行命令(Benchmark功能只在Linux下可用,如果用Windows请修改Benchmark相关代码):
cd myKakuritsu_Linear_backend
python3 setup.py install
cd .. && python3 Research_Kakuritsu_Forward.py
请修改Research_Kakuritsu_Forward.py代码以设定推理硬件、Batchsize、神经元数量
当Bachsize = 4
| 实现方式 | 性能评测(神经元数为5) | 性能评测(神经元数50) | 性能评测(神经元数为500) |
|
CPU only |
去除首次运行时间后,99次平均27.53ms | 去除首次运行时间后,99次平均230.16ms | 去除首次运行时间后,99次平均2307.77ms |
|
With CUDA |
去除首次运行时间后,99次平均15.53ms | 去除首次运行时间后,99次平均12.78ms | 去除首次运行时间后,99次平均16.98ms |
将数据拷贝到显存需要花费时间,初始化GPU及发布指令也需要花费时间。当并发量大时,能体现出GPU的优势。