Agent Only Learns to Rotate rather than move (always)!! (Best Formatted Issue So far!!😂) #1457
Comments
|
I have noticed similar behavior from my Agents, it looks like sometimes they get stuck in a local minima and they just going around in circles eating up food. Not sure how to fix? |
|
One thing I can see from your graphs is that entropy is increasing. When that happens to me it usually means that the task is too hard for the agent and he is not getting enough rewards. Entropy increasing means that the agent is becoming less confident about how good his actions are, essentially he is picking more random actions. How does this small closing in reward work? It feels like it is a one time reward and after getting it the agent decides that there is nothing more to get and he should just take random actions. So you could either make this reward continuous, i.e reward him every time the agent gets closer than the last frame. |
|
@LeSphax , I think you are right about Entropy. I am starting to think if the task is too difficult? |
|
Hey @ust007, Just to make sure I understand the reward and penalty that the agent gets for moving close/ going away, could you detail it further or maybe show me the code? Now that I think about it, maybe the penalty for going away is the problem here. I think it is generally better to avoid giving penalties to an agent that are caused by his actions. I.e: Because until the agent understands the difference between moving away and moving closer he will just understand that whenever he moves he has a 50/50 chance of getting a penalty or getting a reward. You say you tried to put the goal close to the agent, but how close did you put it? My idea was at first to put the goal so close to the agent that he will walk on it by chance quite often. This way you wouldn't need to rely on your getting closer reward, the reward of +1 if the agent collides with the Target should be enough. About the rayPer.Perceive thing, it's hard to follow what you did exactly. It looks like you changed the environment manually in the middle of the training session. So to summarize:
|
|
thanks @LeSphax , First about the curriculum learning i didn't get the part where you said
what does this mean..
lemme explain what result I want.
Now about the reward/penalty thing.. this is the code.. AddReward((previousDistance - distanceToTarget) / CurrentEpDistance); previous dist: the distance b/w the target and agent in last step. Overall, I wanted to reward the agent only with +1(after addition from all the steps) in an episode if he moves the full distance b/w the agent and target. |

|
About the curriculum you should try to read the documentation but basically it allows to create several lessons. 1- The goal is very close to the agent So using you can just retrain the agent from scratch everytime (i.e without using --load). About your code, it seem to be correct but it might improve without the penalty. |
|
I have trained agents to locate goals when the agent's position and the goal's location are randomized as well, and in my experience, the agent will rotate in one direction when it starts off every time because it is looking for either the goal or something it recognizes, such as a corner or a specific obstacle. Once it sees something it is looking for, it will then move in that direction. The reason why it moves backwards towards the goal is because of your distance reward. The agent learns that it will waste time by spinning around, so it tries to solve it by moving backwards instead since it can get a positive reward by moving backwards. If you get rid of the backwards action, it will guarantee that it needs to move using the ray face. |
|
@atapley I get your point about the rotation. But about the backward movement.. u said
|
|
The agent would need to turn around to face the goal which involves more actions than just moving backwards, meaning more negative time step rewards. The reason behind it learning as it trains more can just be that after getting stuck on an obstacle for a while due to it moving backwards, it learns that it's better to move forwards. But at least in the early stages of training, that is a possibility for the issue. |
|
@atapley Yeah you are right. Thanks for the help. |
|
Thanks for reaching out to us. Hopefully you were able to resolve your issue. We are closing this due to inactivity, but if you need additional assistance, feel free to reopen the issue. |
|
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs. |
Hey, I know this is too much to read, but I tried to Explain the problem in the best way.
So I wanted to train an agent to reach a target at some random distance on the x-z plane with obstacles in between. My agent and Target are both on the same plane.

Both are spawning at random locations in a range of 30f.
INPUTS(Continous)
x and z relative position of the target
AddVectorObs(relativePosition.x / 30f);
AddVectorObs(relativePosition.z / 30f);
5 rayPer.Percieve at different angles. Same as the Hallway Example
Code:
float rayDistance = 10f;
float[] rayAngles = { 20f, 60f, 90f, 120f, 160f };
AddVectorObs(GetStepCount() / (float)agentParameters.maxStep);
also copied from Hallway Example (Up to my understanding this gives a sense of time to agent.).
If the agent is on bad road or not. which is for now always 0 as i haven't introduced.
AddVectorObs(OnRoad ? 1 : 0);
OUTPUTS (Continous) :
only 2 one to move forward and backward
another one to rotate left and right
And its exactly same as the Hallway Example
Rewards
+1 if the anent collides with the Target
Time Penalty : AddReward(-1f / agentParameters.maxStep);
And a small close in reward and small penalty to move away.
Now the parameter of .yaml file is exactly same as Hallway Example.
Tried a lots of different things but nothing worked so just copied it.
Training-- All the training done with obstacles disabled.
100f time scale
PPO-LSTM
Same as Hallway
When the target is in the range of rayPer.Percieve
At First the agent learns to rotate and keeps on rotating to about 150k steps and after that it moves and starts to close in the target 2-3 times but doesn't reaches it. but after that it knows that closing in gives positive reward, so it does that everytime..
A=> so basically after every reset it starts rotating (and that too its always same direction) and when rayPer.Percieve detects Target it closes in..
So, its trained? see further...
In the above training nearly at 300k I decided to increase the distance of the target.
Now, if the target is in the range of rayPer.Percieve then it does the same as A (statement A in 1st point of training.)
and if the target is far off then it just keeps on rotating (same direction as usual) and sometimes random motion to move forward and rotate at the same time.
So no Success :( after 600k steps.
So at 600k I changed all the Target positions are out of range for rayPer.Percieve.
Result - Keeps on rotating..
After 1 , 2 and 3 i thought to train it from scratch and from starting the Target will be out of range for rayPer.Percieve.
Again no success ... just learns to rotate ( same direction) and v v less movements.
No Success even when the Obstacles were Disabled.
So, if someone can help and guide me or any suggestions will be helpful.
My thinking what can be wrong
but I also did the training step 1 and 2 with use_recurrent: false. So maybe LSTM is not the problem.
Next things I am gonna try-
PS: I really wanna know why it keeps on learning to rotate always, and that too in the same direction.
Also, this took me an hour to type while my stupid Agent was again learning to rotate in Background. 😂😂😂
All the screenshots of the Results -
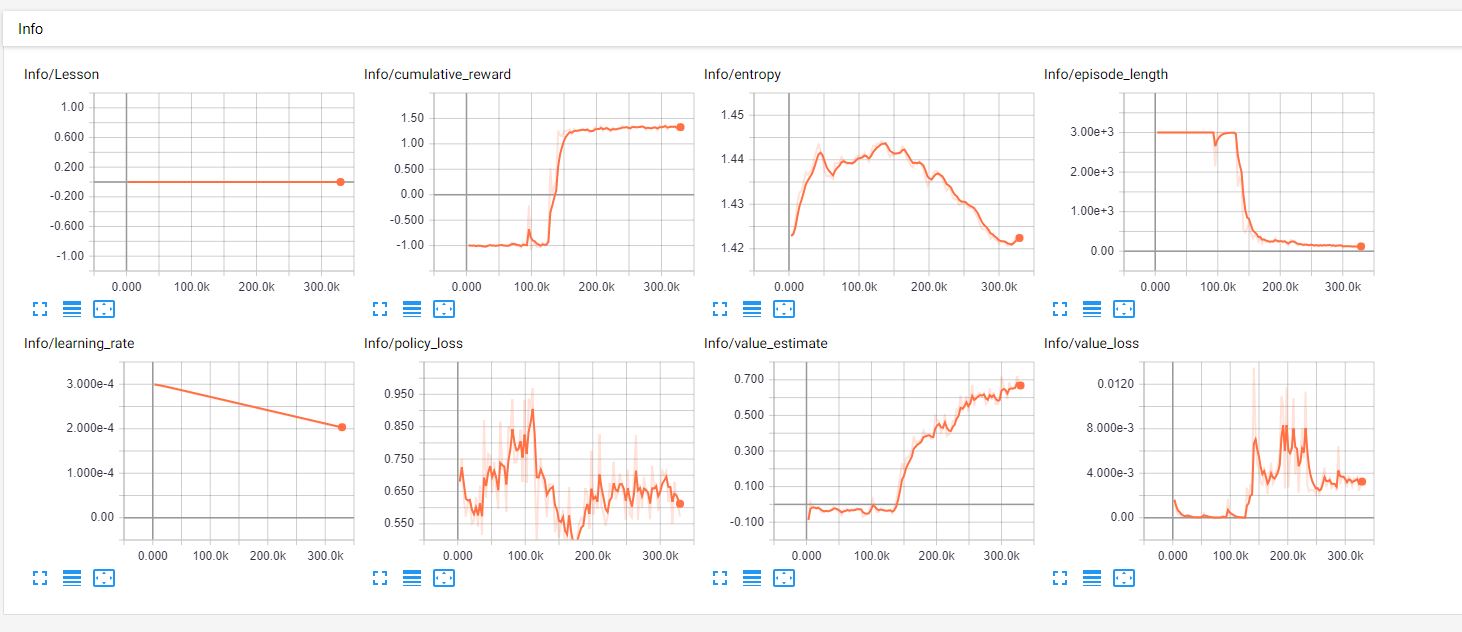
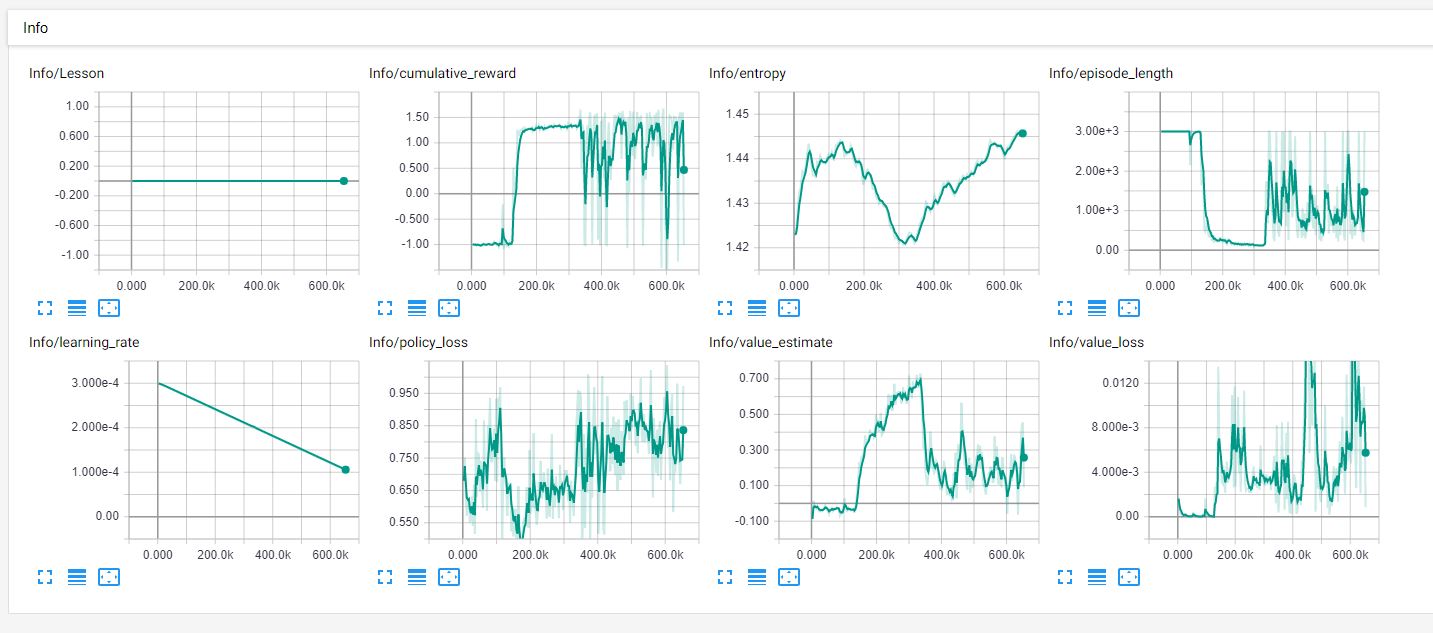
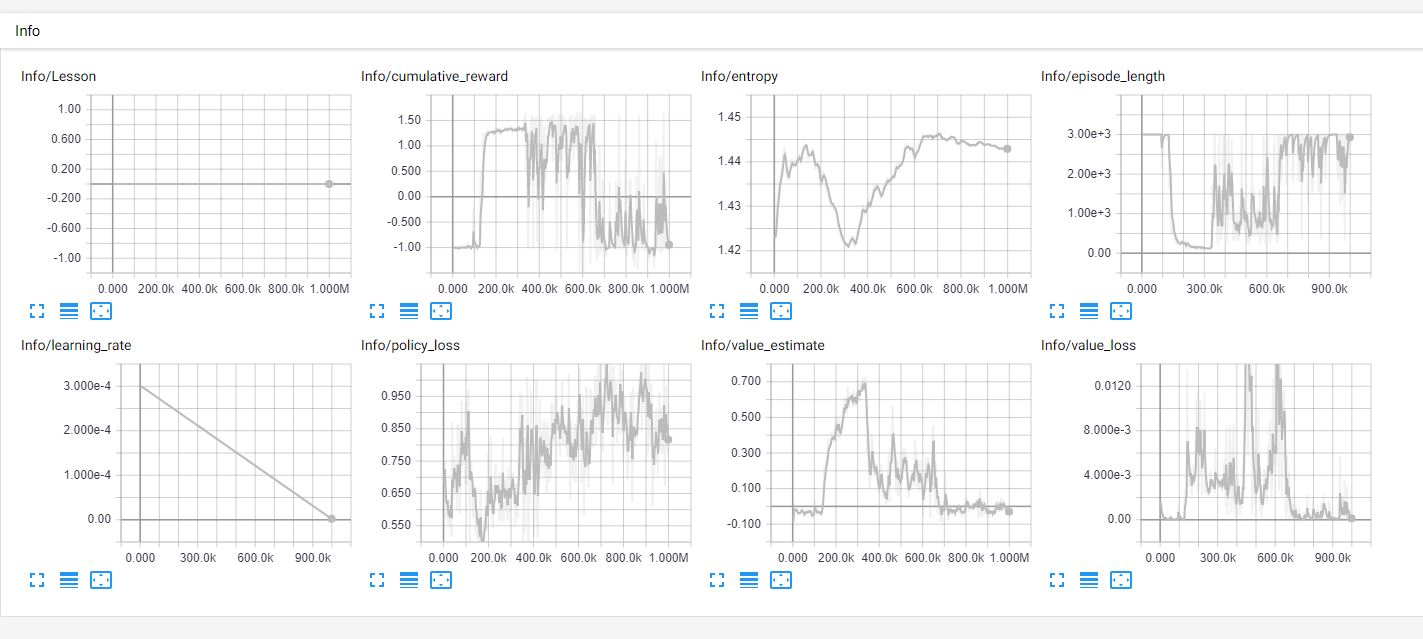
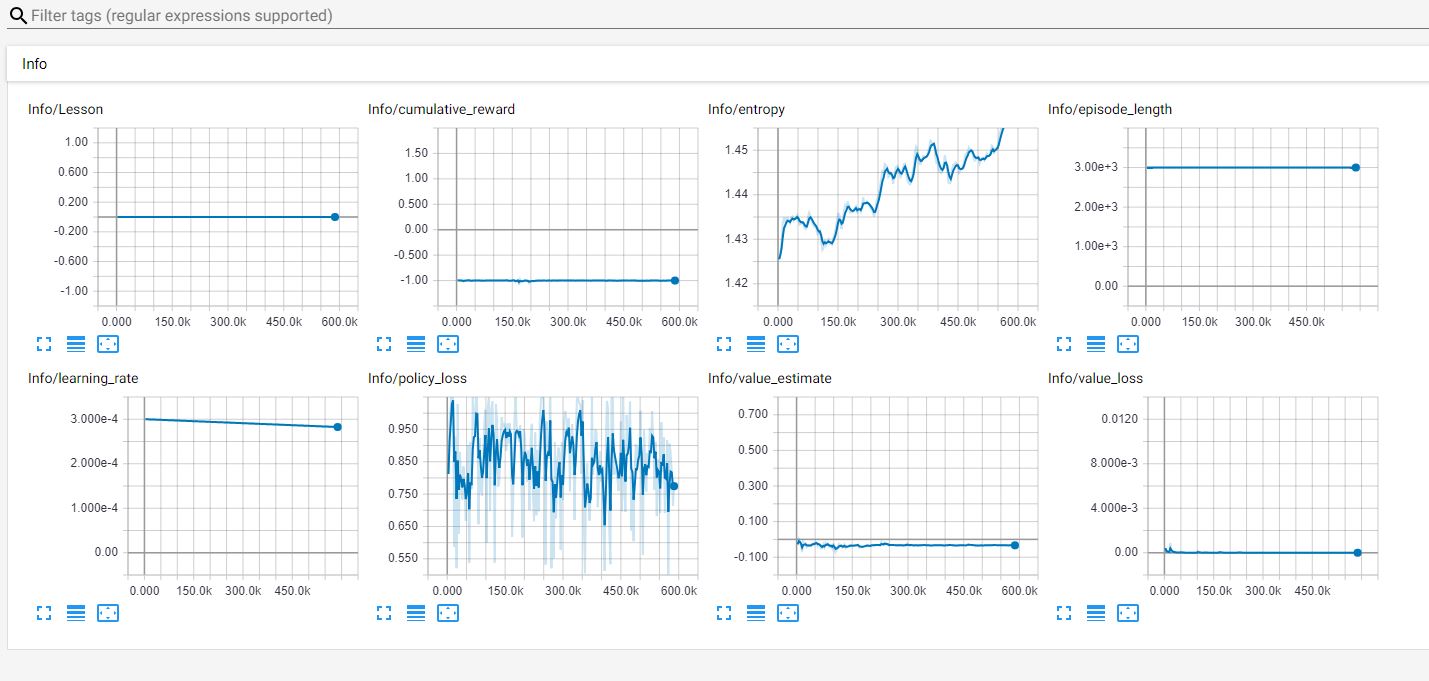
TRAINING-1
TRAINING-2
TRAINING-3
TRAINING-4
The text was updated successfully, but these errors were encountered: