
Iguvium extracts tables from PDF file in a structured form. It works like this.
Take this PDF file:
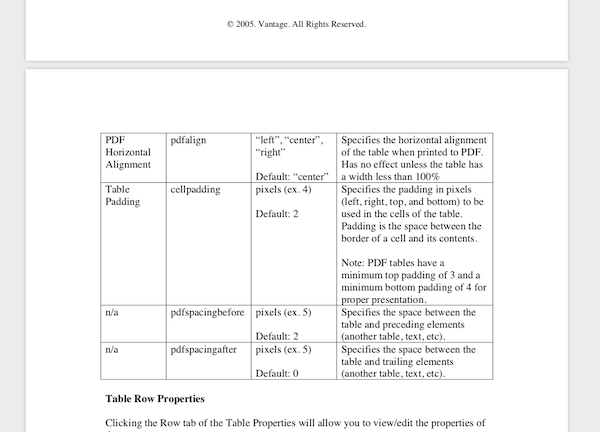
Use this code:
pages = Iguvium.read('filename.pdf')
tables = pages[1].extract_tables!
csv = tables.first.to_a.map(&:to_csv).join
Get this table:

-
Iguvium renders pdf into an image, looks for table-like graphic structure and tries to place characters into detected cells.
-
Characters extraction is done by PDF::Reader gem. Some PDFs are so messed up it can't extract meaningful text from them. If so, so does Iguvium.
-
Current version extracts regular (with constant number of rows per column and vise versa) tables with explicit lines formatting, like this:
.__________________.
|____|_______|_____|
|____|_______|_____|
|____|_______|_____|
And, after version 0.9.0, like this:
__|____|_______|_____|
__|____|_______|_____|
__|____|_______|_____|
Merged cells content is split as if cells were not merged unless you use :phrases option.
- Performance: considering the fact it has computer vision under the hood, the gem is reasonably fast. Full page extraction takes up to 1 second on modern CPUs and up to 2 seconds on the older ones.
Make sure you have Ghostscript installed.
Linux: sudo apt-get install ghostscript
Mac: brew install ghostscript
Windows: download installer from the official download page.
Add this line to your application's Gemfile:
gem 'iguvium'And then execute:
$ bundle install
Or install it yourself as:
$ gem install iguvium
If you're not a developer and have a Mac, you maybe have default Ruby installation and no development tools installed.
In this case, run xcode-select --install beforehand, and after that install Iguvium as admin: sudo gem install iguvium
pages = Iguvium.read('filename.pdf') #=> [Array<Iguvium::Page>]
tables = pages.flat_map { |page| page.extract_tables! } #=> [Array<Iguvium::Table>]
tables.map(&:to_a)
pages = Iguvium.read('filename.pdf')
tables = pages[7].extract_tables!
tables.first.to_a
Gem installation adds a command-line utility to the system. It's a simple wrapper:
iguvium filename.pdf [options]
-p, --pages page numbers, comma-separated, no spaces
-i, --images use pictures in pdf (usually a bad idea)
-n, --newlines keep newlines
--phrases keep phrases unsplit, could fix some merged cells
-t, --text extract full page text instead of tables
--verbose verbose output
Given a filename, it generates CSV files for the tables detected or, with -t option,
just page text. The latter is useful in case of whitespace-separated fixed-width tables.
There are usually no actual tables in PDFs, only characters with coordinates, and some fancy lines. Human eye interprets this as a table. Iguvium behaves quite similarly. It prints PDF to an image file with GhostScript, then analyses the image.
(Later clarification as per request. It only prints anything but text and images (-dFILTERTEXT -dFILTERIMAGE params of GhostScript, which lefts lines, curves, etc.) to analyze table structure. Text fields are extracted from pdf codepoints, if there are any. Trying to do otherwise would imply a full-blown OCR solution, something like FineReader. So with scanned image-only pdfs it is like an ideal unmatch: nothing is actually printed and there's no text to extract.)
Long enough continuous edges are interpreted as possible cell borders. Gaussian blur is applied beforehand to get rid of possible inconsistencies and style features.
Initially inspired by camelot idea of image analysis to detect table structure. Besides this idea, is an independent work. Image recognition is written in Ruby, no OpenCV or other heavy computer vision libraries are used. Line detection algorithms are different too. The functionality of Camelot is significantly broader.
The next version will keep open-edged rows metadata ('floorless' and 'roofless') for the needs of multipage tables merger.
The final one will recognize tables with merged cells.
There are at the moment no plans to design recognition of whitespace-separated tables.
The gem is available as open source under the terms of the MIT License.
Just a place (ancient) where some tables (incredibly cool ones) were found.