- 4.1 -AVG
- 4.4 Sum
SQL Structured Query Language en español Lenguaje de consulta Estructurado, es un lenguaje específico utilizado en programación, diseñado para administrar, y recuperar información de sistemas de gestión de bases de datos relacionales.
Una de sus principales características es el manejo de álgebra y el cálculo relacional para realizar consultas y obtener información de forma sencilla, y además para realizar cambios en ella.
T-SQL (Transact-SQL) es la manera en que se comunican las instrucciones de manipulación de datos que gestiona el usuario con el Servidor; las cuales permiten realizar operaciones claves en SQL Server, como creación y modificación de esquemas de base de datos, inserción y modificación de datos y además la administración del propio Servidor de Base de Datos.
Esto se realiza mediante el envío de sentencias e instrucciones en T-SQL que son procesadas por el servidor y los resultados regresan a la aplicación cliente.
Transact-SQL incluye características propias de cualquier lenguaje de programación que nos permiten definir:
Tipos de datos.
Definición de variables.
Estructuras de control de flujo.
Gestión de excepciones.
Funciones predefinidas.
Crear interfaces de usuario.
Crear aplicaciones ejecutables.
Es un sistema de manejo de bases de datos del modelo relacional, desarrollado por la empresa Microsoft.
El lenguaje utilizado (que puede ser ejecutado por línea de comandos o mediante la interfaz gráfica de Management Studio) es Transact-SQL T-SQ
La información, al igual que ocurre con el peso o con el volumen, se puede medir. Dependiendo de si tenemos más o menos cantidad de información usaremos unas u otras de las siguientes unidades de medida:
bit (b): Es la unidad más pequeña de información. La palabra bit proviene de Binary digIT , es decir dígito binario en castellano.Los únicos valores de información que puede contener son 0 y 1.Como vimos en la sección anterior un bit de información almacenado por ejemplo en la memoria RAM equivaldría a un transistor con voltaje bajo si tiene almacenado un 0 o con voltaje normal si tiene almacenado un 1:
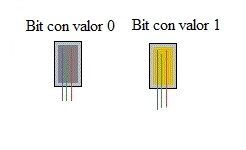
**Byte (B):**Equivale a 8 bits, y es la cantidad necesaria de bits para almacenar un carácter. Por ejemplo un archivo de texto con 10 caracteres, ocuparía en memoria 10 bytes o lo que es lo mismo 80 bits.
1 B = 8 bits
**Kilobyte (KB):**Un Kilobyte es igual a 1024 Bytes. Esta unidad de medida se usa para expresar la cantidades pequeñas de información.
1 KB=1024 Bytes= 210 Bytes
**Megabyte(MB):**Un Megabytes es igual a 1024 Kilobytes. Se usa para cantidades medianamente grandes de información, por ejemplo para expresar lo que ocupa un archivo de música.
1 MB= 1024 KB= 220 Bytes
Gigabyte (GB): Un Gigabye son 1024 Megabytes. Esta unidad se usa para cantidades grandes de información como por ejemplo para expresar la capacidad de un disco duro.
1 GB= 1024 MB= 230 Bytes
Terabyte (TB): El Terabyte equivale a 1024 GB. Se utiliza para cantidades enormes de información como para medir la capacidad de almacenamiento de una supercomputadora o de algunos discos duros actuales.
1 TB= 1024 GB= 240 Bytes
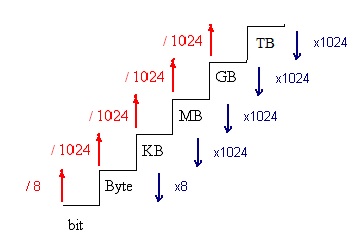
En el siguiente esquema vemos un resumen en forma de escalera de cómo hacer las conversiones entre las diferentes unidades de medida de la información, para pasar de una unidad más grande a otra más pequeña,es decir bajar escalones, multiplicaremos y para pasar de una más pequeña a otra mayor, es decir subir escalones, dividiremos:
0 ó 1
True o False
0 a 255
-2^15 (-32,768) HASTA 2^15-1 (32,767)
-2^31 (-2,147,483,648) HASTA 2^31-1 (2,147,483,647)
-2^63 (-9,223,372,036,854,775,808) HASTA 2^63-1 (9,223,372,036,854,775,807)
-922,337,203,685,477.5808 HASTA 922,337,203,685,477.5807
1. La clave primaria o primary key, identifica de manera unívoca (única) a cada registro de una tabla.
| IdPaciente | Nombre | Apellido | idPais | |
|---|---|---|---|---|
| i | Jorge | Rodriguez | a@a.com | MEX |
| 2 | Marcelo | Lope Llano | a@a.com | MEX |
| 3 | Kari | Lopreta | a@a.com | COL |
| 4 | Juan Manuel | Loerfano | a@a.com | ARG |
| 5 | Juan Manuel | Perez Lozano | a@a.com | ESP |
| 6 | Karim | Berragas | a@a.com | PER |
| 7 | Saul | Lpez Gomez | a@a.com | CHI |

Creación de una clave principal en una tabla existente En el ejemplo siguiente se crea una clave principal en la columna TransactionID de la base de datos de AdventureWorks.
Codigo:
ALTER TABLE Production.TransactionHistoryArchive
ADD CONSTRAINT PK_TransactionHistoryArchive_TransactionID PRIMARY KEY CLUSTERED (TransactionID);En el ejemplo siguiente se crea una tabla y se define una clave principal en la columna TransactionID de la base de datos de AdventureWorks.
CREATE TABLE Production.TransactionHistoryArchive1
(
TransactionID int IDENTITY (1,1) NOT NULL
, CONSTRAINT PK_TransactionHistoryArchive1_TransactionID PRIMARY KEY CLUSTERED (TransactionID)
);La normalización en las bases de datos relacionales es uno de esos temas que, por un lado es sumamente importante y por el otro suena algo esotérico. Vamos a tratar de entender las formas normales (FN) de una manera simple para que puedas aplicarlas en tus proyectos profesionales.
- Todos los atributos son atómicos. Un atributo es atómico si los elementos del dominio son simples e indivisibles.
- No debe existir variación en el número de columnas.
- Los campos no clave deben identificarse por la clave (dependencia funcional).
- Debe existir una independencia del orden tanto de las filas como de las columnas; es decir, si los datos cambian de orden no deben cambiar sus significados.
Se traduce básicamente a que si tenemos campos compuestos como por ejemplo “nombre_completo” que en realidad contiene varios datos distintos, en este caso podría ser “nombre”, “apellido_paterno”, “apellido_materno”, etc.
También debemos asegurarnos que las columnas son las mismas para todos los registros, que no haya registros con columnas de más o de menos.
Todos los campos que no se consideran clave deben depender de manera única por el o los campos que si son clave.
Los campos deben ser tales que si reordenamos los registros o reordenamos las columnas, cada dato no pierda el significado.
- Está en 1FN
- Sí los atributos que no forman parte de ninguna clave dependen de forma completa de la clave principal. Es decir, que no existen dependencias parciales.
- Todos los atributos que no son clave principal deben depender únicamente de la clave principal.
Lo anterior quiere decir que sí tenemos datos que pertenecen a diversas entidades, cada entidad debe tener un campo clave separado. Por ejemplo:

En la tabla anterior tenemos por lo menos dos entidades que debemos separar para que cada uno dependa de manera única de su campo llave o ID. En este caso las entidades son alumnos por un lado y materias por el otro. En el ejemplo anterior, quedaría de la siguiente manera:

Esta FN se traduce en que aquellos datos que no pertenecen a la entidad deben tener una independencia de las demás y debe tener un campo clave propio. Continuando con el ejemplo anterior, al aplicar la 3FN separamos la tabla alumnos ya que contiene datos de los cursos en ella quedando de la siguiente manera.


Esta FN nos trata de atomizar los datos multivaluados de manera que no tengamos datos repetidos entre rows.
- Se encuentra en 3FN
- Los campos multivaluados se identifican por una clave única
Esta FN trata de eliminar registros duplicados en una entidad, es decir que cada registro tenga un contenido único y de necesitar repetir la data en los resultados se realiza a través de claves foráneas.
Aplicado al ejemplo anterior la tabla materia se independiza y se relaciona con el alumno a través de una tabla transitiva o pivote, de tal manera que si cambiamos el nombre de la materia solamente hay que cambiarla una vez y se propagara a cualquier referencia que haya de ella.


De esta manera, aunque parezca que la información se multiplicó, en realidad la descompusimos o normalizamos de manera que a un sistema le sea fácil de reconocer y mantener la consistencia de los datos.
Algunos autores precisan una 5FN que hace referencia a que después de realizar esta normalización a través de uniones (JOIN) permita regresar a la data original de la cual partió.

CREATE TABLE [dbo].[Paciente](
[idPaciente] [int] Primary key Identity,
[nombre] [varchar](50) NULL,
[apellido] [varchar](50) NULL,
[fNacimiento] [date] NULL,
[domicilio] [varchar](50) NULL,
[idPais] [char](3) NULL,
[telefono] [varchar](20) NULL,
[email] [varchar](30) NULL,
[observacion] [varchar](1000) NULL,
[fechaAlta] [datetime] NULL
)
GO [idHistoria] [int]
[fechaHistoria] [datetime]
[observacion] [varchar](2000)
[fechaAlta] [datetime]
CREATE TABLE [dbo].[Historia](
[idHistoria] [int] NOT NULL,
[fechaHistoria] [datetime] NOT NULL,
[observacion] [varchar](2000) NULL,
[fechaAlta] [datetime] NULL,
CONSTRAINT [PK_PacienteHistoria_1] PRIMARY KEY CLUSTERED
(
[idHistoria] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO [idHistoria] [int]
[idPaciente] [int]
[idMedico] [int]
CREATE TABLE [dbo].[HistoriaPaciente](
[idHistoria] [int] NOT NULL,
[idPaciente] [int] NOT NULL,
[idMedico] [int] NOT NULL,
CONSTRAINT [PK_HistoriaPaciente] PRIMARY KEY CLUSTERED
(
[idHistoria] ASC,
[idPaciente] ASC,
[idMedico] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO [idTurno] [int]
[idPaciente] [int]
[idMedico] [smallint]
CONSTRAINT [PK_PacienteTurno] PRIMARY KEY CLUSTERED
CREATE TABLE [dbo].[TurnoPaciente](
[idTurno] [int] NOT NULL,
[idPaciente] [int] NOT NULL,
[idMedico] [smallint] NOT NULL,
CONSTRAINT [PK_PacienteTurno] PRIMARY KEY CLUSTERED
(
[idTurno] ASC,
[idPaciente] ASC,
[idMedico] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO [idTurno] [int]
[fechaTurno] [datetime]
[fechaAlta] [datetime]
[estado] [nchar](10)
CONSTRAINT [PK_Turno] PRIMARY KEY CLUSTERED
CREATE TABLE [dbo].[Turno](
[idTurno] [int] NOT NULL,
[fechaTurno] [datetime] NULL,
[fechaAlta] [datetime] NULL,
[estado] [nchar](10) NULL,
CONSTRAINT [PK_Turno] PRIMARY KEY CLUSTERED
(
[idTurno] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO [idPais] [char](3)
[pais] [varchar](30)
CONSTRAINT [PK_Pais] PRIMARY KEY CLUSTERED
CREATE TABLE [dbo].[Pais](
[idPais] [char](3) NOT NULL,
[pais] [varchar](30) NULL,
CONSTRAINT [PK_Pais] PRIMARY KEY CLUSTERED
(
[idPais] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO [idEspecialidad] [int] IDENTITY(1,1)
[especialidad] [varchar](30)
CONSTRAINT [PK_Especialidad] PRIMARY KEY CLUSTERED
CREATE TABLE [dbo].[Especialidad](
[idEspecialidad] [int] IDENTITY(1,1) NOT NULL,
[especialidad] [varchar](30) NULL,
CONSTRAINT [PK_Especialidad] PRIMARY KEY CLUSTERED
(
[idEspecialidad] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO [idMedico] [dbo].[medico] IDENTITY(1,1)
[nombre] [varchar](50)
[apellido] [varchar](50)
CONSTRAINT [PK_Medico] PRIMARY KEY CLUSTERED
CREATE TABLE [dbo].[Medico](
[idMedico] [dbo].[medico] IDENTITY(1,1) NOT NULL,
[nombre] [varchar](50) NULL,
[apellido] [varchar](50) NULL,
CONSTRAINT [PK_Medico] PRIMARY KEY CLUSTERED
(
[idMedico] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
[idMedico] [int]
[idEspecialidad] [int]
[descripcion] [varchar](50)
CONSTRAINT [PK_MedicoEspecialidad] PRIMARY KEY CLUSTERED
CREATE TABLE [dbo].[MedicoEspecialidad](
[idMedico] [int] NOT NULL,
[idEspecialidad] [int] NOT NULL,
[descripcion] [varchar](50) NULL,
CONSTRAINT [PK_MedicoEspecialidad] PRIMARY KEY CLUSTERED
(
[idMedico] ASC,
[idEspecialidad] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GOLa instrucción SELECT en SQL se usa para recuperar datos de una base de datos relacional. Sintaxis SQL: SELECT * FROM "table_name"; "table_name" es el nombre de la tabla donde se almacenan los datos, y "column_name" es el nombre de la columna que contiene los datos que se recuperarán.
es una sentencia SQL que añade datos a una tabla. La sentencia INSERT tiene el formato siguiente: INSERT INTO nombtabla VALUES ( valor1, valor2 , ...) En esta sintaxis, nombtabla es el nombre de la tabla o vista en la que se desea insertar datos y valor1, valor2 (etc.), son los valores que va a insertar.
La declaración UPDATE puede utilizarse para actualizar una sola columna, un conjunto más amplio de registros (mediante el uso de condiciones), y/o toda la tabla en una base de datos. La(s) condición(es) puede(n) ser un booleano, una verificación de cadena de texto o una secuencia matemática que se resuelve en un booleano (mayor que, menos que, etc.).
El comando DELETE permitirá eliminar una o varias filas de una tabla. La sintaxis del comando DELETE es simple si no limitamos las filas. Si no se indica la cláusula WHERE, se borrarán todas las filas de la tabla.
Ejemplos: Select
SELET * FROM [dbo].[Paciente] En este caso, estoy extrayendo todos los campos de la tabla.
Ejemmplo
SELET
[idPaciente]
[nombre]
[apellido]
[fNacimiento]
[domicilio]
[idPais]
[telefono]
[email]
[observacion]
[fechaAlta]
FROM [dbo].[Paciente] En este caso, también estoy seleccionando todos los campos de la tabla; pero en este caso estoy especificando sql uno por uno los campos que necesito
Esto
La cláusula WHERE de SQL se utiliza para especificar una condición al recuperar un conjunto de datos de una tabla o de un conjunto de tablas. Si se cumple la condición dada, la consulta devuelve los valores relacionados con la condición que se especifique en la cláusula WHERE. Debe usar la cláusula WHERE para filtrar los registros y obtener solo los registros necesarios.
La cláusula WHERE no solo se usa en la instrucción SELECT, sino que también se usa en la instrucción UPDATE y DELETE., que examinaríamos en las siguientes Clases.
La cláusula WHERE se utiliza para obtener datos filtrados de un conjunto de resultados.
- Se utiliza para obtener datos de acuerdo con un criterio particular.
- La palabra clave WHERE también se puede utilizar para filtrar datos al hacer coincidir patrones.
- La cláusula WHERE se puede utilizar con los siguientes tipos de sentencias de SQL:
- SELECT
- UPDATE
- DELETE
Sintaxis La sintaxis básica de la cláusula WHERE con la instrucción SELECT es la que se muestra a continuación.
SELECT column1, column2, columnN FROM table_name WHERE [condición] UPDATE "table_name" SET "column_1" = nuevo valor WHERE "condición" DELETE FROM "table_name" WHERE "condición";"Condición" puede incluir una única cláusula de comparación (llamada condición simple) o múltiples cláusulas de comparación combinadas utilizando los operadores AND u OR (condición compuesta).
Además, la cláusula WHERE puede especificar una condición utilizando la comparación o los operadores lógicos como >, <, =, LIKE, NOT, etc. Los siguientes ejemplos te aclararan estos conceptos.
Ejemplos
select EmployeeID,
LastName,
FirstName,
Title,
Address
from Employees
where Title= 'Sales Representative'Es importante tener en cuenta que todas las cadenas deben estar entre comillas simples (''). Considerando que, los valores numéricos deben darse sin ninguna cita.
Para ver todos los datos de los Representantes de Ventas y de los administradores de ventas usamos la siguiente consulta SQL.
select EmployeeID,
LastName,
FirstName,
Title,
Address
from Employees
where Title= 'Sales Representative' or Title= 'Sales Manager'Como se mencionó anteriormente, la cláusula WHERE se puede usar con las instrucciones UPDATE y DELETE además de la instrucción SELECT. Los ejemplos de cómo usar la cláusula WHERE con estos dos comandos los veremos en los artículos de UPDATE y DELETE.
Ejercicios
1 SELECT * FROM Employees WHERE FirstName = 'Nancy';
2 SELECT * WHERE FirstName = 'Nancy' FROM Employees;
3 SELECT FirstName= 'CARLOS' FROM Employees;
4 SELECT FirstName FROM Employees WHERE FirstName = 'Nancy';
SELECT EmployeeID,
LastName,
FirstName,
Title,
Address
FROM Employees
WHERE Address LIKE '4%';Ejemplo#1
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1, value2, ...);Ejemplo#2
SELECT EmployeeID,
LastName,
FirstName,
Title,
Address
FROM Employees
WHERE EmployeeID in (3, 4, 5, 8);Ejemplo#2
SELECT EmployeeID,
LastName,
FirstName,
Title,
Address
FROM Employees
WHERE EmployeeID not in (3, 4, 5, 8);El operador BETWEEN selecciona valores dentro de un rango dado. Los valores pueden ser números, texto o fechas.
Ejemplo
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;Ejemplo#2
SELECT * FROM Products
WHERE Price BETWEEN 10 AND 20;3.- (Verdadero o Falso) La condición utilizada en la cláusula WHERE debe incluir una columna que sea parte de la cláusula SELECT.________
La sentencia del “SQL JOIN” es uno de los componentes principales de la sentencia Select, que se utiliza para extraer datos del “SQL Server”.
La palabra “Select” inicia la sentencia. A menudo es seguido por un asterisco (*) “AKA splat” como algunos lo llaman DBA.
Nota: para expandir automáticamente los comodines a las columnas explícitas, consulte How to prevent performance problems and errors due to wildcards in SELECT statements
Esto solo significa retornar a todas las columnas. Si tenemos varias tablas, un Select asterisco capturará todas las columnas de todas las tablas, por ejemplo, unir varias tablas usando la sentencia de “SQL JOIN”, que es el tema principal de este artículo.
Empezaremos con la definición. Join es el proceso de tomar datos de varias tablas y colocarlos en una vista generada. Por tanto, una instrucción de “SQL JOIN” en un comando Select combina las columnas entre una o más tablas en una base de datos relacional y retorna a un conjunto de datos.
“El FROM” también es parte esencial de la instrucción Select y es aquí donde se especifica de qué tabla estamos extrayendo los datos. La parte de join es donde queremos unir datos de varias tablas y tenemos tres tipos diferentes de combinaciones:
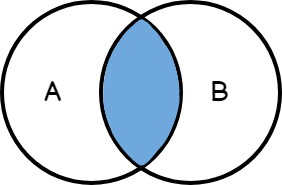
Inner join – esta es la opción predeterminada. Si no se especifica el tipo de unión, se establecerá de manera predeterminada como la unión interna. Esto implica que si estamos uniendo dos tablas en una columna común, solo retornaran los datos que coincidan en ambas tablas
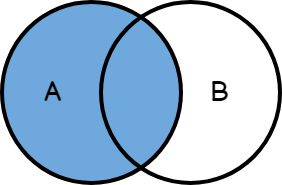
Left join – este tipo de unión significa que solo retornan todos los datos de la tabla de la mano izquierda, solo si los datos coinciden con la tabla de la mano derecha
Right join – este tipo de unión es el caso opuesto al anterior. Implica que solo retornaran los datos de la tabla de la mano derecha, solo si los datos coinciden con la tabla de la mano izquierda
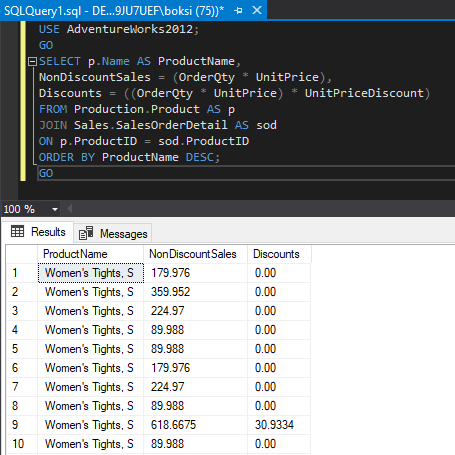
Vayamos hasta SQL Server Management Studio (SSMS) y verifiquemos cómo se puede trabajar con la instrucción de “SQL JOIN” utilizando ejemplos del mundo real. A continuación, mostramos un ejemplo de cómo unir tablas en una columna común. En nuestra base de datos de ejemplo AdventureWorks2012, tenemos la tabla “Producto” que tiene una columna “ProductID” y en la tabla “SalesOrderDetail”, también se tiene una columna “ProductID”. Entonces, si deseamos averiguar las ventas totales y los descuentos para cada producto y sacar el nombre, debemos unir estos dos en esta columna común:
USE AdventureWorks2012;
GO
SELECT
p.Name AS ProductName,
NonDiscountSales = (OrderQty * UnitPrice),
Discounts = ((OrderQty * UnitPrice) * UnitPriceDiscount)
FROM Production.Product AS p
JOIN Sales.SalesOrderDetail AS sod
ON p.ProductID = sod.ProductID
ORDER BY ProductName DESC;
GOome en cuenta que, si solo se especifica JOIN por sí mismo, sin una palabra clave interna en la sentencia de “SQL JOIN”, seguirá siendo un INNER JOIN. Por supuesto, puede poner la palabra clave “inner” para mayor claridad, pero si no hay una combinación de etiqueta izquierda / derecha, se establecerá por defecto una combinación interna:
Ahora, démosle un vistazo al LEFT OURTER JOIN que nos ofrece todo desde la tabla de la izquierda y solo los registros que coinciden en la tabla de la derecha. En nuestro ejemplo, la siguiente consulta nos dará algunas personas que no han realizado ninguna compra:
SELECT *
FROM Person.Person p
LEFT JOIN Sales.PersonCreditCard pcc ON p.BusinessEntityID = pcc.BusinessEntityID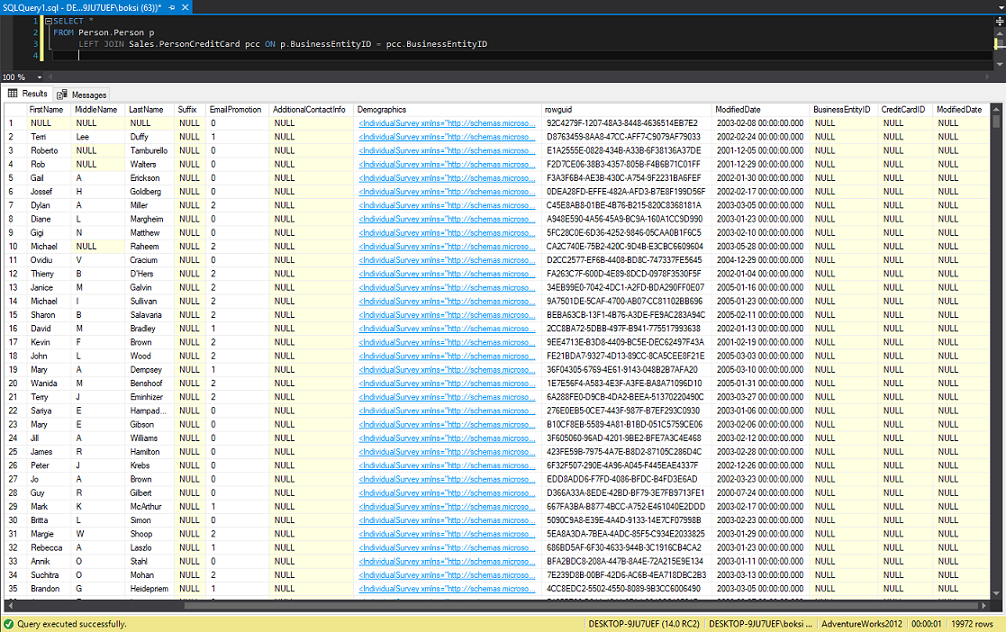
El conjunto de resultados indica que retornaron 19972 registros, y se tiene un grupo de valores nulos en la columna “BusinessEntityID”. Las filas que tienen nulos son personas que no realizaron ninguna compra.
Se puede extender de la consulta anterior y agregar otra sentencia de “SQL JOIN” para poder incluir a las personas con la información de la tarjeta de crédito. Tome en cuenta que se acaba de especificar la palabra clave Join, que es una combinación interna de forma predeterminada y eliminará todos los valores nulos porque esas personas no tienen información de la tarjeta de crédito:
Ahora, la cláusula RIGHT JOIN es exactamente lo opuesto a LEFT JOIN. Básicamente hacen lo mismo. La izquierda es derecha y la derecha es izquierda y se puede obtener el mismo efecto simplemente cambiando las tablas. Los RIGHT JOIN no están en omitidas, simplemente no son tan comunes. Por razones de consistencia, es una práctica común utilizar LEFT JOIN en lugar de uniones derechas.
- 1 para obtener en Northwind los clientes que tengan algún pedido, bastaría con escribir
SELECT OrderID, C.CustomerID, CompanyName, OrderDate
FROM Customers C INNER JOIN Orders O ON C.CustomerID = O.CustomerID - 2 todos los clientes y sus pedidos, incluso aunque no tengan pedido alguno.
SELECT OrderID, C.CustomerID, CompanyName, OrderDate
FROM Customers C LEFT JOIN Orders O ON C.CustomerID = O.CustomerID - 3 odos los pedidos aunque no tengan cliente asociado
SELECT OrderID, C.CustomerID, CompanyName, OrderDateFROM Customers C RIGHT JOIN Orders O ON C.CustomerID = O.CustomerID- los clientes y sus pedidos, los clientes sin pedido (hay 2) y los pedidos sin cliente (que en este caso son 0).
SELECT OrderID, C.CustomerID, CompanyName, OrderDate
FROM Customers C FULL JOIN Orders O ON C.CustomerID = O.CustomerIDCalcula la media aritmética de un conjunto de valores contenidos en un campo especificado de una consulta. Su sintaxis es la siguiente
Avg(expr)
En donde expr representa el campo que contiene los datos numéricos para los que se desea calcular la media o una expresión que realiza un cálculo utilizando los datos de dicho campo. La media calculada por Avg es la media aritmética (la suma de los valores dividido por el número de valores). La función Avg no incluye ningún campo Null en el cálculo.
SELECT Avg(Gastos) AS Promedio FROM Pedidos WHERE Gastos > 100;Count(expr)
En donde expr contiene el nombre del campo que desea contar. Los operandos de expr pueden incluir el nombre de un campo de una tabla, una constante o una función (la cual puede ser intrínseca o definida por el usuario pero no otras de las funciones agregadas de SQL). Puede contar cualquier tipo de datos incluso texto.
Aunque expr puede realizar un cálculo sobre un campo, Count simplemente cuenta el número de registros sin tener en cuenta qué valores se almacenan en los registros. La función Count no cuenta los registros que tienen campos null a menos que expr sea el carácter comodín asterisco (). Si utiliza un asterisco, Count calcula el número total de registros, incluyendo aquellos que contienen campos null. Count() es considerablemente más rápida que Count(Campo). No se debe poner el asterisco entre dobles comillas ('*').
SELECT Count(*) AS Total FROM Pedidos;Si expr identifica a múltiples campos, la función Count cuenta un registro sólo si al menos uno de los campos no es Null. Si todos los campos especificados son Null, no se cuenta el registro. Hay que separar los nombres de los campos con ampersand (&).
SELECT Count(FechaEnvío & Transporte) AS Total FROM Pedidos;Devuelven el mínimo o el máximo de un conjunto de valores contenidos en un campo especifico de una consulta. Su sintaxis es:
Min(expr)
Max(expr)
En donde expr es el campo sobre el que se desea realizar el cálculo. Expr pueden incluir el nombre de un campo de una tabla, una constante o una función (la cual puede ser intrínseca o definida por el usuario pero no otras de las funciones agregadas de SQL).
SELECT Min(Gastos) AS ElMin FROM Pedidos WHERE Pais = 'España'; SELECT Max(Gastos) AS ElMax FROM Pedidos WHERE Pais = 'España';¿Cómo funcionan SQL min() y max()? ¿Cómo puedo combinar agregados? ¿Pueden funcionar con fechas? para realizar multiples analisis en SQL debemos usa la función agregada MIN() o MAX(). A menudo estas funcion empleadas por profesionales pueden ser útiles para resolver diversos problemas de analisis.
MIN() devuelve el valor minimo de la columna seleccionada. La función MAX devuelve el valor máximo para las columnas seleccionadas.
Select max(Nombre_columna) from Nombre_tablaGeneralmente la forma más fácil de usar SQL MAX es devolver sólo un campo para calcular los valores MAX.
También puede necesitar una lista de salarios para cada empleado. Este ejemplo de función SQL MAX se da para sacar el salario mas alto utilizando MAX(salario)
select
max( o.Quantity)
from [Order Details] oEl método más utilizado es el uso de una función Max en conjunción con la cláusula Group BY encontrar el valor más alto para cada grupo. La función MAX se utiliza para determinar el salario máximo para un empleado de la siguiente manera:
Select departamento, max(salario) from empleados
El Siguiente codigo es un ejemplo del uso de max con un group by , el mismo retorna el valor mayor de campo Quantity para cada orden de la tabla [OrderDetail]
select
orderid
,max( o.Quantity)
from [Order Details] o
group by OrderIDEsta funcion retorna el valor minimo que tiene un campo en una tabla , esto podria ser la forma mas simple de utilizar este comando
Generalmente la forma más fácil de usar SQL MAX es devolver sólo un campo para calcular los valores MAX. También puede necesitar una lista de salarios para cada empleado. Este ejemplo de función SQLMAX se da en los campos MAX(salario) con salarios altos. En efecto, los nombres de campo se muestran como campos en los resultados devueltos.
| nombre | apellido | salario | departamento | fecha |
|---|---|---|---|---|
| jose | marte | $2,500 | IT | 1/1/2005 |
| Mario | Perez | $500 | contabilidad | 12/12/2016 |
| jose | mateo | $1,500 | IT | 01/03/2022 |
Select Min (Salario) from empleados
El resultado de esta consulta seria $500, debido a que la funcion min buscara el valor minimo dentro de esta columna
El método más utilizado es el uso de una función min en conjunción con la cláusula Group BY para encontrar el valor más bajo para cada grupo. La función Minse utiliza para determinar el salario min para un departamento de la siguiente manera:
Select departamento, Min (salario) from empleados
Select
Departamento
, min(Salario)
from empleadosNos Retornaria el siguiente resultado
| Departamento | Salario |
|---|---|
| IT | $1,500 |
| contabilidad | $500 |
funcion sql max y sql min son utilizandas en conjunto con having para filtrar los registros agrupados.
Esto seria una forma de filtrar los datos pero en vez de hacerlo con un Where lo hacemos con un Having desde el group by.
select
orderid
,max( o.Quantity) ValorMaximo
from [Order Details] o
group by OrderID
having max(o.Quantity) > 50
Esto presentaria un resultado similar a esto.
| orderid | ValorMaximo |
|---|---|
| 10258 | 65 |
| 10263 | 60 |
| 10267 | 70 |
| 10269 | 60 |
| 10273 | 60 |
| 10286 | 100 |
| 10297 | 60 |
having max(o.Quantity) > 50A codigo lo que hacemos es filtar a traves de group by los elementos del campo Quantity que son mayores a 50
Devuelve la suma del conjunto de valores contenido en un campo especifico de una consulta. Su sintaxis es:
Sum(expr)
En donde expr respresenta el nombre del campo que contiene los datos que desean sumarse o una expresión que realiza un cálculo utilizando los datos de dichos campos. Los operandos de expr pueden incluir el nombre de un campo de una tabla, una constante o una función (la cual puede ser intrínseca o definida por el usuario pero no otras de las funciones agregadas de SQL).
SELECT Sum(PrecioUnidad * Cantidad) AS Total FROM DetallePedido;Devuelve estimaciones de la desviación estándar para la población (el total de los registros de la tabla) o una muestra de la población representada (muestra aleatoria) . Su sintaxis es:
StDev(expr)
StDevP(expr)
En donde expr representa el nombre del campo que contiene los datos que desean evaluarse o una expresión que realiza un cálculo utilizando los datos de dichos campos. Los operandos de expr pueden incluir el nombre de un campo de una tabla, una constante o una función (la cual puede ser intrínseca o definida por el usuario pero no otras de las funciones agregadas de SQL)
StDevP evalúa una población, y StDev evalúa una muestra de la población. Si la consulta contiene menos de dos registros (o ningún registro para StDevP), estas funciones devuelven un valor Null (el cual indica que la desviación estándar no puede calcularse).
SELECT StDev(Gastos) AS Desviacion FROM Pedidos WHERE Pais = 'España';
SELECT StDevP(Gastos) AS Desviacion FROM Pedidos WHERE Pais = 'España';Devuelve una estimación de la varianza de una población (sobre el total de los registros) o una muestra de la población (muestra aleatoria de registros) sobre los valores de un campo. Su sintaxis es:
Var(expr)
VarP(expr)
VarP evalúa una población, y Var evalúa una muestra de la población. Expr el nombre del campo que contiene los datos que desean evaluarse o una expresión que realiza un cálculo utilizando los datos de dichos campos. Los operandos de expr pueden incluir el nombre de un campo de una tabla, una constante o una función (la cual puede ser intrínseca o definida por el usuario pero no otras de las funciones agregadas de SQL)
Si la consulta contiene menos de dos registros, Var y VarP devuelven Null (esto indica que la varianza no puede calcularse). Puede utilizar Var y VarP en una expresión de consulta o en una Instrucción SQL.
SELECT Var(Gastos) AS Varianza FROM Pedidos WHERE Pais = 'España';
SELECT VarP(Gastos) AS Varianza FROM Pedidos WHERE Pais = 'España';Select count(*) Total from Employeesselect Avg(UnitPrice) as AVGPrice from [Order Details]Select Min(UnitPrice) as Pmenor from [Order Details]Select Max(UnitPrice) as Pmenor from [Order Details]select
min(o.OrderDate) fechaMinima
,max(o.orderDate) fechaMaxima
from Orders Oselect
orderid
,max( o.Quantity)
from [Order Details] o
group by OrderIDselect
orderid
,max( o.Quantity) ValorMaximo
from [Order Details] o
group by OrderID
having max(o.Quantity) > 50select
stdev(o.Quantity) desviacion
from [Order Details] oselect
stdevp(o.Quantity) desviacion
from [Order Details] oselect
Var(o.Quantity) desviacion
from [Order Details] oselect
Varp(o.Quantity) desviacion
from [Order Details] oEn este tema se describe cómo crear un procedimiento almacenado de Transact-SQL mediante SQL Server Management Studio y mediante la instrucción CREATE PROCEDURE de Transact-SQL.
Requiere el permiso CREATE PROCEDURE en la base de datos y el permiso ALTER en el esquema en el que se va a crear el procedimiento.
-
En el Explorador de objetos, conéctese a una instancia del Motor de base de datos.
-
En el menú Archivo , haga clic en Nueva consulta.
-
Copie y pegue el siguiente ejemplo en la ventana de consulta y haga clic en Ejecutar. En este ejemplo se crea el mismo procedimiento almacenado que antes con otro nombre diferente.
USE AdventureWorks2012;
GO
CREATE PROCEDURE HumanResources.uspGetEmployeesTest2
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
GODeclare @CustomerID varchar(5) = 'ALFKI'
--select * from Customers
SELECT ProductName, Total=SUM(Quantity)
FROM Products P, [Order Details] OD, Orders O, Customers C
WHERE C.CustomerID = @CustomerID
AND C.CustomerID = O.CustomerID AND O.OrderID = OD.OrderID AND OD.ProductID = P.ProductID
GROUP BY ProductNameprocederemos crear un store procedure con el. Para mostrar este tipo de cosas me gusta mostrar ejemplos.
Create PROCEDURE [dbo].[CustOrderHist2] @CustomerID nchar(5)
AS
SELECT ProductName, Total=SUM(Quantity)
FROM Products P, [Order Details] OD, Orders O, Customers C
WHERE C.CustomerID = @CustomerID
AND C.CustomerID = O.CustomerID AND O.OrderID = OD.OrderID AND OD.ProductID = P.ProductID
GROUP BY ProductName
Como puedes ver la Creacion de procedimiento se hace con las palabrar reservadas Create Store Procedure seguido del nombre del procedure.
Para ejecutar el procedimiento, copie y pegue el ejemplo siguiente en una nueva ventana de consulta y haga clic en Ejecutar. Observe que se muestran diferentes métodos para especificar los valores de parámetro.
EXECUTE HumanResources.uspGetEmployeesTest2 N'Ackerman', N'Pilar';
-- Or
EXEC HumanResources.uspGetEmployeesTest2 @LastName = N'Ackerman', @FirstName = N'Pilar';
GO
-- Or
EXECUTE HumanResources.uspGetEmployeesTest2 @FirstName = N'Pilar', @LastName = N'Ackerman';
GOCompanyName
Country
Phone
OrderDate
ProductName
UnitPrice
Quantity
[dbo].[Customers]
[dbo].[Orders]
[dbo].[Order Details]
[dbo].[Products]
select
C.CompanyName
,C.Country
,C.Phone
,o.OrderDate
,pd.ProductName
,od.UnitPrice
,od.Quantity
,od.UnitPrice * Quantity total
from [dbo].[Customers] C
join [dbo].[Orders] o on o.CustomerID = C.CustomerID
join [dbo].[Order Details] od on od.OrderID = o.OrderID
join [dbo].[Products] pd on pd.ProductID = od.ProductID
SELECT LastName,(CAST(DATEDIFF(MONTH,BirthDate,GETDATE())/12 AS INT)) AS Edad,SUM(Quantity)as Pedidos
FROM Employees e join Orders o on e.EmployeeID=o.EmployeeID
join [Order Details] d on o.OrderID=d.OrderID
where YEAR(OrderDate) = (SELECT distinct MAX(YEAR(Orderdate)) from Orders)
group by LastName,BirthDate
order by LastName asc
goselect *
from Customers
order by ContactName
select *
from Orders
order by OrderDate descSeleccionar todos los campos de la tabla detalle de la orden, ordenada porcantidad pedida, ascendentemente.
select *
from [Order Details] od
order by od.Quantity ascObtener todos los productos, cuyo nombre comienzan con la letra P ytienen un precio unitario comprendido entre 10 y 120.(UnitPricebetween10and20)
select *
from Products p
where p.ProductName like 'P%'
and p.UnitPrice between 10 and 120
Select *
from Customers Cu
where Cu.Country in ('USA', 'UK')
select *
from Products P
where p.CategoryID in (1, 3, 4,7)
and p.Discontinued = 1select OrderID
from Orders od
where od.EmployeeID in (2, 5, 7)
select *
from Customers cu
where fax is not null
Todos ls que Tienen datos en el campo fax
select *
from Customers cu
where cu.fax is nulltodos los que tengan el campo fax nulo.
select *
from Employees ep
where ReportsTo is not null
Seleccionar todos los campos del cliente, cuya compañía empiece con la letra de A hasta la D y pertenezcan al país de USA, ordenarlos por la dirección.
Select *
from Customers cu
where cu.CompanyName like 'A%'
or cu.CompanyName like 'B%'
or cu.CompanyName like 'C%'
or cu.CompanyName like 'D%'