
A comprehensive Clojure client for the entire Amazon AWS api.

Leiningen coordinates:
[amazonica "0.3.161"]For Maven users:
add the following repository definition to your pom.xml:
<repository>
<id>clojars.org</id>
<url>http://clojars.org/repo</url>
</repository>and the following dependency:
<dependency>
<groupId>amazonica</groupId>
<artifactId>amazonica</artifactId>
<version>0.3.161</version>
</dependency>- Amplify
- Api Gateway
- AppConfig
- Application Insights
- App Mesh
- Augmented AI
- Autoscaling
- Austocaling Plans
- Backup
- Batch
- Budgets
- Certificate Manager
- CloudDirectory
- CloudFormation
- CloudFront
- CloudSearch
- CloudSearchV2
- CloudSearchDomain
- CloudWatch
- CloudWatchEvents
- CodeBuild
- CodeCommit
- CodeDeploy
- CodePipeline
- CodeStar
- Cognito
- CognitoIdentityProviders
- Comprehend
- Compute Optimizer
- Config
- Connect
- CostAndUsageReport
- CostExplorer
- DatabaseMigrationService
- DataPipeline
- Data Exchange
- Data Sync
- Dax
- Detective
- DeviceFarm
- DirectConnect
- Directory
- DLM
- DocDB
- DynamoDBV2
- EC2
- EC2InstanceConnect
- ECR
- ECS
- ElastiCache
- ElasticBeanstalk
- ElasticFileSystem
- ElasticLoadBalancing
- ElasticMapReduce
- Elasticsearch
- ElasticTranscoder
- Event Bridge
- Forecast
- Fraud Detector
- GameLift
- Glacier
- Global Accelerator
- Glue
- GreenGrass
- Groundstation
- GuardDuty
- IdentityManagement
- Image Builder
- ImportExport
- IoT
- Kafka
- Kendra
- Kinesis
- Kinesis Analytics
- KinesisFirehose
- KMS
- Lake Formation
- Lambda
- Lex
- Lightsail
- Logs
- MachineLearning
- Macie
- Managed Blockcahin
- MechanicalTurk
- MediaConvert
- MediaLive
- MediaPackage
- MediaStore
- MigrationHub
- Mobile
- MQ
- MSK (Managed Kafka)
- OpsWorks
- Personalize
- Pinpoint
- Pricing
- Polly
- QLDB
- Quicksight
- RDS
- Redshift
- Rekognition
- Route53
- Route53Domains
- S3
- Sagemaker
- Secrets Manager
- Security Hub
- Security Token
- ServerMigration
- ServiceCatalog
- Service Discovery
- Shield
- SimpleDB
- SimpleEmail
- SimpleSystemsManager
- SimpleWorkflow
- Snowball
- SNS
- SQS
- StepFunctions
- StorageGateway
- Support
- Textract
- Timestream
- Transcribe
- Transfer
- Translate
- WAF
- Workspaces
- XRay
(ns com.example
(:use [amazonica.aws.ec2]))
(describe-instances)
(create-snapshot :volume-id "vol-8a4857fa"
:description "my_new_snapshot")Amazonica reflectively delegates to the Java client library, as such it supports the complete set of remote service calls implemented by each of the service-specific AWS client classes (e.g. AmazonEC2Client, AmazonS3Client, etc.), the documentation for which can be found in the AWS Javadocs. cljdoc function references are also available.
Reflection is used to create idiomatically named Clojure Vars in the library namespaces corresponding to the AWS service. camelCase Java methods become lower-case, hyphenated Clojure functions. So for example, if you want to create a snapshot of a running EC2 instance, you'd simply
(create-snapshot :volume-id "vol-8a4857fa"
:description "my_new_snapshot")which delegates to the createSnapshot() method of AmazonEC2Client. If the Java method on the Amazon*Client takes a parameter, such as CreateSnapshotRequest in this case, the bean properties exposed via mutators of the form set* can be supplied as key-value pairs passed as arguments to the Clojure function.
All of the AWS Java apis (except S3) follow this pattern, either having a single implementation method which takes an AWS Java bean as its only argument, or being overloaded and having a no-arg implementation. The corresponding Clojure function will either require key-value pairs as arguments, or be variadic and allow a no-arg invocation.
For example, AmazonEC2Client's describeImages() method is overloaded, and can be invoked either with no args, or with a DescribeImagesRequest. So the Clojure invocation would look like
(describe-images)or
(describe-images :owners ["self"]
:image-ids ["ami-f00f9699" "ami-e0d30c89"])java.util.Collections are converted to the corresponding Clojure collection type. java.util.Maps are converted to clojure.lang.IPersistentMaps, java.util.Lists are converted to clojure.lang.IPersistentVectors, etc.
java.util.Dates are automatically converted to Joda Time DateTime instances.
Amazon AWS object types are returned as Clojure maps, with conversion taking place recursively, so, "Clojure data all the way down."
For example, a call to
(describe-instances)invokes a Java method on AmazonEC2Client which returns a com.amazonaws.services.ec2.model.DescribeInstancesResult. However, this is recursively converted to Clojure data, yielding a map of Reservations, like so:
{:owner-id "676820690883",
:group-names ["cx"],
:groups [{:group-name "cx", :group-id "sg-38f45150"}],
:instances
[{:instance-type "m1.large",
:kernel-id "aki-825ea7eb",
:hypervisor "xen",
:state {:name "running", :code 16},
:ebs-optimized false,
:public-dns-name "ec2-154-73-176-213.compute-1.amazonaws.com",
:root-device-name "/dev/sda1",
:virtualization-type "paravirtual",
:root-device-type "ebs",
:block-device-mappings
[{:device-name "/dev/sda1",
:ebs
{:status "attached",
:volume-id "vol-b0e519c3",
:attach-time #<DateTime 2013-03-21T22:00:56.000-07:00>,
:delete-on-termination true}}],
:network-interfaces [],
:public-ip-address "164.73.176.213",
:placement
{:availability-zone "us-east-1a",
:group-name "",
:tenancy "default"},
:private-ip-address "10.116.187.19",
:security-groups [{:group-name "cx", :group-id "sg-38f45150"}],
:state-transition-reason "",
:private-dns-name "ip-10-116-187-19.ec2.internal",
:instance-id "i-cefbe7a2",
:key-name "cxci",
:architecture "x86_64",
:client-token "",
:image-id "ami-baba68d3",
:ami-launch-index 0,
:monitoring {:state "disabled"},
:product-codes [],
:launch-time #<DateTime 2013-03-21T22:00:52.000-07:00>,
:tags [{:value "CXCI_nightly", :key "Name"}]}],
:reservation-id "r-8a23d6f7"}If you look at the Reservation Javadoc you'll see that getGroups() returns a java.util.List of GroupIdentifiers, which is converted to a vector of maps containing keys :group-name and :group-id, under the :groups key. Ditto for :block-device-mappings and :tags, and so and so on...
Similar in concept to JSON unwrapping in Jackson, Amazonica supports root unwrapping of the returned data. So calling
; dynamodb
(list-tables)by default would return
{:table-names ["TableOne" "TableTwo" "TableThree"]}However, if you call
(set-root-unwrapping! true)then single keyed top level maps will be "unwrapped" like so:
(list-tables)
=> ["TableOne" "TableTwo" "TableThree"]The returned data can be "round tripped" as well. So the returned Clojure data structures can be supplied as arguments to function calls which delegate to Java methods taking the same object type as an argument. See the section below for more on this.
Coercion of any types that are part of the java.lang wrapper classes happens transparently. So for example, Clojure's preferred longs are automatically converted to ints where required.
Clojure data structures automatically participate in the Java Collections abstractions, and so no explicit coercion is necessary. Typically when service calls take collections as parameter arguments, as in the case above, the values in the collections are most often instances of the Java wrapper classes.
When complex objects consisting of types outside of those in the java.lang package are required as argument parameters, smart conversions are attempted based on the argument types of the underlying Java method signature. Methods requiring a java.util.Date argument can take Joda Time org.joda.time.base.AbstractInstants, longs, or Strings (default pattern is "yyyy-MM-dd"), with conversion happening automatically.
(set-date-format! "MM-dd-yyyy")can be used to set the pattern supplied to the underlying java.text.SimpleDateFormat.
In cases where collection arguments contain instances of AWS "model" classes, Clojure maps will be converted to the appropriate AWS Java bean instance. So for example, describeAvailabilityZones() can take a DescribeAvailabilityZonesRequest which itself has a filters property, which is a java.util.List of com.amazonaws.services.ec2.model.Filters. Passing the filters argument would look like:
(describe-availability-zones :filters [{:name "environment"
:values ["dev" "qa" "staging"]}])and return the following Clojure collection:
{:availability-zones
[{:state "available",
:region-name "us-east-1",
:zone-name "us-east-1a",
:messages []}
{:state "available",
:region-name "us-east-1",
:zone-name "us-east-1b",
:messages []}
{:state "available",
:region-name "us-east-1",
:zone-name "us-east-1c",
:messages []}
{:state "available",
:region-name "us-east-1",
:zone-name "us-east-1d",
:messages []}
{:state "available",
:region-name "us-east-1",
:zone-name "us-east-1e",
:messages []}]}Clojure apis built specifically to wrap a Java client, such as this one, often provide "conveniences" for the user of the api, to remove boilerplate. In Amazonica this is accomplished via the IMarshall protocol, which defines the contract for converting the returned Java result from the AWS service call to Clojure data, and the
(amazonica.core/register-coercions)function, which takes a map of class/function pairs defining how a value should be coerced to a specific AWS Java bean. You can find a good example of this in the amazonica.aws.dynamodb namespace. Consider the following DynamoDB service call:
(get-item :table-name "MyTable"
:key "foo")The GetItemRequest takes a com.amazonaws.services.dynamodb.model.Key which is composed of a hash key of type com.amazonaws.services.dynamodb.model.AttributeValue and optional range key also of type AttributeValue. Without the coercions registered for Key and AttributeValue in amazonica.aws.dynamodb we would need to write:
(get-item :table-name "TestTable"
:key {:hash-key-element {:s "foo"}})Note that either form will work. This allows contributors to the library to incrementally evolve the api independently from the core of the library, as well as maintain backward compatibility of existing code written against prior versions of the library which didn't contain the conveniences.
The default authentication scheme is to use the chained Provider class from the AWS SDK, whereby authentication is attempted in the following order:
- Environment Variables - AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY
- Java System Properties - aws.accessKeyId and aws.secretKey
- Credential profiles file at the default location (~/.aws/credentials) shared by all AWS SDKs and the AWS CLI
- Instance profile credentials delivered through the Amazon EC2 metadata service
Note that in order for the Instance Profile Metadata to be found, you must have launched the instance with a provided IAM role, and the same permissions as the IAM Role the instance was launched with will apply.
See the AWS docs for reference.
Additionally, all of the functions may take as their first argument an optional map of credentials:
(def cred {:access-key "aws-access-key"
:secret-key "aws-secret-key"
:endpoint "us-west-1"})
(describe-instances cred)The credentials map may contain zero or one of the following:
:access-keyand:secret-key, in which case an instance ofBasicAWSCredentialswill be created.:session-token, in which case an instance ofBasicSessionCredentialswill be created.:profile, in which case an instance ofProfileCredentialsProviderwill be created.:cred, in which case theAWSCredentialsProviderinstance provided will be used.- Or rather than a Clojure map, the argument may be an actual instance or subclass of either
AWSCredentialsProviderorAWSCredentials.
In addition, the credentials map may contain an :endpoint entry. If the value of the :endpoint key is a lower case, hyphenated translation of one of the Regions enums, .setRegion will be called on the Client, otherwise .setEndpoint will be called.
Note: The first function called (for each distinct AWS service namespace, e.g. amazonica.aws.ec2) creates an Amazon*Client, which is effectively cached via memoization. Therefore, if you explicitly pass different credentials maps to different functions, you will effectively have different Clients.
For example, to work with ec2 instances in different regions you might do something like:
(ec2/create-image {:endpoint "us-east-1"} :instance-id "i-1b9a9f71")
(ec2/create-image {:endpoint "us-west-2"} :instance-id "i-kj239d7d")You will have created two AmazonEC2Clients, pointing to the two different regions. Likewise, if you omit the explicit credentials map then the DefaultAWSCredentialsProviderChain will be used. So in the following scenario you will again have two different Amazon*Clients:
(set-s3client-options :path-style-access true)
(create-bucket credentials "foo")The call to set-s3client-options will use a DefaultAWSCredentialsProviderChain, while the create-bucket call will create a separate AmazonS3Client with BasicAWSCredentials.
As a convenience, users may call (defcredential) before invoking any service functions and passing in their AWS key pair and an optional endpoint:
(defcredential "aws-access-key" "aws-secret-key" "us-west-1")All subsequent API calls will use the specified credential. If you need to execute a service call with alternate credentials, or against a different region than the one passed to (defcredential), you can wrap these ad-hoc calls in the (with-credential) macro, which takes a vector of key pair credentials and an optional endpoint, like so:
(defcredential "account-1-aws-access-key" "aws-secret-key" "us-west-1")
(describe-instances)
; returns instances visible to account-1
(with-credential ["account-2-aws-access-key" "secret" "us-east-1"]
(describe-instances))
; returns EC2 instances visible to account-2 running in US-East region
(describe-images :owners ["self"])
; returns images belonging to account-1You can supply a :client-config entry in the credentials map to configure the ClientConfiguration that the Amazon client uses. This is useful if you need to use a proxy.
(describe-images {:client-config {:proxy-host "proxy.address.com" :proxy-port 8080}})When using localstack (or other AWS mocks) it may be necessary to pass some configuration to the client.
This cannot be done anymore via the (set-s3client-options :path-style-access true) which would lead to a Client is immutable when created with the builder. exception
This is particularly useful for S3, which in a typical localstack scenario needs path-style-access set to true
This is a working example, please note the config keys
(s3/list-buckets
{:client-config {
:path-style-access-enabled true
:chunked-encoding-disabled false
:accelerate-mode-enabled false
:payload-signing-enabled true
:dualstack-enabled true
:force-global-bucket-access-enabled true}})
All functions throw com.amazonaws.AmazonServiceExceptions. If you wish to catch exceptions you can convert the AWS object to a Clojure map like so:
(try
(create-snapshot :volume-id "vol-ahsg23h"
:description "daily backup")
(catch Exception e
(log (ex->map e))))
; {:error-code "InvalidParameterValue",
; :error-type "Unknown",
; :status-code 400,
; :request-id "9ba69e16-ed63-41d4-ac02-1f6032cb64de",
; :service-name "AmazonEC2",
; :message
; "Value (vol-ahsg23h) for parameter volumeId is invalid. Expected: 'vol-...'.",
; :stack-trace "Status Code: 400, AWS Service: AmazonEC2, AWS Request ID: a5b0340a-8f37-4122-941c-ed8d5472b11d, AWS Error Code: InvalidParameterValue, AWS Error Message: Value (vol-ahsg23h) for parameter volumeId is invalid. Expected: 'vol-...'.
; at com.amazonaws.http.AmazonHttpClient.handleErrorResponse(AmazonHttpClient.java:644)
; at com.amazonaws.http.AmazonHttpClient.executeHelper(AmazonHttpClient.java:338)
; at com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:190)
; at com.amazonaws.services.ec2.AmazonEC2Client.invoke(AmazonEC2Client.java:6199)
; at com.amazonaws.services.ec2.AmazonEC2Client.createSnapshot(AmazonEC2Client.java:1531)
; .....If you're especially concerned about the size of your uberjar, you can limit the transitive dependencies pulled in by the AWS Java SDK, which currently total 35mb. You'll need to exclude the entire AWS Java SDK, the Amazon Kinesis Client, and the DynamoDB streams kinesis adapter, and then add back only those services you'll be using (although core is always required). So for example, if you were only using S3, you could restrict the dependencies to only include the required jars like so:
:dependencies [[org.clojure/clojure "1.10.3"]
[amazonica "0.3.156" :exclusions [com.amazonaws/aws-java-sdk
com.amazonaws/amazon-kinesis-client
com.amazonaws/dynamodb-streams-kinesis-adapter]]
[com.amazonaws/aws-java-sdk-core "1.11.968"]
[com.amazonaws/aws-java-sdk-s3 "1.11.968"]]As always, lein test will run all the tests. Note that some of the namespaces require the file ~/.aws/credentials to be present and be of the same form as required by the official AWS tools:
[default]
aws_access_key_id = AKIAABCDEFGHIEJK
aws_secret_access_key = 6rqzvpAbcd1234++zyx987WUV654sRq
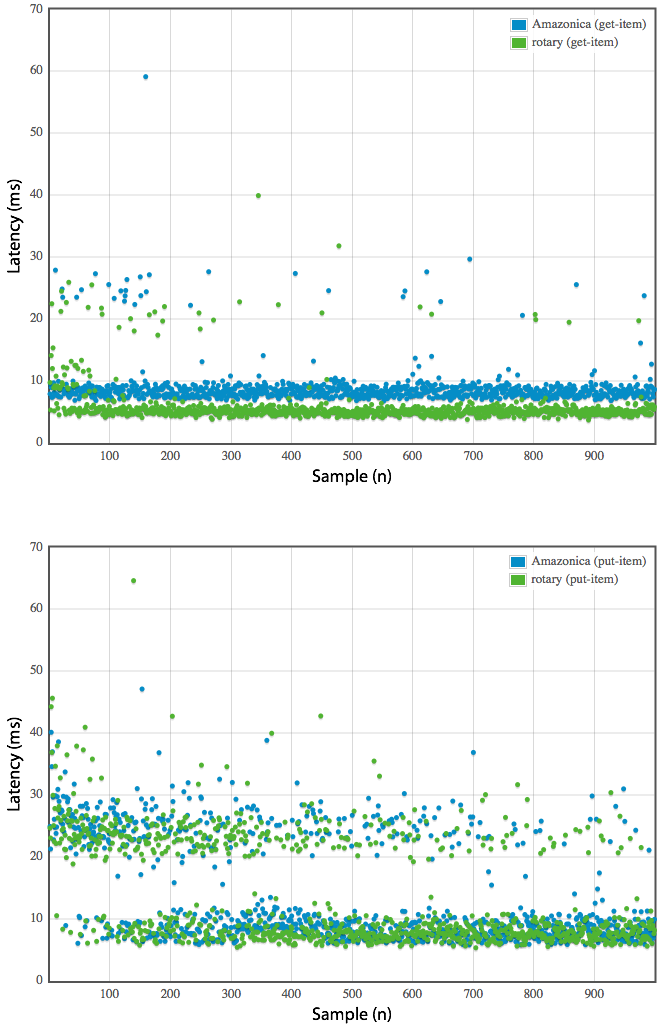
Amazonica uses reflection extensively, to generate the public Vars, to set the bean properties passed as arguments to those functions, and to invoke the actual service method calls on the underlying AWS Client class. As such, one may wonder if such pervasive use of reflection will result in unacceptable performance. In general, this shouldn't be an issue, as the cost of reflection should be relatively minimal compared to the latency incurred by making a remote call across the network. Furthermore, typical AWS usage is not going to be terribly concerned with performance, except with specific services such as DynamoDB, RDS, SimpleDB, or SQS. But we have done some basic benchmarking against the excellent DynamoDB rotary library, which uses no explicit reflection. Results are shown below. Benchmarking code is available at https://github.com/mcohen01/amazonica-benchmark
(ns com.example
(:use [amazonica.aws.autoscaling]))
(create-launch-configuration :launch-configuration-name "aws_launch_cfg"
:block-device-mappings [
{:device-name "/dev/sda1"
:virtual-name "vol-b0e519c3"
:ebs {:snapshot-id "snap-36295e51"
:volume-size 32}}]
:ebs-optimized true
:image-id "ami-6fde0d06"
:instance-type "m1.large"
:spot-price ".10")
(create-auto-scaling-group :auto-scaling-group-name "aws_autoscale_grp"
:availability-zones ["us-east-1a" "us-east-1b"]
:desired-capacity 3
:health-check-grace-period 300
:health-check-type "EC2"
:launch-configuration-name "aws_launch_cfg"
:min-size 3
:max-size 3)
(describe-auto-scaling-instances)
(ns com.example
(:use [amazonica.aws.batch]))
(submit-job :job-name "my-job"
:job-definition "my-job-definition"
:job-queue "my-job-queue"
:parameters {"example-url" "example.com"})(ns com.example
(:use [amazonica.aws.cloudformation]))
(create-stack :stack-name "my-stack"
:template-url "abcd1234.s3.amazonaws.com")
(describe-stack-resources :stack-name "my_cloud_stack")
(ns com.example
(:use [amazonica.aws.cloudfront]))
(create-distribution :distribution-config {
:enabled true
:default-root-object "index.html"
:origins
{:quantity 0
:items []}
:logging
{:enabled false
:include-cookies false
:bucket "abcd1234.s3.amazonaws.com"
:prefix "cflog_"}
:caller-reference 12345
:aliases
{:items ["m.example.com" "www.example.com"]
:quantity 2}
:cache-behaviors
{:quantity 0
:items []}
:comment "example"
:default-cache-behavior
{:target-origin-id "MyOrigin"
:forwarded-values
{:query-string false
:cookies
{:forward "none"}}}
:trusted-signers
{:enabled false
:quantity 0}
:viewer-protocol-policy "allow-all"
:min-ttl 3600}
:price-class "PriceClass_All"})
(list-distributions :max-items 10)
(ns com.example
(:use [amazonica.aws.cloudsearch]))
(create-domain :domain-name "my-index")
(index-documents :domain-name "my-index")
(ns com.example
(:use [amazonica.aws.cloudsearchv2]))
(create-domain :domain-name "my-index")
(index-documents :domain-name "my-index")
(build-suggesters :domain-name "my-index")
(list-domains)
;; get the document and search service endpoints
(clojure.pprint/pprint
(amazonica.aws.cloudsearchv2/describe-domains))
(csd/set-endpoint "doc-domain-name-6fihexkq1234567895wm.us-east-1.cloudsearch.amazonaws.com")
(csd/upload-documents
:content-type "application/json"
:documents (io/input-stream json-documents))
(csd/set-endpoint "search-domain-name-6fihexkq1234567895wm.us-east-1.cloudsearch.amazonaws.com")
;; http://docs.aws.amazon.com/AWSJavaSDK/latest/javadoc/com/amazonaws/services/cloudsearchdomain/model/SearchRequest.html
(csd/search :query "drumpf")
(csd/suggest :query "{\"query\": \"make donald drumpf\""
:suggester "url_suggester")
(ns com.example
(:use [amazonica.aws.cloudwatch]))
(put-metric-alarm :alarm-name "my-alarm"
:actions-enabled true
:evaluation-periods 5
:period 60
:metric-name "CPU"
:threshold "50%")
To put metric data. UnitTypes
(put-metric-data
{:endpoint "us-west-1"} ;; Defaults to us-east-1
:namespace "test_namespace"
:metric-data [{:metric-name "test_metric"
:unit "Count"
:value 1.0
:dimensions [{:name "test_name" :value "test_value"}]}])To batch get metric data.
(get-metric-data
:start-time "2018-06-14T00:00:00Z"
:end-time "2018-06-15T00:00:00Z"
:metric-data-queries [{:id "test"
:metricStat {:metric {:namespace "AWS/DynamoDB"
:metricName "ProvisionedReadCapacityUnits"
:dimensions [{:name "TableName"
:value "MyTableName"}]}
:period 86400
:stat "Sum"
:unit "Count"}}])(ns com.example
(:use [amazonica.aws.cloudwatchevents]))
(put-rule
:name "nightly-backup"
:description "Backup DB nightly at 10:00 UTC (2 AM or 3 AM Pacific)"
:schedule-expression "cron(0 10 * * ? *)")
(put-targets
:rule "nightly-backup"
:targets [{:id "backup-lambda"
:arn "arn:aws:lambda:us-east-1:123456789012:function:backup-lambda"
:input (json/write-str {"whatever" "arguments"})}])(ns com.example
(:use [amazonica.aws.codedeploy]))
(list-applications)
(ns com.example
(:require [amazonica.aws.cognitoidp :refer :all]))
(list-user-pools {:max-results 2})
=> {:user-pools [{:lambda-config {}, :last-modified-date "2017-06-16T14:16:28.950-03:00"], :creation-date "2017-06-15T16:23:04.555-03:00"], :name "Amazonica", :id "us-west-1_example"}]}
(ns com.example
(:require [amazonica.aws.comprehend :refer :all]))
(amazonica.aws.comprehend/detect-entities {:language-code "en" :text "Hi my name is Joe Bloggs and I live in Glasgow, Scotland"})
=> {:entities [{:type "PERSON", :text "Joe Bloggs", :score 0.99758613, :begin-offset 14, :end-offset 24} {:type "LOCATION", :text "Glasgow, Scotland", :score 0.93267196, :begin-offset 39, :end-offset 56}]}(ns com.example
(:use [amazonica.aws.datapipeline]))
(create-pipeline :name "my-pipeline"
:unique-id "mp")
(put-pipeline-definition :pipeline-id "df-07746012XJFK4DK1D4QW"
:pipeline-objects [{:name "my-pipeline-object"
:id "my-pl-object-id"
:fields [{:key "some-key"
:string-value "foobar"}]}])
(list-pipelines)
(delete-pipeline :pipeline-id pid)
(ns com.example
(:use [amazonica.aws.dynamodbv2]))
(def cred {:access-key "aws-access-key"
:secret-key "aws-secret-key"
:endpoint "http://localhost:8000"})
(create-table cred
:table-name "TestTable"
:key-schema
[{:attribute-name "id" :key-type "HASH"}
{:attribute-name "date" :key-type "RANGE"}]
:attribute-definitions
[{:attribute-name "id" :attribute-type "S"}
{:attribute-name "date" :attribute-type "N"}
{:attribute-name "column1" :attribute-type "S"}
{:attribute-name "column2" :attribute-type "S"}]
:local-secondary-indexes
[{:index-name "column1_idx"
:key-schema
[{:attribute-name "id" :key-type "HASH"}
{:attribute-name "column1" :key-type "RANGE"}]
:projection
{:projection-type "INCLUDE"
:non-key-attributes ["id" "date" "column1"]}}
{:index-name "column2_idx"
:key-schema
[{:attribute-name "id" :key-type "HASH"}
{:attribute-name "column2" :key-type "RANGE"}]
:projection {:projection-type "ALL"}}]
:provisioned-throughput
{:read-capacity-units 1
:write-capacity-units 1})
(put-item cred
:table-name "TestTable"
:return-consumed-capacity "TOTAL"
:return-item-collection-metrics "SIZE"
:item {
:id "foo"
:date 123456
:text "barbaz"
:column1 "first name"
:column2 "last name"
:numberSet #{1 2 3}
:stringSet #{"foo" "bar"}
:mixedList [1 "foo"]
:mixedMap {:name "baz" :secret 42}})
(get-item cred
:table-name "TestTable"
:key {:id {:s "foo"}
:date {:n 123456}})
(query cred
:table-name "TestTable"
:limit 1
:index-name "column1_idx"
:select "ALL_ATTRIBUTES"
:scan-index-forward true
:key-conditions
{:id {:attribute-value-list ["foo"] :comparison-operator "EQ"}
:column1 {:attribute-value-list ["first na"] :comparison-operator "BEGINS_WITH"}})
(batch-write-item
cred
:return-consumed-capacity "TOTAL"
:return-item-collection-metrics "SIZE"
:request-items
{"TestTable"
[{:delete-request
{:key {:id "foo"
:date 123456}}}
{:put-request
{:item {:id "foobar"
:date 3172671
:text "bunny"
:column1 "funky"}}}]})
;; dynamodb-expressions https://github.com/brabster/dynamodb-expressions
;; exists to make update expressions easier to write for Amazonica.
(update-item
cred
:table-name "TestTable"
:key {:id "foo"}
:update-expression "ADD #my_foo :x SET bar.baz = :y"
:expression-attribute-names {"#my_foo" "my-foo"}
:expression-attribute-values {":x" 1
":y" "barbaz"})
(batch-get-item
cred
:return-consumed-capacity "TOTAL"
:request-items {
"TestTable" {:keys [{"id" {:s "foobar"}
"date" {:n 3172671}}
{"id" {:s "foo"}
"date" {:n 123456}}]
:consistent-read true
:attributes-to-get ["id" "text" "column1"]}})
(scan cred :table-name "TestTable")
(describe-table cred :table-name "TestTable")
(delete-table cred :table-name "TestTable")
;; Amazonica depends on `[com.amazonaws/amazon-kinesis-client]`
;; which has a dependency on `[com.amazonaw/aws-java-sdk-dynamodb]`.
;; The version of this dependency is too old to support TTL,
;; so you'll need to exclude it and explicitly depend on a recent version
;; of `com.amazonaw/aws-java-sdk-dynamodb` like `1.0.9` to use this feature for now.
(update-time-to-live
cred
:table-name "TestTable"
:time-to-live-specification {:attribute-name "foo" :enabled true}
(ns com.example
(:use [amazonica.aws.ec2]))
(-> (run-instances :image-id "ami-54f71039"
:instance-type "c3.large"
:min-count 1
:max-count 1)
(get-in [:reservation :instances 0 :instance-id]))
(describe-images :owners ["self"])
(describe-instances :filters [{:name "tag:env" :values ["production"]}])
(create-image :name "my_test_image"
:instance-id "i-1b9a9f71"
:description "test image - safe to delete"
:block-device-mappings [
{:device-name "/dev/sda1"
:virtual-name "myvirtual"
:ebs {
:volume-size 8
:volume-type "standard"
:delete-on-termination true}}])
(create-snapshot :volume-id "vol-8a4857fa"
:description "my_new_snapshot")
(ns com.example
(:require [amazonica.aws.ec2instanceconnect :refer :all]))
(send-ssh-public-key :availability-zone "eu-west-1"
:instance-id "i-1b9a9f71a756fe98"
:instance-os-user "ec2-user"
:ssh-public-key (slurp "/path/to/public/ssh/key"))
(ns com.example
(:require [amazonica.aws.ecs :refer :all]))
(register-task-definition
{:family "grafana2",
:container-definitions [{:name "grafana2"
:image "bbinet/grafana2",
:port-mappings [{:container-port 3000, :host-port 3000}]
:memory 300
:cpu 300
}]})
(describe-task-definition :task-definition "grafana2")
(list-task-definitions :family-prefix "grafana2")
;; create cluster
(create-cluster :cluster-name "Amazonica")
(list-clusters)
(describe-clusters)
(create-service :cluster "Amazonica"
:service-name "grafana2"
:task-definition "grafana2" :desired-count 1
;;:role "ecsServiceRole"
;;:load-balancers [...]
)
(list-services :cluster "Amazonica")
(describe-services :cluster "Amazonica" :services ["grafana2"])
;; add ec2 instances to your cluster
(update-service :cluster "Amazonica" :service "grafana2" :desired-count 0)
(delete-service :cluster "Amazonica" :service "grafana2")
(delete-cluster :cluster "Amazonica")
;; run task
(run-task
:cluster "Amazonica"
:launch-type LaunchType/FARGATE
:task-definition "task-def-name"
:overrides {:container-overrides [{:name "container-name"
:command ["java" "-jar" "artifact.jar" "arg1" "arg2"]}]}
:network-configuration {:aws-vpc-configuration {:assign-public-ip AssignPublicIp/ENABLED
:subnets ["subnet-XXXXXXXX"]
:security-groups ["sg-XXXXXXXXXXXXXXXX"]}})(require '[amazonica.aws.ecr :as ecr])
(ecr/describe-repositories {})
(ecr/create-repository :repository-name "amazonica")
(ecr/get-authorization-token {})
(ecr/list-images :repository-name "amazonica")
(ecr/delete-repository :repository-name "amazonica")(ns com.example
(:use [amazonica.aws.elasticache]))
(describe-cache-engine-versions)
(create-cache-cluster :engine "memcached"
:engine-version "1.4.14"
:num-cache-nodes 1
:cache-node-type "cache.t1.micro"
:cache-cluster-id "memcached-cluster")
(describe-cache-clusters)
(describe-events)
(delete-cache-cluster :cache-cluster-id "memcached-cluster")
(ns com.example
(:use [amazonica.aws.elasticbeanstalk]))
(describe-applications)
(describe-environments)
(create-environment creds
{:application-name "app"
:environment-name "env"
:version-label "1.0"
:solution-stack-name "64bit Amazon Linux 2014.09 v1.0.9 running Docker 1.2.0"
:option-settings [{:namespace "aws:elb:loadbalancer"
:option-name "LoadBalancerHTTPSPort"
:value "443"}
{:namespace "aws:elb:loadbalancer"
:option-name "LoadBalancerHTTPPort"
:value "OFF"}]}))
(describe-configuration-settings {:application-name "app" :environment-name "env"})(ns com.example
(:use [amazonica.aws.elasticloadbalancing]))
(deregister-instances-from-load-balancer :load-balancer-name "my-ELB"
:instances [{:instance-id "i-1ed40bad"}])
(register-instances-with-load-balancer :load-balancer-name "my-ELB"
:instances [{:instance-id "i-1fa370ea"}])
(ns com.example
(:use [amazonica.aws
elasticmapreduce
s3]))
(create-bucket :bucket-name "emr-logs"
:access-control-list {:grant-permission ["LogDelivery" "Write"]})
(set-bucket-logging-configuration :bucket-name "emr-logs"
:logging-configuration
{:log-file-prefix "hadoop-job_"
:destination-bucket-name "emr-logs"})
(run-job-flow :name "my-job-flow"
:log-uri "s3n://emr-logs/logs"
:instances
{:instance-groups [
{:instance-type "m1.large"
:instance-role "MASTER"
:instance-count 1
:market "SPOT"
:bid-price "0.10"}]}
:steps [
{:name "my-step"
:hadoop-jar-step
{:jar "s3n://beee0534-ad04-4143-9894-8ddb0e4ebd31/hadoop-jobs/bigml"
:main-class "bigml.core"
:args ["s3n://beee0534-ad04-4143-9894-8ddb0e4ebd31/data" "output"]}}])
(list-clusters)
(describe-cluster :cluster-id "j-38BW9W0NN8YGV")
(list-steps :cluster-id "j-38BW9W0NN8YGV")
(list-bootstrap-actions :cluster-id "j-38BW9W0NN8YGV")
(ns com.example
(:use [amazonica.awselasticsarch]))
(list-domain-names {})(ns com.example
(:use [amazonica.aws.elastictranscoder))
(list-pipelines)
;; -> {:pipelines []}
(list-presets)
;; -> {:presets [{:description "System preset generic 1080p", ....}]}
;; status can be :Submitted :Progressing :Complete :Canceled :Error
(list-jobs-by-status :status :Complete)
;; -> ...
(def new-pipeline-id (-> (create-pipeline
:role "arn:aws:iam::289431957111:role/Elastic_Transcoder_Default_Role",
:name "avi-to-mp4",
:input-bucket "avi-to-convert",
:output-bucket "converted-mp4")
:pipeline
:id))
;; -> "1111111111111-11aa11"
(create-job :pipeline-id "1111111111111-11aa11"
:input {:key "my/s3/input/obj/key.avi"}
:outputs [{:key "my/s3/output/obj/key.avi"
:preset-id "1351620000001-000030"}])(require '[amazonica.aws.forecast :as fc])
(fc/create-dataset :dataset-name "hourly_ts"
:data-frequency "H"
:dataset-type "TARGET_TIME_SERIES"
:domain "CUSTOM"
:schema {
:attributes [
{
:attribute-name "timestamp"
:attribute-type "timestamp"
},
{
:attribute-name "target_value"
:attribute-type "float"
},
{
:attribute-name "item_id"
:attribute-type "string"
}]})
;; {:dataset-arn "arn:aws:forecast:us-east-1:123456789012:dataset/hourly_ts"}
(fc/create-dataset-group :dataset-arns ["arn:aws:forecast:us-east-1:123456789012:dataset/hourly_ts"]
:dataset-group-name "hourly_ts"
:domain "CUSTOM")
;; {:dataset-group-arn "arn:aws:forecast:us-east-1:123456789012:dataset-group/hourly_ts"}
(require '[amazonica.aws.s3 :as s3])
(s3/put-object "amazonica-forecast"
"hourly_ts.csv"
(java.io.File. "/path/to/hourly_ts.csv"))
(fc/create-dataset-import-job :dataset-import-job-name "import_hourly_ts_job"
:dataset-arn "arn:aws:forecast:us-east-1:123456789012:dataset/hourly_ts"
:data-source {
:s3-config {
:path "s3://amazonica-forecast/hourly_ts.csv"
:role-arn "arn:aws:iam::123456789012:role/amazonica"}})
;; {:dataset-import-job-arn "arn:aws:forecast:us-east-1:123456789012:dataset-import-job/hourly_ts/import_hourly_ts_job"}
(fc/create-predictor :input-data-config {
:dataset-group-arn "arn:aws:forecast:us-east-1:123456789012:dataset-group/hourly_ts"}
:algorithm-arn "arn:aws:forecast:::algorithm/ARIMA"
:forecast-horizon 336
:featurization-config {
:forecast-frequency "H"}
:predictor-name "hourly_ts_predictor")
(fc/create-forecast :forecast-name "hourly_ts"
:predictor-arn "arn:aws:forecast:us-east-1:123456789012:predictor/hourly_ts_predictor")
(require '[amazonica.aws.forecastquery :as fq])
(fq/query-forecast :forecast-arn "arn:aws:forecast:us-east-1:123456789012:forecast/hourly_ts"
:filters {"item_id" "item1"})
(fc/delete-forecast :forecast-arn "arn:aws:forecast:us-east-1:123456789012:forecast/hourly_ts")
(fc/delete-predictor :predictor-arn "arn:aws:forecast:us-east-1:123456789012:predictor/hourly_ts_predictor")
(fc/delete-dataset :dataset-arn "arn:aws:forecast:us-east-1:123456789012:dataset/hourly_ts")
(fc/delete-dataset-group :dataset-group-arn "arn:aws:forecast:us-east-1:123456789012:dataset-group/hourly_ts")
(ns com.example
(:use [amazonica.aws.glacier]))
(create-vault :vault-name "my-vault")
(describe-vault :vault-name "my-vault")
(list-vaults :limit 10)
(upload-archive :vault-name "my-vault"
:body "upload.txt")
(delete-archive :account-id "-"
:vault-name "my-vault"
:archive-id "pgy30P2FTNu_d7buSVrGawDsfKczlrCG7Hy6MQg53ibeIGXNFZjElYMYFm90mHEUgEbqjwHqPLVko24HWy7DU9roCnZ1djEmT-1REvnHKHGPgkuzVlMIYk3bn3XhqxLJ2qS22EYgzg", :checksum "83a05fd1ce759e401b44fff8f34d40e17236bbdd24d771ec2ca4886b875430f9", :location "/676820690883/vaults/my-vault/archives/pgy30P2FTNu_d7buSVrGawDsfKczlrCG7Hy6MQg53ibeIGXNFZjElYMYFm90mHEUgEbqjwHqPLVko24HWy7DU9roCnZ1djEmT-1REvnHKHGPgkuzVlMIYk3bn3XhqxLJ2qS22EYgzg")
(delete-vault :vault-name "my-vault")
(ns com.example
(:use [amazonica.aws.identitymanagement]))
(def policy "{\"Version\": \"2012-10-17\", \"Statement\": [{\"Action\": [\"s3:*\"], \"Effect\": \"Allow\", \"Resource\": [\"arn:aws:s3:::bucket-name/*\"]}]}")
(create-user :user-name "amazonica")
(create-access-key :user-name "amazonica")
(put-user-policy
:user-name "amazonica"
:policy-name "s3policy"
:policy-document policy)
(ns com.example
(:require [amazonica.aws.iot :refer :all]))
(list-things {})
;; => {:things [{:thing-name "YourThing"}]}
(create-thing :thing-name "MyThing")
;; => {:thing-name "MyThing" :thing-arn "arn:aws:iot:...thing/MyThing"}(ns com.example
(:require [amazonica.aws.iotdata :refer :all]))
(get-thing-shadow :thing-name "MyThing")(ns com.example
(:use [amazonica.aws.kinesis]))
(create-stream "my-stream" 1)
(list-streams)
(describe-stream "my-stream")
(merge-shards "my-stream" "shardId-000000000000" "shardId-000000000001")
(split-shard "my-stream" "shard-id" "new-starting-hash-key")
;; write to the stream
;; #'put-record takes the name of the stream, any value as data, and the partition key
(let [data {:name "any data"
:col #{"anything" "at" "all"}
:date now}]
(put-record "my-stream"
data
(str (UUID/randomUUID))))
;; if anything BUT a java.nio.ByteBuffer is supplied as the second
;; argument, then the data will be transparently serialized and compressed
;; using Nippy, and deserialized on calls to (get-records), or via a worker
;; (see below), provided that a deserializer function is NOT supplied. If
;; you do pass a ByteBuffer instance as the data argument, then you'll need
;; to also provide a deserializer function when fetching records.
;; For bulk uploading, we provide a `put-records` function which takes in a sequence of maps
;; that contain the partition-key and data. As with `put-record` the data will be handled via
;; Nippy if it is not of a `java.nio.ByteBuffer`.
(put-records "my-stream"
[{:partition-key "x5h2ch" :data ["foo" "bar" "baz"]}
{:partition-key "x5j3ak" :data ["quux"]}])
;; optional :deserializer function which will be passed the raw
;; java.nio.ByteBuffer representing the data blob of each record
(defn- get-raw-bytes [byte-buffer]
(let [b (byte-array (.remaining byte-buffer))]
(.get byte-buffer b)
b))
;; manually read from a specific shard
;; this is not the preferred way to consume a shard
(get-records :deserializer get-raw-bytes
:shard-iterator (get-shard-iterator "my-stream"
shard-id
"TRIM_HORIZON"))
;; if no :deserializer function is supplied then it will be assumed
;; that the records were put into Kinesis by Amazonica, and hence,
;; the data was serialized and compressed by Nippy (e.g. Snappy)
;; better way to consume a shard....create and run a worker
;; :app :stream and :processor keys are required
;; :credentials, :checkpoint and :dynamodb-adaptor-client? keys are optional
;; if no :checkpoint is provided the worker will automatically checkpoint every 60 seconds
;; alternatively, supply a numeric value for duration in seconds between checkpoints
;; for full checkpoint control, set :checkpoint to false and return true from the
;; :processor function only when you want checkpoint to be called
;; if no :credentials key is provided the default authentication scheme is used (preferable),
;; see the [Authentication] #(authentication) section above
;; if no :dynamodb-adaptor-client? is provided, then it defaults to not using the
;; DynamoDB Streams Kinesis Adaptor. Set this flag to true when consuming streams
;; from DynamoDB
;; returns the UUID assigned to this worker
(worker! :app "app-name"
:stream "my-stream"
:checkpoint false ;; default to disabled checkpointing, can still force
;; a checkpoint by returning true from the processor function
:processor (fn [records]
(doseq [row records]
(println (:data row)
(:sequence-number row)
(:partition-key row)))))
(delete-stream "my-stream")
(ns com.example
(:require [amazonica.aws.kinesisanalytics :as ka]))
(ka/create-application
:application-name "my-ka-app"
:inputs [
{:name-prefix "prefix_"
:input-schema {:record-format {:record-format-type "json"}}
:kinesis-treams-input {:resource-ARN "fobar"}}
]
:outputs [...]})
(ns com.example
(:require [amazonica.aws.kinesisfirehose :as fh])
(:import [java.nio ByteBuffer]))
;; List delivery streams
(fh/list-delivery-streams)
;; => {:delivery-stream-names ("test-firehose" "test-firehose-2"), :has-more-delivery-streams false}
(fh/describe-delivery-stream :delivery-stream-name "my-test-firehose")
;; => {:delivery-stream-description
;; {:version-id "2", ....}}
(fh/create-delivery-stream :delivery-stream-name "my-test-firehose-2"
:s3DestinationConfiguration {:role-arn "arn:aws:iam:xxxx:role/firehose_delivery_role",
:bucket-arn "arn:aws:s3:::my-test-bucket"})
;; => {:delivery-stream-arn "arn:aws:firehose:us-west-2:xxxxx:deliverystream/my-test-firehose-2"}
;; Describe delivery stream
(fh/describe-delivery-stream cred :delivery-stream-name stream-name)
;; Update destination
(fh/update-destination cred {:current-delivery-stream-version-id version-id
:delivery-stream-name stream-name
:destination-id destination-id
:s3-destination-update {:BucketARN (str "arn:aws:s3:::" new-bucket-name)
:BufferingHints {:IntervalInSeconds 300
:SizeInMBs 5}
:CompressionFormat "UNCOMPRESSED"
:EncryptionConfiguration {:NoEncryptionConfig "NoEncryption"}
:Prefix "string"
:RoleARN "arn:aws:iam::123456789012:role/firehose_delivery_role"}})
;; Put batch of records to stream. Records are converted to instances of ByteBuffer if possible. Sequences are converted to CSV formatted strings for injestion into RedShift.
(fh/put-record-batch cred stream-name [[1 2 3 4]["test" 2 3 4] "\"test\",2,3,4" (ByteBuffer. (.getBytes "test,2,3,4"))])
;; Put individual record to stream.
(fh/put-record stream-name "test")
;; Delete delivery stream
(fh/delete-delivery-stream "stream-name")
(ns com.example
(:use [amazonica.aws.kms]))
(create-key)
(list-keys)
(disable-key "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx")(ns com.example
(:use [amazonica.aws.logs]))
(describe-log-streams :log-group-name "my-log-group"
:order-by "LastEventTime"
:descending true)(ns com.example
(:use [amazonica.aws.lambda]))
(let [role "arn:aws:iam::123456789012:role/some-lambda-role"
handler "exports.helloWorld = function(event, context) {
console.log('value1 = ' + event.key1)
console.log('value2 = ' + event.key2)
console.log('value3 = ' + event.key3)
context.done(null, 'Hello World')
}"]
(create-function :role role :function handler))
(invoke :function-name "helloWorld"
:payload "{\"key1\": 1, \"key2\": 2, \"key3\": 3}")
(ns com.example
(:use [amazonica.aws.opsworks]))
(create-stack :name "my-stack"
:region "us-east-1"
:default-os "Ubuntu 12.04 LTS"
:service-role-arn "arn:aws:iam::676820690883:role/aws-opsworks-service-role")
(create-layer :name "webapp-layer"
:stack-id "dafa328e-c529-41af-89d3-12840a31abad"
:enable-auto-healing true
:auto-assign-elastic-ips true
:volume-configurations [
{:mount-point "/data"
:number-of-disks 1
:size 50}])
(create-instance :hostname "node-app-1"
:instance-type "m1.large"
:stack-id "dafa328e-c529-41af-89d3-12840a31abad"
:layer-ids ["660d00da-c533-43d4-8c7f-2df240fd563f"]
:availability-zone "us-east-1a"
:autoscaling-type "LoadBasedAutoScaling"
:os "Ubuntu 12.04 LTS"
:ssh-key-name "admin")
(describe-stacks :stack-ids ["dafa328e-c529-41af-89d3-12840a31abad"])
(describe-layers :stack-id "dafa328e-c529-41af-89d3-12840a31abad")
(describe-instances :stack-id "dafa328e-c529-41af-89d3-12840a31abad"
:layer-id "660d00da-c533-43d4-8c7f-2df240fd563f"
:instance-id "93bc5049-1bd4-49c8-a6ef-e84145807f71")
(start-stack :stack-id "660d00da-c533-43d4-8c7f-2df240fd563f")
(start-instance :instance-id "93bc5049-1bd4-49c8-a6ef-e84145807f71")
(ns com.example
(:require [amazonica.aws.pinpoint :as pp]))
(defn app-id []
(-> (pp/get-apps {})
:applications-response
:item
first
:id))
(pp/create-segment {:application-id (app-id)})
(pp/create-campaign
{:application-id (app-id)
:write-campaign-request
{:segment-id "a668b484bec94cb1252772032ecdf540"
:name "my-campaign"
:schedule
{:frequency "ONCE"
:start-time "2017-09-27T20:36:11+00:00"}
:message-configuration
{:default-message
{:body "hello world"}}}})
(pp/send-messages
{:application-id (app-id)
:message-request
{:addresses {"+18132401139" {:channel-type "SMS"}}
:message-configuration {:default-message {:body "hello world"}}}})(ns com.example
(:use [amazonica.aws.redshift]))
(create-cluster :availability-zone "us-east-1a"
:cluster-type "multi-node"
:db-name "dw"
:master-username "scott"
:master-user-password "tiger"
:number-of-nodes 3)
(ns com.example
(:use [amazonica.aws.route53]))
(create-health-check :health-check-config {:port 80,
:type "HTTP",
:ipaddress "127.0.0.1",
:fully-qualified-domain-name "example.com"})
(get-health-check :health-check-id "ce6a4aeb-acf1-4923-a116-cd9ae2c30ee3")
(create-hosted-zone :name "example69.com"
:caller-reference (str (java.util.UUID/randomUUID)))
(get-hosted-zone :id "Z3TKY0VR5CH45U")
(list-hosted-zones)
(list-health-checks)
(list-resource-record-sets :hosted-zone-id "ZN8D0HXQLVRRL")
(delete-health-check :health-check-id "99999999-1234-4923-a116-cd9ae2c30ee3")
(delete-hosted-zone :id "my-bogus-hosted-zone")
(ns com.example
(:use [amazonica.aws.route53domains]))
(list-domains)
(check-domain-availability :domain-name "amazon.com")
(check-domain-transferability :domain-name "amazon.com")
(get-domain-detail :domain-name "amazon.com")
(let [contact {:first-name "Michael"
:last-name "Cohen"
:organization-name "amazonica"
:address-line1 "375 11th St"
:city "San Francisco"
:state "CA"
:zip-code "94103-2097"
:country-code "US"
:email ""
:phone-number "+1.4158675309"
:contact-type "PERSON"}]
(register-domain :domain-name "amazon.com"
:duration-in-years 10
:auto-renew true
:tech-contact contact
:admin-contact contact
:registrant-contact contact))
(ns com.example
(:use [amazonica.aws.s3]
[amazonica.aws.s3transfer]))
(create-bucket "two-peas")
;; put object with server side encryption
(put-object :bucket-name "two-peas"
:key "foo"
:metadata {:server-side-encryption "AES256"}
:file upload-file)
(copy-object bucket1 "key-1" bucket2 "key-2")
(-> (get-object bucket2 "key-2")
:input-stream
slurp)
;; (note that the InputStream returned by GetObject should be closed,
;; e.g. via slurp here, or the HTTP connection pool will be exhausted
;; after several objects are retrieved)
(delete-object :bucket-name "two-peas" :key "foo")
(generate-presigned-url bucket1 "key-1" (-> 6 hours from-now))
(def file "big-file.jar")
(def down-dir (java.io.File. (str "/tmp/" file)))
(def bucket "my-bucket")
;; set S3 Client Options
(s3/list-buckets
{:client-config {
:path-style-access-enabled false
:chunked-encoding-disabled false
:accelerate-mode-enabled false
:payload-signing-enabled true
:dualstack-enabled true
:force-global-bucket-access-enabled true}})
;; list objects in bucket
(list-objects-v2
{:bucket-name bucket
:prefix "keys/start/with/this" ; optional
:continuation-token (:next-continuation-token prev-response)}) ; when paging through results
(def key-pair
(let [kg (KeyPairGenerator/getInstance "RSA")]
(.initialize kg 1024 (SecureRandom.))
(.generateKeyPair kg)))
;; put object with client side encryption
(put-object :bucket-name bucket1
:key "foo"
:encryption {:key-pair key-pair}
:file upload-file)
;; get object and decrypt
(get-object :bucket-name bucket1
:encryption {:key-pair key-pair}
:key "foo")))))
;; get tags for the bucket
(get-bucket-tagging-configuration {:bucket-name bucket})
;; get just object metadata, e.g. content-length without fetching content:
(get-object-metadata :bucket-name bucket1
:key "foo")
;; put object from stream
(def some-bytes (.getBytes "Amazonica" "UTF-8"))
(def input-stream (java.io.ByteArrayInputStream. some-bytes))
(put-object :bucket-name bucket1
:key "stream"
:input-stream input-stream
:metadata {:content-length (count some-bytes)}
:return-values "ALL_OLD")
(let [upl (upload bucket
file
down-dir)]
((:add-progress-listener upl) #(println %)))
(let [dl (download bucket
file
down-dir)
listener #(if (= :completed (:event %))
(println ((:object-metadata dl)))
(println %))]
((:add-progress-listener dl) listener))
;; setup S3 bucket for static website hosting
(create-bucket bucket-name)
(put-object bucket-name
"index.html"
(java.io.File. "index.html"))
(let [policy {:Version "2012-10-17"
:Statement [{
:Sid "PublicReadGetObject"
:Effect "Allow"
:Principal "*"
:Action ["s3:GetObject"]
:Resource [(str "arn:aws:s3:::" bucket-name "/*")]}]}
json (cheshire.core/generate-string policy true)]
(set-bucket-policy bucket-name json))
(set-bucket-website-configuration
:bucket-name bucket-name
:configuration {
:index-document-suffix "index.html"})
(s3/set-bucket-notification-configuration
:bucket-name "my.bucket.name"
:notification-configuration
{:configurations
{:some-config-name
{:queue "arn:aws:sqs:eu-west-1:123456789012:my-sqs-queue-name"
:events #{"s3:ObjectCreated:*"}
;; list of key value pairs as maps or nexted 2 element list
:filter [{"foo" "bar"}
{:baz "quux"}
["key" "value"]]}}})
(s3/set-bucket-tagging-configuration
:bucket-name "my.bucket.name"
:tagging-configuration
{:tag-sets [{:Formation "notlive" :foo "bar" :baz "quux"}]})
(ns com.example
(:require [amazonica.aws.simpledb :as sdb]))
(sdb/create-domain :domain-name "domain")
(sdb/list-domains)
(sdb/put-attributes :domain-name "domain"
:item-name "my-item"
:attributes [{:name "foo"
:value "bar"}
{:name "baz"
:value 42}])
(sdb/select :select-expression
"select * from `test.domain` where baz = '42' ")
(sdb/delete-domain :domain-name "domain")
(ns com.example
(:require [amazonica.aws.simpleemail :as ses]))
(ses/send-email :destination {:to-addresses ["example@example.com"]}
:source "no-reply@example.com"
:message {:subject "Test Subject"
:body {:html "testing 1-2-3-4"
:text "testing 1-2-3-4"}})(ns com.example
(:require [amazonica.aws.simplesystemsmanagement :as ssm]))
(ssm/get-parameter :name "my-param-name")(ns com.example
(:use [amazonica.aws.simpleworkflow]))
(def domain "my-wkfl")
(def version "1.0")
(register-domain :name domain
:workflow-execution-retention-period-in-days "30")
(register-activity-type :domain domain
:name "my-worflow"
:version version)
(register-workflow-type :domain domain
:name "my-worflow"
:version version)
(deprecate-activity-type :domain domain
:activity-type {:name "my-worflow"
:version version})
(deprecate-workflow-type :domain domain
:workflowType {:name "my-worflow"
:version version})
(deprecate-domain :name domain)
(ns com.example
(:use [amazonica.aws.sns]))
(create-topic :name "my-topic")
(list-topics)
(subscribe :protocol "email"
:topic-arn "arn:aws:sns:us-east-1:676820690883:my-topic"
:endpoint "mcohen01@gmail.com")
(subscribe :protocol "lambda"
:topic-arn "arn:aws:sns:us-east-1:676820690883:my-topic"
:endpoint "arn:aws:lambda:us-east-1:676820690883:function:my-function")
;; provide endpoint in creds for topics in non-default region
(subscribe {:endpoint "eu-west-1"}
:protocol "lambda"
:topic-arn "arn:aws:sns:eu-west-1:676820690883:my-topic"
:endpoint "arn:aws:lambda:us-east-1:676820690883:function:my-function")
(clojure.pprint/pprint
(list-subscriptions))
(publish :topic-arn "arn:aws:sns:us-east-1:676820690883:my-topic"
:subject "test"
:message (str "Todays is " (java.util.Date.))
:message-attributes {"attr" "value"})
(unsubscribe :subscription-arn "arn:aws:sns:us-east-1:676820690883:my-topic:33fb2721-b639-419f-9cc3-b4adec0f4eda")
(ns com.example
(:use [amazonica.aws.sqs]))
(create-queue :queue-name "my-queue"
:attributes
{:VisibilityTimeout 30 ; sec
:MaximumMessageSize 65536 ; bytes
:MessageRetentionPeriod 1209600 ; sec
:ReceiveMessageWaitTimeSeconds 10}) ; sec
;; full list of attributes at
;; http://docs.aws.amazon.com/AWSJavaSDK/latest/javadoc/com/amazonaws/services/sqs/model/GetQueueAttributesRequest.html
(create-queue "DLQ")
(list-queues)
(def queue (find-queue "my-queue"))
(assign-dead-letter-queue
queue
(find-queue "DLQ")
10)
(send-message queue "hello world")
(def msgs (receive-message queue))
(delete-message (-> msgs
:messages
first
(assoc :queue-url queue)))
(receive-message :queue-url queue
:wait-time-seconds 6
:max-number-of-messages 10
:delete true ;; deletes any received messages after receipt
:attribute-names ["All"])
(-> "my-queue" find-queue delete-queue)
(-> "DLQ" find-queue delete-queue)
(ns com.example
(:use [amazonica.aws.stepfunctions]))
;this is to start the execution, then you need to run get-activity-task-result ultimately to monitor for pending requests from the state machine components
;to execute a worker task.
(start-state-machine "{\"test\":\"test\"}" "arn:aws:states:us-east-1:xxxxxxxxxx:stateMachine:test-sf")
;this will block until it returns a task in the queue from a state machine execution,
;so you need to run it in a while loop on the worker side of your app.
(let [tr (get-activity-task-result "arn:aws:states:us-east-1:xxxxxxxxx:activity:test-sf-activity")
input (:input tr)
token (:task-token tr)]
(if (<validate input here....>)
(mark-task-success "<json stuff to pipe back into the state machine....>" token)
(mark-task-failure token))
)
YourKit is kindly supporting the Amazonica open source project with its full-featured Java Profiler. YourKit, LLC is the creator of innovative and intelligent tools for profiling Java and .NET applications. Take a look at YourKit's leading software products: YourKit Java Profiler and YourKit .NET Profiler.

Copyright (C) 2013 Michael Cohen
Distributed under the Eclipse Public License, the same as Clojure.