JavaScript 数据结构与算法之美 - 归并排序、快速排序、希尔排序、堆排序 #40
Assignees

Labels
Data Structure and Algorithms
JavaScript 数据结构与算法之美
Comments
This was referenced Jul 25, 2019
|
quickSort1 有副作用, arr.splice(midIndex, 1) 每调用一次都会使原数组失去基准元素 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
1. 前言
想学好前端,先练好内功,只有内功深厚者,前端之路才会走得更远。
笔者写的 JavaScript 数据结构与算法之美 系列用的语言是 JavaScript ,旨在入门数据结构与算法和方便以后复习。
之所以把
归并排序、快速排序、希尔排序、堆排序放在一起比较,是因为它们的平均时间复杂度都为 O(nlogn)。请大家带着问题:
快排和归并用的都是分治思想,递推公式和递归代码也非常相似,那它们的区别在哪里呢 ?来阅读下文。2. 归并排序(Merge Sort)
思想
排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
归并排序采用的是
分治思想。分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。
实现
测试
分析
第一,归并排序是原地排序算法吗 ?
这是因为归并排序的合并函数,在合并两个有序数组为一个有序数组时,需要借助额外的存储空间。
实际上,尽管每次合并操作都需要申请额外的内存空间,但在合并完成之后,临时开辟的内存空间就被释放掉了。在任意时刻,CPU 只会有一个函数在执行,也就只会有一个临时的内存空间在使用。临时内存空间最大也不会超过 n 个数据的大小,所以空间复杂度是 O(n)。
所以,归并排序不是原地排序算法。
第二,归并排序是稳定的排序算法吗 ?
merge 方法里面的 left[0] <= right[0] ,保证了值相同的元素,在合并前后的先后顺序不变。归并排序是一种稳定的排序方法。
第三,归并排序的时间复杂度是多少 ?
从效率上看,归并排序可算是排序算法中的
佼佼者。假设数组长度为 n,那么拆分数组共需 logn 步, 又每步都是一个普通的合并子数组的过程,时间复杂度为 O(n),故其综合时间复杂度为 O(nlogn)。最佳情况:T(n) = O(nlogn)。
最差情况:T(n) = O(nlogn)。
平均情况:T(n) = O(nlogn)。
动画
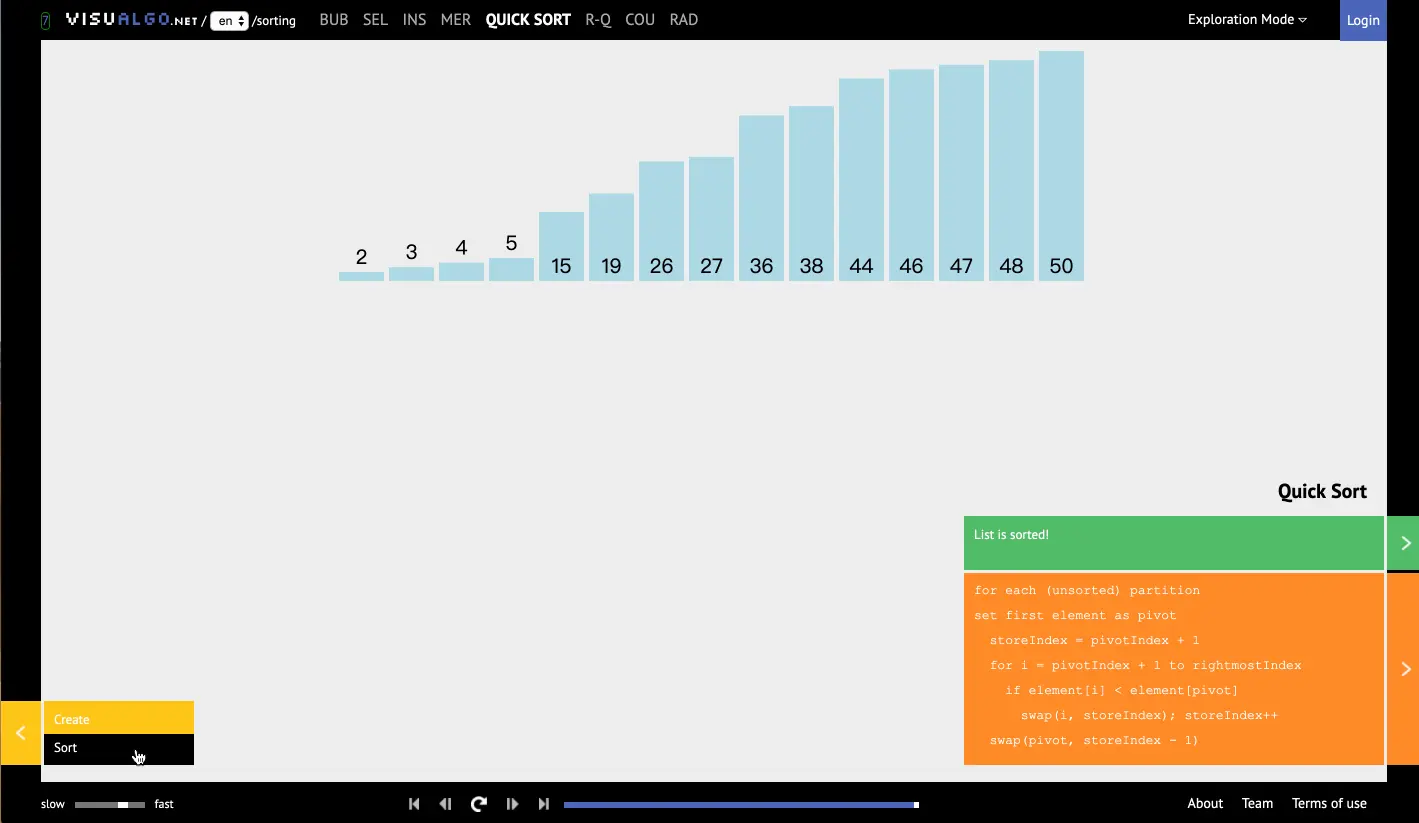
3. 快速排序 (Quick Sort)
快速排序的特点就是快,而且效率高!它是处理大数据最快的排序算法之一。
思想
特点:快速,常用。
缺点:需要另外声明两个数组,浪费了内存空间资源。
实现
方法一:
方法二:
测试
分析
第一,快速排序是原地排序算法吗 ?
因为 partition() 函数进行分区时,不需要很多额外的内存空间,所以快排是
原地排序算法。第二,快速排序是稳定的排序算法吗 ?
和选择排序相似,快速排序每次交换的元素都有可能不是相邻的,因此它有可能打破原来值为相同的元素之间的顺序。因此,快速排序并不稳定。
第三,快速排序的时间复杂度是多少 ?
极端的例子:如果数组中的数据原来已经是有序的了,比如 1,3,5,6,8。如果我们每次选择最后一个元素作为 pivot,那每次分区得到的两个区间都是不均等的。我们需要进行大约 n 次分区操作,才能完成快排的整个过程。每次分区我们平均要扫描大约 n / 2 个元素,这种情况下,快排的时间复杂度就从 O(nlogn) 退化成了 O(n2)。
最佳情况:T(n) = O(nlogn)。
最差情况:T(n) = O(n2)。
平均情况:T(n) = O(nlogn)。
动画
解答开篇问题
快排和归并用的都是分治思想,递推公式和递归代码也非常相似,那它们的区别在哪里呢 ?
可以发现:
由下而上的,先处理子问题,然后再合并。由上而下的,先分区,然后再处理子问题。4. 希尔排序(Shell Sort)
思想
过程
实现
测试
分析
第一,希尔排序是原地排序算法吗 ?
希尔排序过程中,只涉及相邻数据的交换操作,只需要常量级的临时空间,空间复杂度为 O(1) 。所以,希尔排序是
原地排序算法。第二,希尔排序是稳定的排序算法吗 ?
我们知道,单次直接插入排序是稳定的,它不会改变相同元素之间的相对顺序,但在多次不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,可能导致相同元素相对顺序发生变化。
因此,希尔排序
不稳定。第三,希尔排序的时间复杂度是多少 ?
最佳情况:T(n) = O(n logn)。
最差情况:T(n) = O(n (log(n))2)。
平均情况:T(n) = 取决于间隙序列。
动画
5. 堆排序(Heap Sort)
堆的定义
堆其实是一种特殊的树。只要满足这两点,它就是一个堆。
完全二叉树:除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列。
也可以说:堆中每个节点的值都大于等于(或者小于等于)其左右子节点的值。这两种表述是等价的。
对于每个节点的值都
大于等于子树中每个节点值的堆,我们叫作大顶堆。对于每个节点的值都
小于等于子树中每个节点值的堆,我们叫作小顶堆。其中图 1 和 图 2 是大顶堆,图 3 是小顶堆,图 4 不是堆。除此之外,从图中还可以看出来,对于同一组数据,我们可以构建多种不同形态的堆。
思想
实现
测试
分析
第一,堆排序是原地排序算法吗 ?
整个堆排序的过程,都只需要极个别临时存储空间,所以堆排序是原地排序算法。
第二,堆排序是稳定的排序算法吗 ?
因为在排序的过程,存在将堆的最后一个节点跟堆顶节点互换的操作,所以就有可能改变值相同数据的原始相对顺序。
所以,堆排序是
不稳定的排序算法。第三,堆排序的时间复杂度是多少 ?
堆排序包括建堆和排序两个操作,建堆过程的时间复杂度是 O(n),排序过程的时间复杂度是 O(nlogn),所以,堆排序整体的时间复杂度是 O(nlogn)。
最佳情况:T(n) = O(nlogn)。
最差情况:T(n) = O(nlogn)。
平均情况:T(n) = O(nlogn)。
动画
6. 排序算法的复杂性对比
复杂性对比
算法可视化工具
算法可视化工具 algorithm-visualizer 是一个交互式的在线平台,可以从代码中可视化算法,还可以看到代码执行的过程。
效果如下图。
旨在通过交互式可视化的执行来揭示算法背后的机制。
算法可视化来源 https://visualgo.net/en
效果如下图。
https://www.ee.ryerson.ca
变量和操作的可视化表示增强了控制流和实际源代码。您可以快速前进和后退执行,以密切观察算法的工作方式。
7. 文章输出计划
JavaScript 数据结构与算法之美 的系列文章,坚持 3 - 7 天左右更新一篇,暂定计划如下表。
8. 最后
文中所有的代码及测试事例都已经放到我的 GitHub 上了。
觉得有用 ?喜欢就收藏,顺便点个赞吧。
参考文章:
The text was updated successfully, but these errors were encountered: