The Research Environment for Ancient Documents (READ) is a software system supporting the scholarly study of ancient texts on their physical carriers. It provides facilities for linking images of an inscribed object with transcriptions, for handling multiple transcriptions of the same object in parallel, for linking original-language texts with translations, and for producing glossaries and paleographic charts. The initial focus of READ development has been on supporting documents in South Asian writing systems, but the software is intended to be general and useable for documents from any part of the ancient world. READ can be used offline on a scholar’s personal computer, or it can be installed on a server in a multi‐user setup. It uses PostgreSQL for storage, HTML/PHP/JavaScript for display and interaction and TEI P5 XML for export and import, allowing for integration of READ with existing TEI-based workflows.
READ is being developed by a core team consisting of Stefan Baums (Munich, academic lead), Andrew Glass (Seattle, system design), Ian McCrabb (Sydney, project management) and Stephen White (Venice, programming). Other contributors include Arlo Griffiths, Yang Li and Andrea Schlosser. READ development has received generous funding from the Bavarian Academy of Sciences and Humanities, the University of Lausanne, the University of Washington, the Prakaś Foundation, the École française d’Extrême‐Orient and the University of Sydney. READ is open‐source software under the terms of the GNU General Public License version 3.
The current READ development team was formed in 2013, but the defining features of the READ software system go back much further:
-
Multi-user management: This is a long-standing feature of the specialised software written by Andrew Glass for the website Gandhari.org since about 2006, which served as inspiration for the general-purpose READ software system.
-
Linked multiple historical editions: This grew out of the work of Stefan Baums on the Gandhāran reliquary inscriptions since 2006 (published in Baums 2012 and kept updated as part of the Gandhari.org corpus). Many of these inscriptions had seen multiple divergent interpretations by different scholars, and it seemed important to be able to record these. Andrew Glass suggested a data model of “cubed” editions to formally capture their relationships.
-
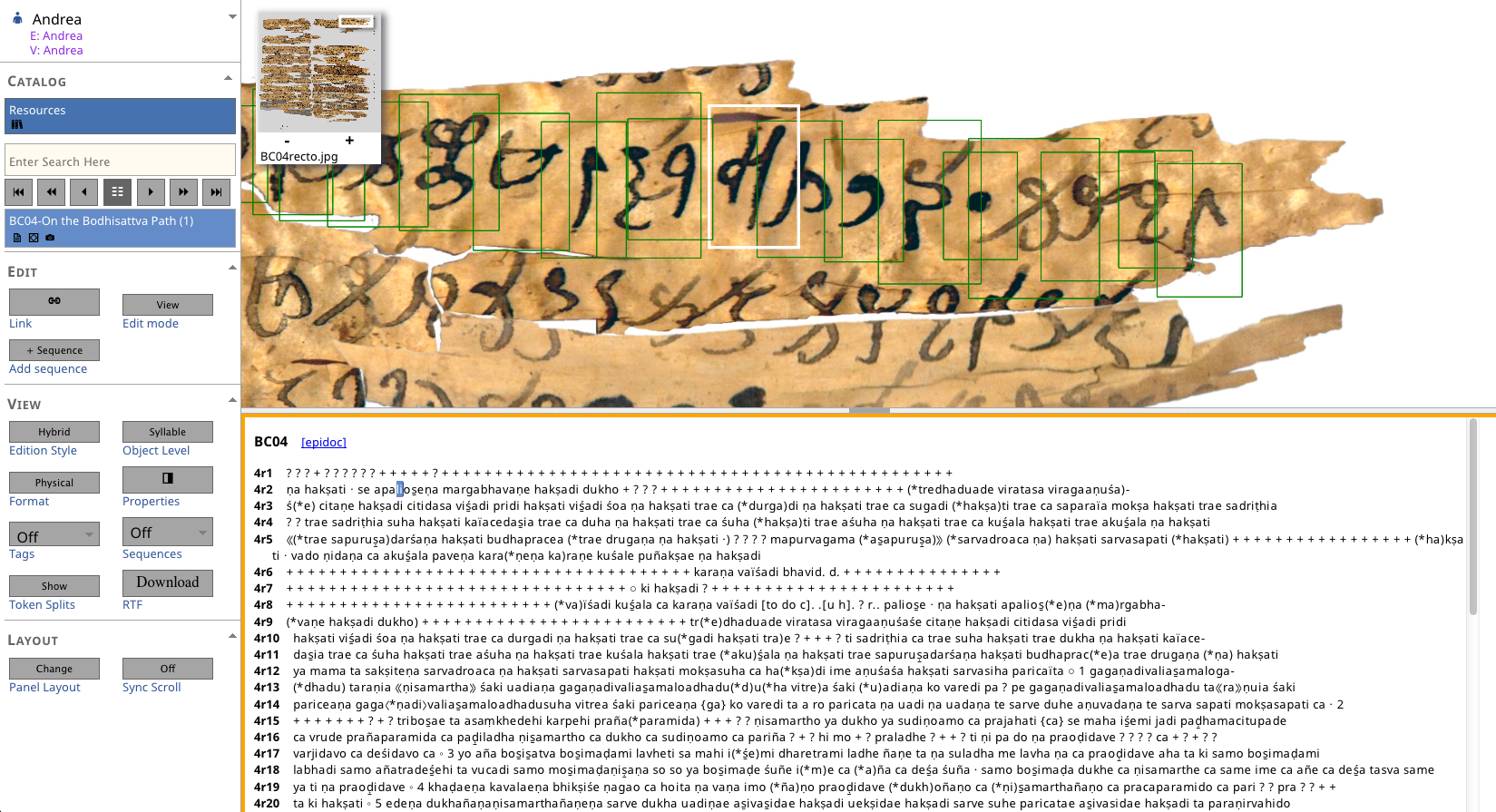
Text-image linking: This is a standard feature available in many software systems designed for documentary editing. In the context of Gandhari.org, Stefan Baums and Andrew Glass had long experimented with a range of different solutions for efficient presentation of large images (including tiling solutions that are not currently offered by READ). Linking offers a number of additional advantages, such as an explicit record of which visual element is read how and synchronized scrolling of image and text.
-
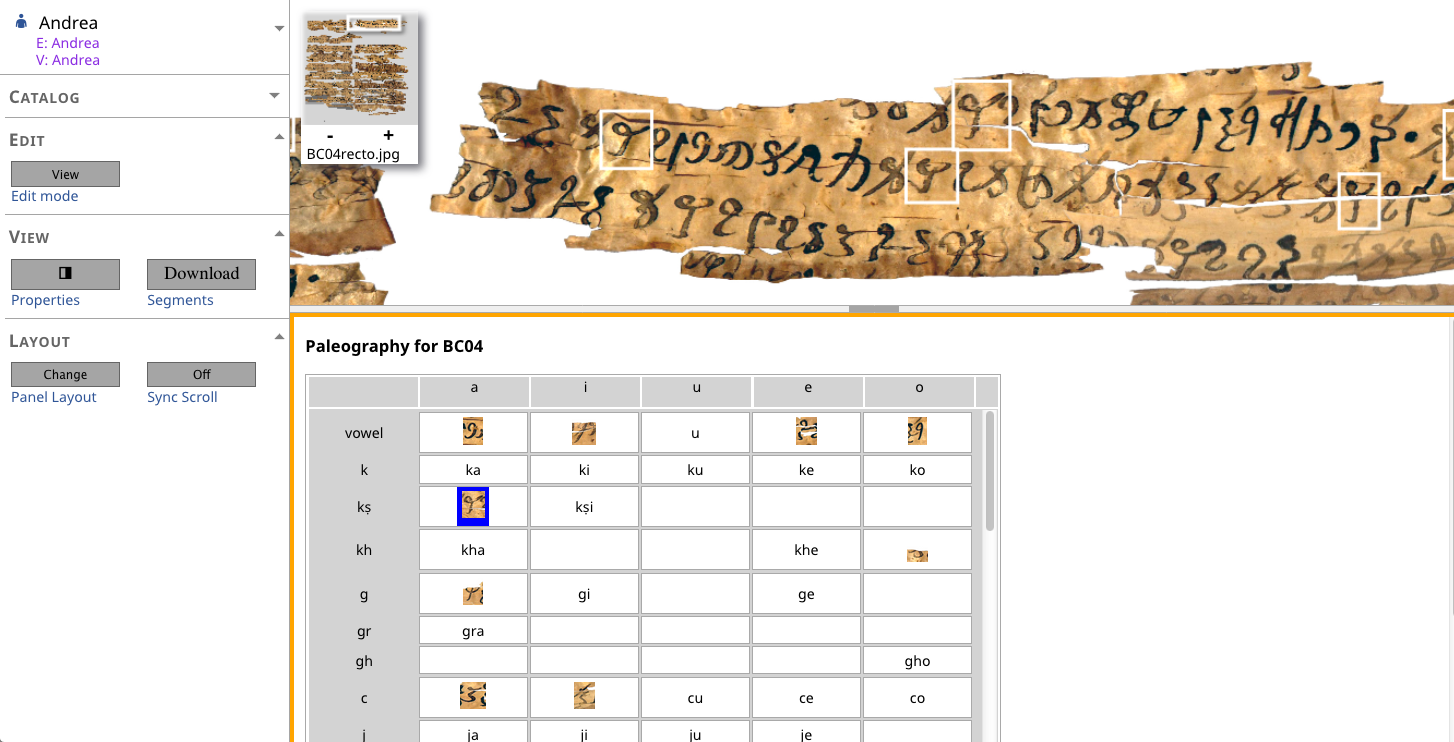
Semi-automatic paleographic tables: This idea was first introduced by Stefan Baums in the 2010 application for the Buddhist Manuscripts from Gandhāra project at the Bavarian Academy of Sciences and Humanities. It is a natural side benefit of text-image linking when applied to the basic units of interest in paleography (such as letters, akṣaras or logograms).
-
Atomization and linking of entities: The idea to base READ on a model of atomized entities given properties and linked to each other (as opposed to a top-down tree data model as in TEI) arose in discussion between Andrew Glass and Stephen White. Glass had followed a similar approach (on the basis of a spreadsheet) in his 2006 Ph.D. dissertation.
-
TEI export: The importance of TEI support for compatibility with other software packages and projects was apparent well before the conception of READ. First attempts to add TEI export to Gandhari.org were made by Stefan Baums and Donald Craig in 2009–10, and TEI support was a central feature in the 2010 Buddhist Manuscripts from Gandhāra application. On the background of the atomized internal data model of READ, TEI support has taken the form of an export format (with planned import and roundtripping).
The acronym ‘READ’ for ‘Research Environment for Ancient Documents’ was suggested by Stefan Baums in August 2013, in order to emphasize the wide range of possible applications of this software system outside the field of South Asian manuscript studies and epigraphy that was its first target. The name ‘READ’ has the advantage of being easy to remember, and the disadvantage of being hard to find in a web search engine. We recommend that when discussing this software, it is always first introduced as ‘Research Environment for Ancient Documents (READ)’ before referring to it simply as ‘READ’ later in a text.
From 2013 until 2016, basic development of READ was funded by coordination between the Bavarian Academy of Sciences and Humanities, the University of Lausanne, the University of Washington and the Prakaś Foundation. After basic development reached completion, the code was released online in March 2017. Development continues as an open-source project, with primary funding from the Bavarian Academy of Sciences and Humanities. Other contributions of work, ideas or funding are always welcome.
The following screenshots (courtesy of Andrea Schlosser) illustrate some of the functionality of READ.
Linking images to texts:
Linking texts to translations:

Creating glossaries for texts:

Creating paleographic tables: