Dictionary以及HashTable #4
Description
字典
字典是一种无序且唯一的数据结构,但是它是以键值对的形式存储数据的,字典的接口定义如下
// 键值对
class KeyValuePairs<K, V> {
constructor(public key: K, public value: V) {}
toString(): string {
return `[#${this.key}: ${this.value}]`;
}
}
// 字典数据结构定义
interface Map<K, V> {
hasKey(key: K): boolean;
set?(key: K, value: V): boolean;
put?(key: K, value: V): boolean;
hashCode?(key: K): number;
remove(key: K): boolean;
get(key: K): V | undefined;
keyValues(): KeyValuePairs<K, V>[];
keys(): K[];
values(): V[];
forEach(callbackFn: (key: K, value: V) => any): void;
size(): number;
isEmpty(): boolean;
clear(): void;
toString(): string;
}ArrayDictionary
存储数据结构最简单的方式我们可以使用线性排列的方式即线性表来存储,但是如果想根据某一个key查找到value需要遍历所有的元素,时间复杂度O(n),当然如果通过二分查找的方式时间复杂度可以降低为O(log n)
最好的方式是用空间换时间,使用HashTable来实现字典,可以将查找的时间复杂度优化到O(1),JavaScript Object本身就是使用HashTable实现的。
HashTable
Hashtable又叫哈希表,散列表,因为JS对象内部实现本身也是HashTable,并且HashTable查找的时间复杂度是O(1),所以大部分字典的数据结构都是hashtable。
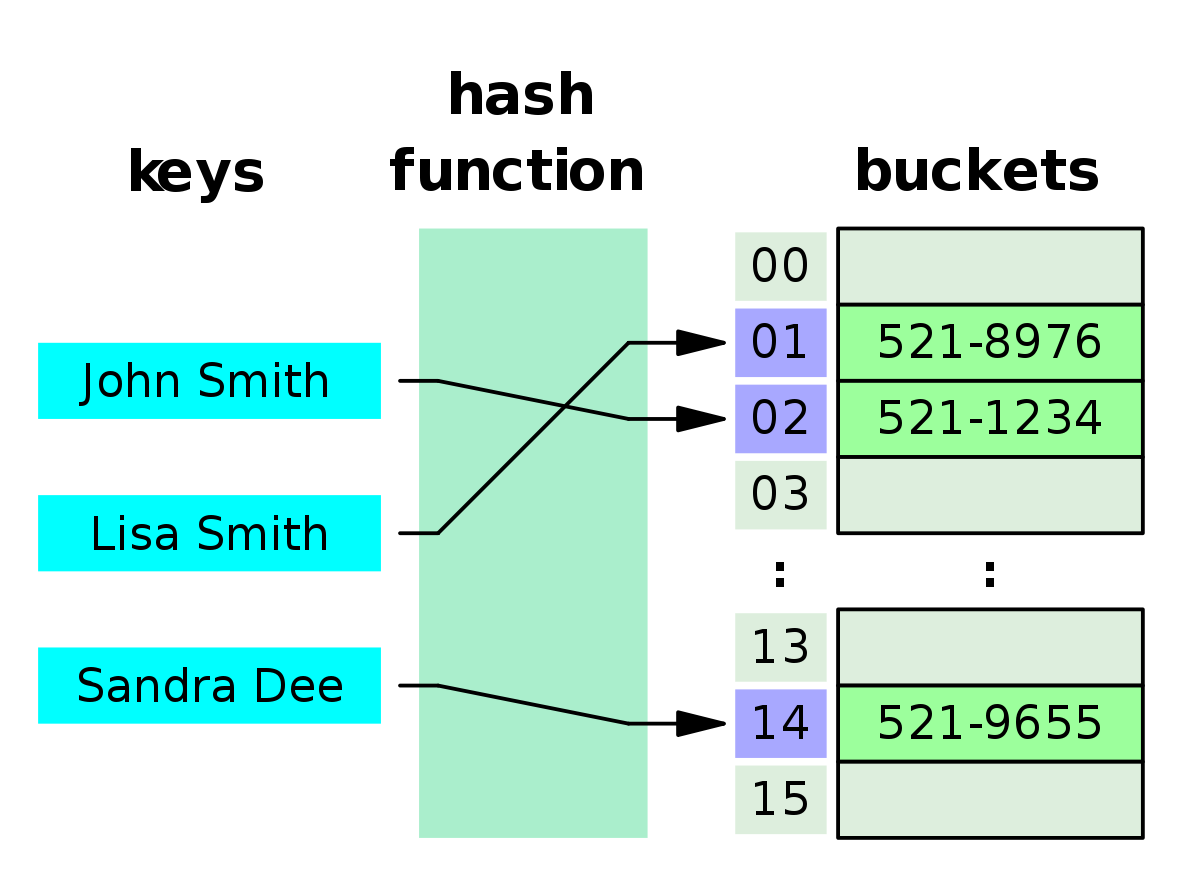
哈希表的核心是哈希函数(hash function),它可以接收key作为参数(一般是字符串),然后返回一个数字(index),然后根据index找到对应的哈系桶(bucket),bucket 里存储了一个或多个 value,需要主要的是不同的key可能得到相同的index,所以bucket中存储了多个元素
实现哈希函数的最简单的方式就是loss loss 散列函数
// loselose实现哈希函数
loseloseHashCode(key: K): number {
let Hash = 0;
for(let i = 0; i < key.length; i++) {
// aharCodeAt 会回传置顶字符串的Unicode编码,所以可以包含中文
Hash += key.charCodeAt(i);
}
// 为了取到较小值,使用人数数复发mod处理最多存放 36 个元素
console.log(Hash)
return Hash % 37;
}但是不同的键值可能有一样的hash值,例如Jamie 和 Sue 两个字符串获得的 hash 值就会相同, 使用 djb2 散列函数比 lose lose 散列函数发生的冲突要低很多,这是一个表现良好的散列函数,事件证明位左移5是比较好的选择(具体原因不清楚)
djb2HashCode(key: string){ // 获取随机hash值
let Hash = 5381; // 不一定要是5381,只要大一点的质数都可以
for(let i = 0; i < key.length; i++) {
// hash << 5) + hash = hash * 33
hash = hash * 33 + key.charCodeAt(i);
}
// 大概的数组的大小1000
return hash % 1013; // hash 对 1013 取模
}在实现hashTable, 因为hash函数产生的index不是连续的导致数组可能有空洞,遍历性能稍差,一直想着要使用对象,但是对象不是基础的数据结构,对象的实现又何尝不是hashTable,细想底层逻辑其实使用对象性能更差
解决hash冲突
- 分离链接法
分离链表就是buckest中存储的是链表结构,这样不同的元素就可以有相同的index了
- 线性探查法
线性探索就是如果index已经存在元素,那么就向下移动一位直到找到可用的数组下标