webpluck scrapes a specific values from a web page. It works as a
standalone binary as well as in a API mode.
webpluck is available for 64 bit linux, OS X and Windows systems.
Latest versions can be downloaded from the
Release tab above. This is the preferred way.
This is a golang project. Assuming you have golang compiler installed, the following will build the binary from scratch
$ git clone https://github.com/codeexpress/webpluck
$ cd webpluck
$ go build -o webpluck cmd/main.go
webpluck takes the following input:
- URL of the webpage
- XPATH of the element
- optional regex to further narrow the selection
and outputs the selected value.
This is the link of the webpage which has the desired information we want to extract.
For example, if we want to scrape the founders of the StackOverflow website from its company page, the URL is: https://stackoverflow.com/company. The desired value we want to extract is: Joel Spolsky and Jeff Atwood

This is the link of the xpath of the element on the page that contains the required information. A good way to get this information is to (on a chrome browser):
- Right click on the place were the information is present
- Click "Inspect" to open the Chrome developer tools window with the element highligted
- On the highlighed value in the HTML source code,
Right click -> Copy -> Copy xpath - The copied value is the xpath we need
| Get xpath Step 1 | Get xpath Step 2 |
|---|---|
 |
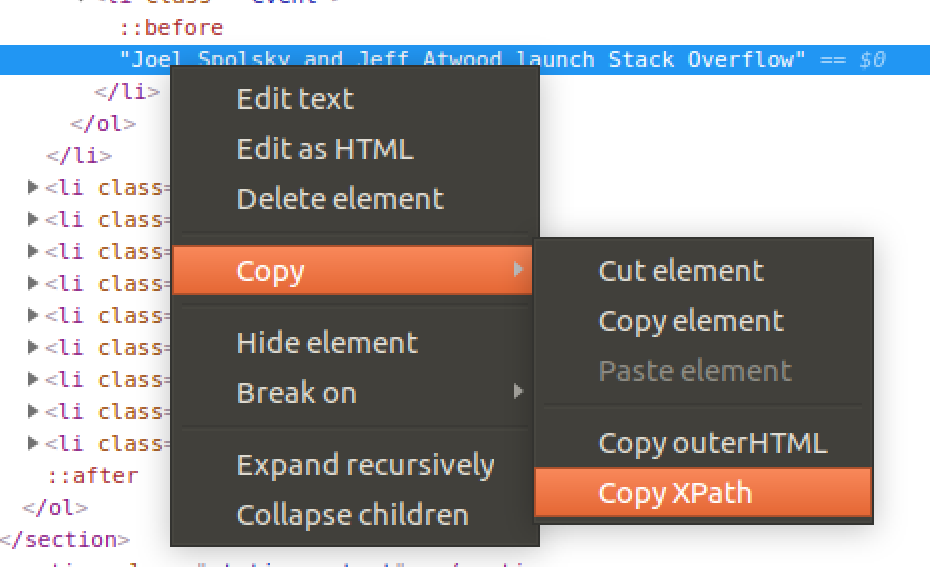 |
The xpath in example above comes out to be: //*[@id="content"]/section[3]/ol/li[1]/ol/li[2]/text()
Note the the xpath above leads us to the value: Joel Spolsky and Jeff Atwood launch Stack Overflow
Since we want to trim that down further, we'll provide a regex value to extract just the names.
This regex will fetch just the names (the value in parenthesis):
^(*.) launch .*
webpluck can be run as a standalone binary. To extract the names using the three params we just obtained, copy the targets.yml file and populate it with the parameters. The resulting targets.yml should look like this:
targetList:
- name: stackoverflow_founders
baseUrl: https://stackoverflow.com/company
xpath: //*[@id="content"]/section[3]/ol/li[1]/ol/li[2]/text()
regex: ^(.*) launch .*Now invoke webpluck as follows and obtain the answer:
$ ./webpluck_osx -f /path/to/targets.yml
{
"stackoverflow_founders": "Joel Spolsky and Jeff Atwood"
}webpluck can be run in server mode as well. Thereafter, clients written in other programming languages can scrape web pages using the webpluck API over the network.
To run webpluck in server mode listening on localhost on 8080:
$ ./webpluck -p 8080An instance of webpluck API is running at https://api.code.express/webpluck/. You can use that for your light extraction needs. If your load is heavy, consider spinning your own server running webpluck
Armed with the knowledge of baseUrl, xpath and regex, we can now call the API endpoint by POSTing these three params:
Example curl invocation for the server mode:
curl 'https://api.code.express/webpluck/' \
--data-urlencode 'baseUrl=https://stackoverflow.com/company' \
--data-urlencode 'xpath=//*[@id="content"]/section[3]/ol/li[1]/ol/li[2]/text()' \
--data-urlencode 'regex=^(.*) launch .*' -gThe result from the API is as follows. The pluckedData field returns the value extracted:
{
"baseUrl": "https://stackoverflow.com/company",
"pluckedData": "Joel Spolsky and Jeff Atwood",
"regex": "^(.*) launch .*",
"xpath": "//*[@id=\"content\"]/section[3]/ol/li[1]/ol/li[2]/text()"
}