The New Turing Omnibus Chapter 35 Sequential Sorting

We welcomed new members and enjoyed an unusually large glut of snacks on offer thanks to the collective generosity of attendees.
We began the chapter by discussing our mutual confusion over the opening paragraphs' discussion of merge sort's computational complexity (O(n log n)) and the meaning of the following sentence:
It turns out that this quantity has also the right order of magnitude as a lower bound on the number of steps required.
We convinced ourselves that the chapter was explaining that a sequential sort algorithm with a complexity of O(n log n) (such as merge sort) must perform at least O(n log n) in its worst case (e.g. given the worst possible initial order for the algorithm).
This lead to a brief recapping of computational complexity and Big O notation with us graphing the common complexities found when analysing algorithms:
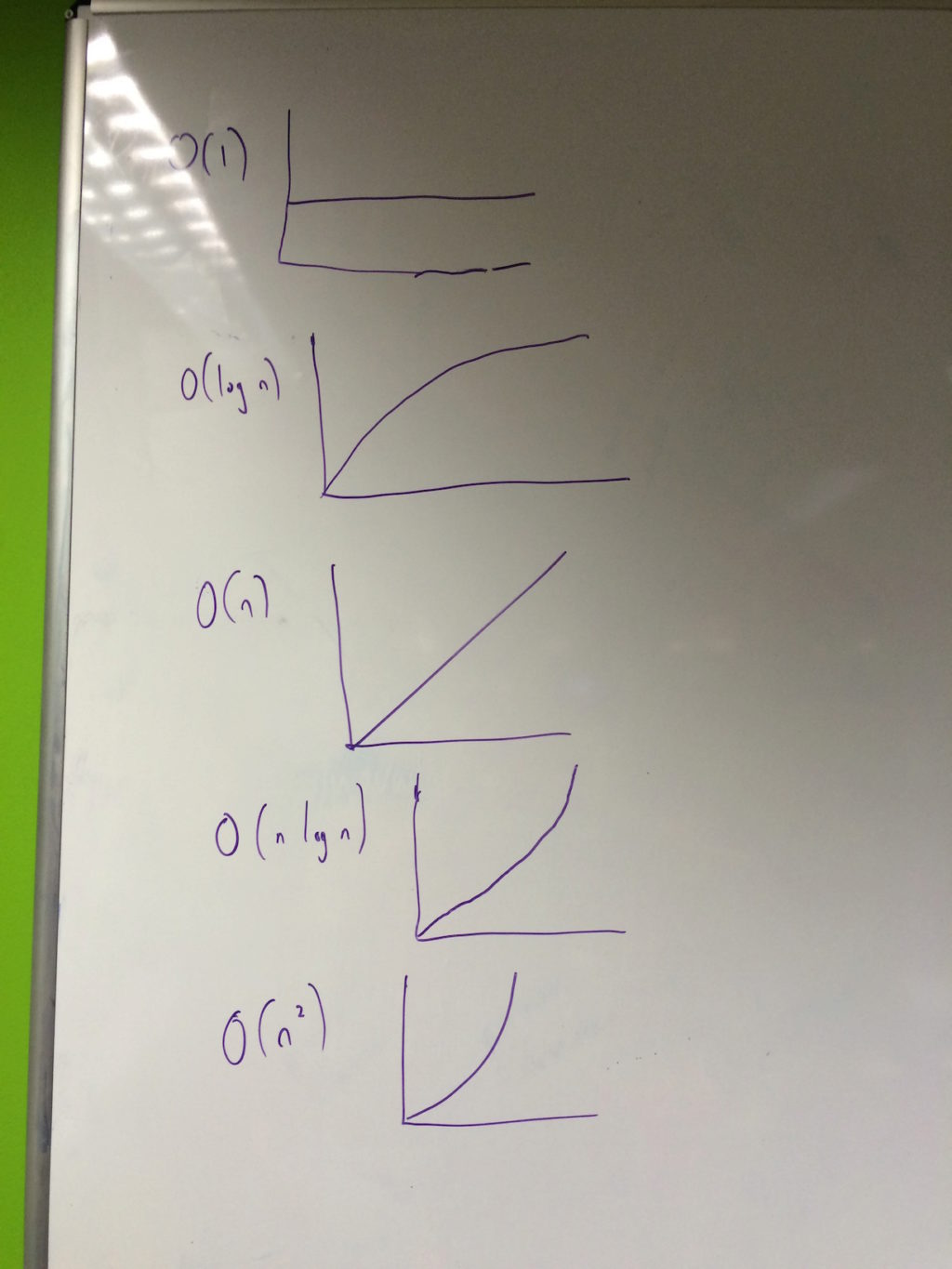
O(1)O(log n)O(n)O(n log n)O(n^2)
We discussed whether the complexity of an algorithm changed if it is designed to be parallelised (such as divide and conquer algorithms) but had no concrete answer. The extreme example being a parallel map function over a list of n elements when run on a machine with n cores: would this effectively be O(1) (as all elements of the list can have the function applied simultaneously)?
We then turned to the decision trees given in the book and tried to work through a concrete example to understand what they visualised:

We used the above tree to walk through sorting a three element list and briefly discussed the significance of stability when sorting elements.

As our decision tree had a different shape to the one given in the book, we wondered whether that was significant but as the number of nodes and terminal nodes was the same, reasoned that this was due to our specific choice of sorting algorithm. We were satisfied that, had we made another choice, any other tree we produced would still maintain the same number of nodes.
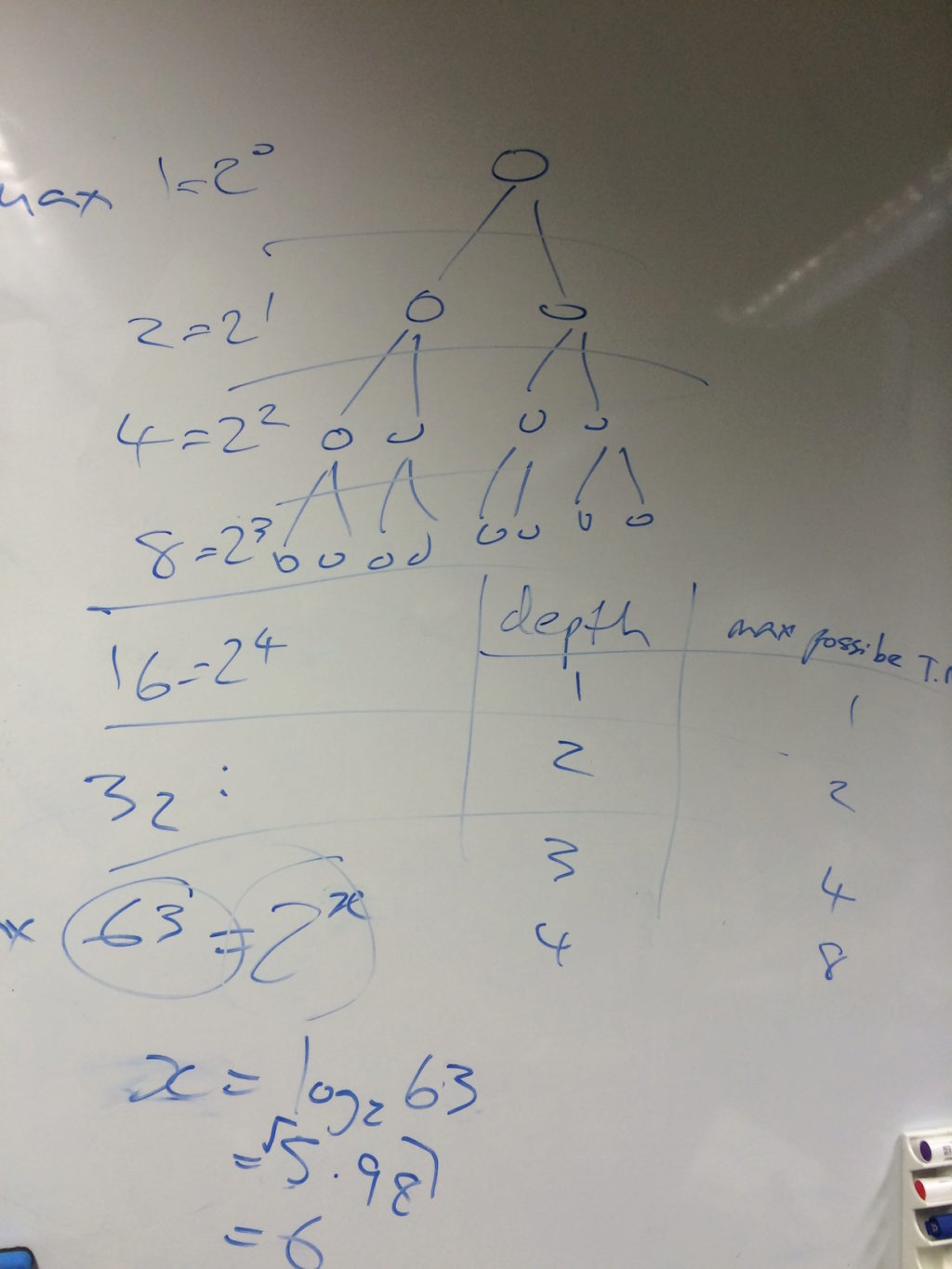
With this complete, we could now turn to the crux of the chapter: the algebra that takes the depth of the tree D (representing the number of comparisons a sequential sort must execute) and shows how it is at least O(n log n).
We first recapped why the depth of a binary tree is log n! (using some of our previous exploration of search trees) and then worked through each step, expanding it in more detail than given in the chapter:
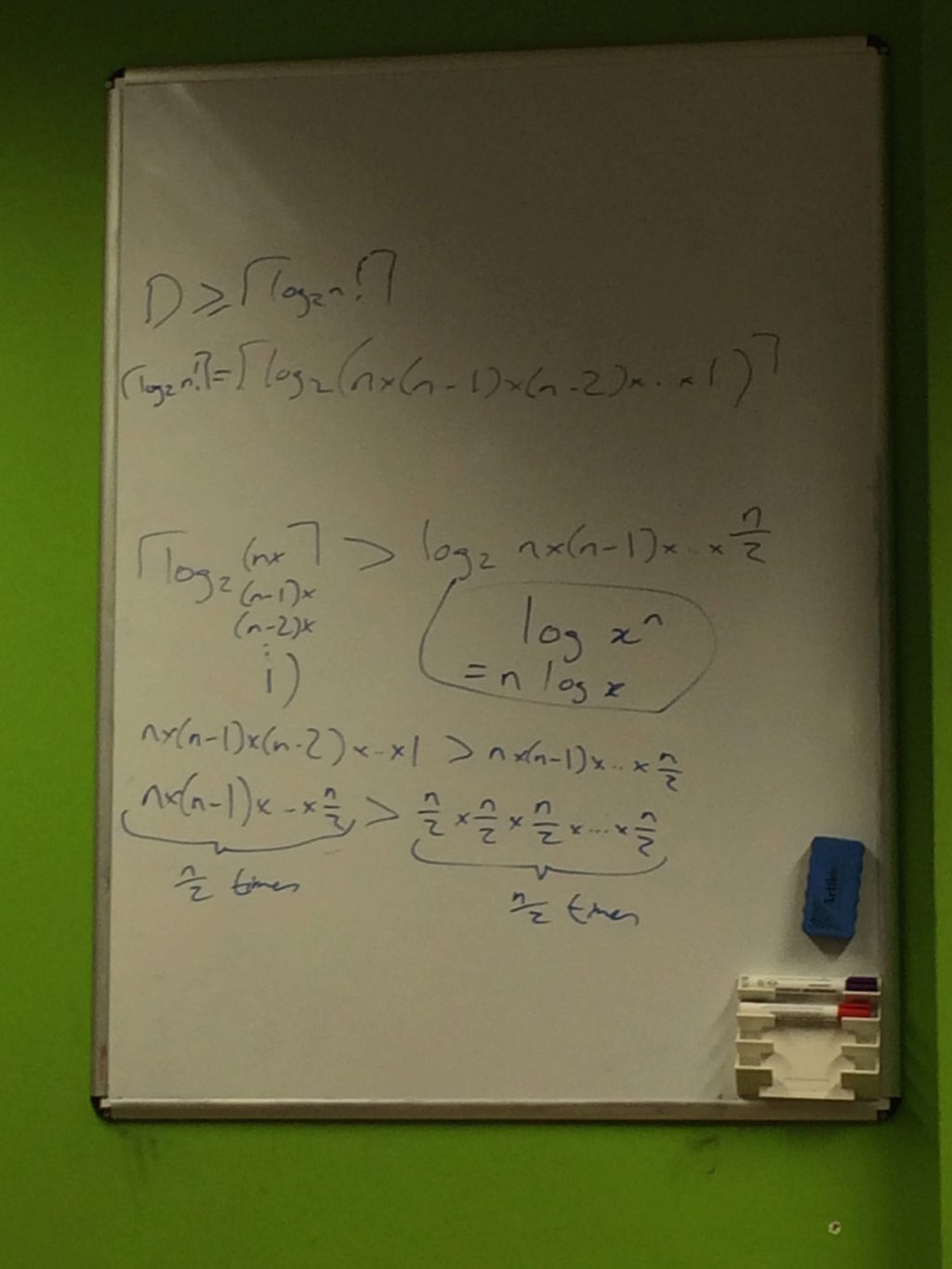
We were initially confused as to why log n! was expanded to log n(n - 1)(n - 2)...n/2 rather than log n(n - 1)(n - 2)...1 and also why it was then expanded to only n/2 terms but we accepted that this was necessary to show a symmetry with the O(n log n) complexity of algorithms such merge sort and that the result held because it proved the least number of comparisons in the worst case.
Throughout, we were repeatedly stumped by notions of "upper bound", "lower bound", "worst case", "at most", "at least" and all combinations thereof. For example, we knew that quicksort actually has O(n^2) complexity in the worst case but the chapter only stated that it must perform at least n log n operations so therefore it still holds.
There was some agreement that the chapter would have benefited from going into more detail as its brevity made it rather dense.
We took some time at the end of the meeting to discuss how it had gone and what changes we might want to make in future:
-
Our technique of slowly progressing through the chapter, always stopping to discuss in detail when we reached something we didn't understand might be unnecessarily slowing us down. In this chapter specifically, we dwelled on questions that were later answered in the text. We discussed whether passing over the chapter twice would help but actually thought that we might benefit from a particular attendee walking us through the chapter;
-
There had been concerns on Slack and at Computation Pub about our method of choosing chapters to read: by voting only for sections and not specific chapters, perhaps we weren't getting the most value of this particular book (given its breadth of subject matter). We decided to ditch the section-based voting and instead invite people to pitch chapters they wish to read and then vote on those (c.f. Call For Proposals).
To end the meeting, Chris Patuzzo demonstrated his amazing progress on the self-enumerating pangram problem.
This pangram is dedicated to the London Computation Club and it contains exactly nine a's, two b's, six c's, seven d's, thirty-five e's, eight f's, three g's, nine h's, twenty i's, one j, one k, four l's, three m's, twenty-nine n's, fifteen o's, three p's, one q, nine r's, thirty-one s's, twenty six t's, five u's, seven v's, five w's, four x's, seven y's and one z.
In summary, Chris has been working on this problem for a long time and has succeeded in building something that can find self-enumerating pangrams in just a few minutes. His approach uses a technique called Reduction from Computer Science to reduce the problem of finding a self-enumerating pangram into a different problem - the Boolean Satisfiability Problem. He then feeds this huge boolean equation to a SAT solver which attempts to find a solution.
He wrote a bespoke Hardware Description Language as a stepping stone to achieve this goal. Rather than going directly to SAT, he first described the problem as a chip and used learnings from the nand2tetris book to test-drive this and ensure it captured the constraints of the problem correctly. This chip consists of lookup tables (for the english number words), adders and a mixture of other things.
This chip takes a total of 312 inputs and produces a single output - whether the inputs correspond to a true self-enumerating pangram, or not. Once he'd built this chip - he then made use of something called the Tseitin Transformation to reduce the schematic for this chip into SAT.
He's now moved onto an even harder problem, which as far as we know, has never been solved. It's in the form:
To within two decimal places, five point seven six percent of the letters in this sentence are a's, six point eight two percent are b's, four point three eight percent are c's, two point one percent are d's, three percent are e's, four point seven nine percent are f's, ...
The percentages quoted above are made up at random with no attempt at accuracy. The implied challenge is to replace them with values that make the sentence true. For more information about this, speak to Chris - he's more than happy to tell the story. He's also thinking of writing this up and possibly producing a technical paper to explain more rigorously what he's done.
Thanks to Leo & Geckoboard for hosting, for everyone's kind snack contributions and to Chris for sharing his pangrammatical efforts.