4 questions regarding the structure of LSTM_autoencoder #1
Description
Hello, Mr. Ranjan. Thanks for your great article LSTM Autoencoder for Extreme Rare Event Classification in Keras and code on the github. While reading your code, however, I came up with 3 questions.
I decided to ask you questions here rather than on medium because I can upload pictures and quote codes more accurately here. Hope you are okay with this.
Q1. Why ‘return_sequences=True’ for all the LSTM layers?
Back up explanations
- I think LSTM autoencoder is very similar to seq2seq model : In Autoencdoer , input data is squeezed into a single latent vector with smaller length than the original input. In seq2seq model the same thing happens with an input sequence and a fixed-length vector.

< Figure 1. seq2seq model : Encoding - Decoding model >
-
In the encoding stage, what a model needs to do is making a fixed-length vector(a latent vector) which contains all the information and time-wise relationships of the input sequence. In decoding step, a model’s goal is to create an output that is as close as possible to the original input.
-
So my guess is that in the encoding stage, we do not need outputs as in the figure 1, as the autoencoder model's only goal is to make a hidden latent vector well. The little MSE the output created from the latent vector in the decoding stage has with the input data, the better the latent vector is.
-
Doesn’t it mean that we can make ‘return_sequences = False’, which does not print out the outputs in the encoding stage?
Q2. What would be the first hidden state (h0, c0) for the decoding stage?
Back up explanations
- According to the code, the hidden latent vector is repeated for
timestepsas inlstm_autoencoder.add(RepeatVector(timesteps))This means that the latent vector would be fed to the decoder as an input in the decoding stage. Below is the code snippet.
lstm_autoencoder = Sequential()
# Encoder
lstm_autoencoder.add(LSTM(timesteps, activation='relu', input_shape=(timesteps, n_features), return_sequences=True))
lstm_autoencoder.add(LSTM(16, activation='relu', return_sequences=True))
lstm_autoencoder.add(LSTM(1, activation='relu'))
lstm_autoencoder.add(RepeatVector(timesteps))
# Decoder
lstm_autoencoder.add(LSTM(timesteps, activation='relu', return_sequences=True))
lstm_autoencoder.add(LSTM(16, activation='relu', return_sequences=True))
lstm_autoencoder.add(TimeDistributed(Dense(n_features)))
-
If latent vectors are used as inputs in the decoding stage, what would be used for inital hidden state (h0, c0) ? In the seq2seq model (figure 1) mentioned above, the latent vector is used as initial hidden state (h0, c0) in the decoding stage. The input in the decoding stage would be a sentence that needs to be translated, for example from English to French.
-
So I am curious to know what would be used as an initial hidden state cell (h0, c0) in your code!
Q3. Why output unit size increases from 5 to 16, in the encoding stage?
Back up explanations
- From the
lstm_autoencoder.summary()we can see that the output unit increases from 5 (in the layer 'lstm_16') to 16 (in the layer 'lstm_17' )
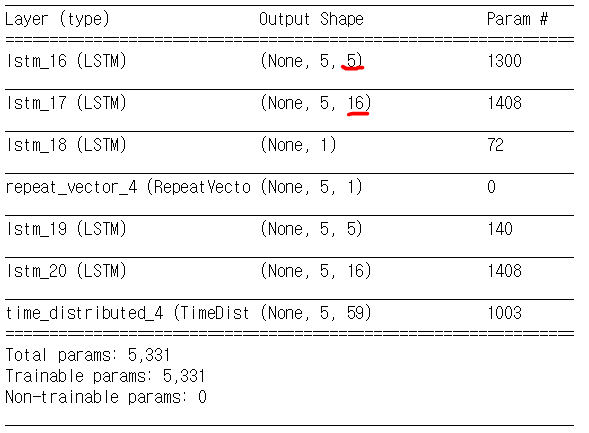
< Figure 2. summary of LSTM - Autoencoder model >
-
Since the output of previous LSTM layer is an input for the next LSTM layer, I think the output size is equivalent to hidden state size.
-
If the hidden layer's size is greater than the number of inputs, the model can learn just an 'identity function' which is not desirable. (Source : [What is the intuition behind the sparsity parameter in sparse autoencoders?])(https://stats.stackexchange.com/questions/149478/what-is-the-intuition-behind-the-sparsity-parameter-in-sparse-autoencoders)
-
Layer 'lstm_16' is only 5-size long while the next layer 'lstm_17' is 16-size long. So I think the lstm_17 would just copy (acting like an 'identity matrix') the last_16, which makes the layer lstm_17 undesirable.
-
I am curious to know why the output size (hidden_layer size) increases rather than decreases!
Q4. How smaller does the input data size get reduced in the latent vector?
Back up explanations
- In the full-connected layer Autoencoder, we can see how smaller the input vector get reduced. For example in the picture below, 10 node-long vector input gets reduced to 4 node-long latent vector in the middle.
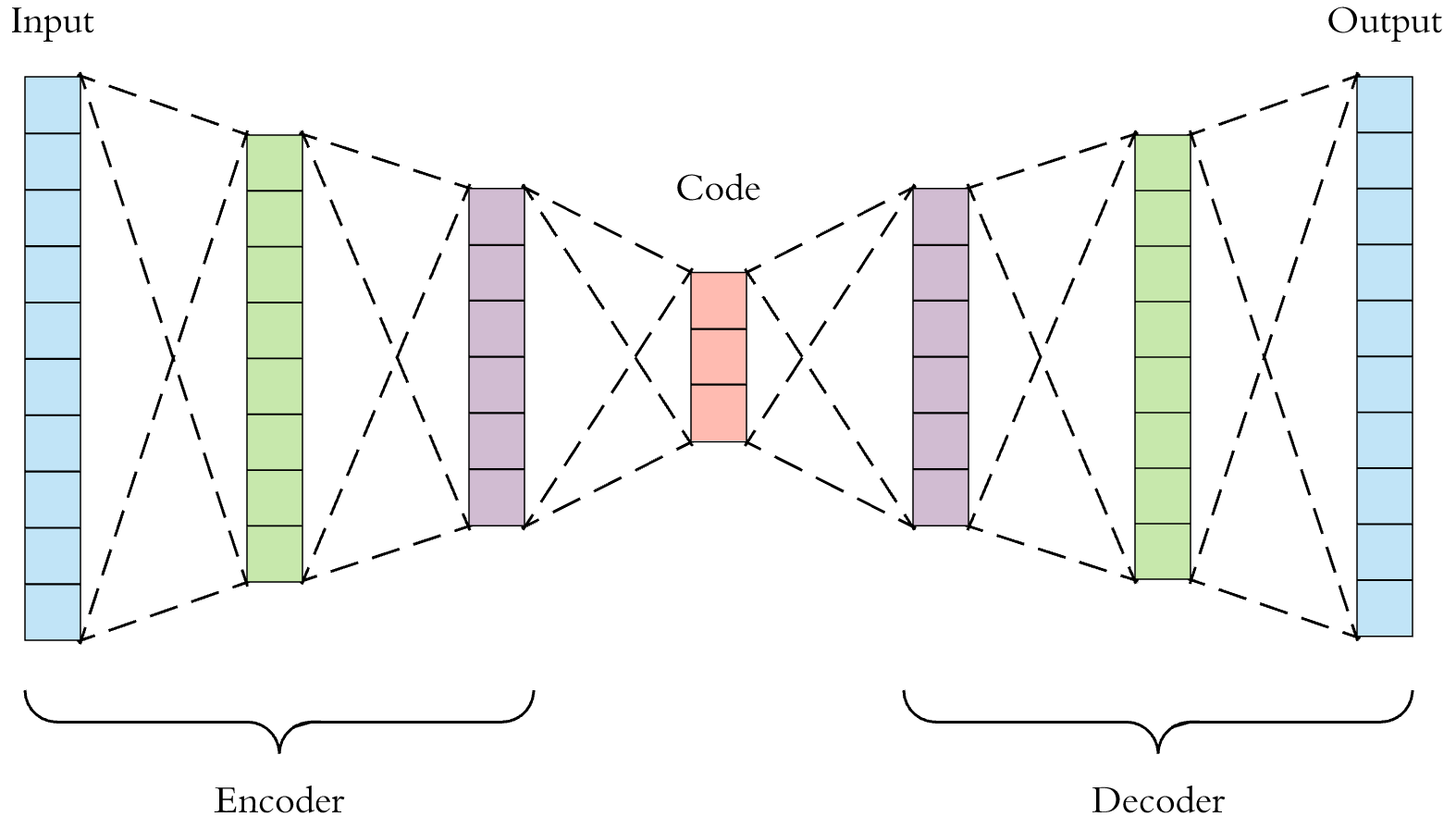
- In your code, how smaller did the 59 node long input vector (one input of a certain time. It has 59 features and 1 answer label) get reduced in the latent vector?
Thanks for this nice post again.