

![]()
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust
with extreme
flexibility, compute efficiency and portability as its primary goals.

Because we believe the goal of a deep learning framework is to convert computation into useful intelligence, we have made performance a core pillar of Burn. We strive to achieve top efficiency by leveraging multiple optimization techniques described below.
Click on each section for more details 👇
Automatic kernel fusion 💥
Using Burn means having your models optimized on any backend. When possible, we provide a way to automatically and dynamically create custom kernels that minimize data relocation between different memory spaces, extremely useful when moving memory is the bottleneck.
As an example, you could write your own GELU activation function with the high level tensor api (see Rust code snippet below).
fn gelu_custom<B: Backend, const D: usize>(x: Tensor<B, D>) -> Tensor<B, D> {
let x = x.clone() * ((x / SQRT_2).erf() + 1);
x / 2
}Then, at runtime, a custom low-level kernel will be automatically created for your specific implementation and will rival a handcrafted GPU implementation. The kernel consists of about 60 lines of WGSL WebGPU Shading Language, an extremely verbose lower level shader language you probably don't want to program your deep learning models in!
As of now, our fusion strategy is only implemented for our own WGPU backend and supports only a subset of operations. We plan to add more operations very soon and extend this technique to other future in-house backends.
Asynchronous execution ❤️🔥
For backends developed from scratch by the Burn team, an asynchronous execution style is used, which allows to perform various optimizations, such as the previously mentioned automatic kernel fusion.
Asynchronous execution also ensures that the normal execution of the framework does not block the model computations, which implies that the framework overhead won't impact the speed of execution significantly. Conversely, the intense computations in the model do not interfere with the responsiveness of the framework. For more information about our asynchronous backends, see this blog post.
Thread-safe building blocks 🦞
Burn emphasizes thread safety by leveraging the ownership system of Rust. With Burn, each module is the owner of its weights. It is therefore possible to send a module to another thread for computing the gradients, then send the gradients to the main thread that can aggregate them, and voilà, you get multi-device training.
This is a very different approach from what PyTorch does, where backpropagation actually mutates the grad attribute of each tensor parameter. This is not a thread-safe operation and therefore requires lower level synchronization primitives, see distributed training for reference. Note that this is still very fast, but not compatible across different backends and quite hard to implement.
Intelligent memory management 🦀
One of the main roles of a deep learning framework is to reduce the amount of memory necessary to run models. The naive way of handling memory is that each tensor has its own memory space, which is allocated when the tensor is created then deallocated as the tensor gets out of scope. However, allocating and deallocating data is very costly, so a memory pool is often required to achieve good throughput. Burn offers an infrastructure that allows for easily creating and selecting memory management strategies for backends. For more details on memory management in Burn, see this blog post.
Another very important memory optimization of Burn is that we keep track of when a tensor can be mutated in-place just by using the ownership system well. Even though it is a rather small memory optimization on its own, it adds up considerably when training or running inference with larger models and contributes to reduce the memory usage even more. For more information, see this blog post about tensor handling.
Automatic kernel selection 🎯
A good deep learning framework should ensure that models run smoothly on all hardware. However, not all hardware share the same behavior in terms of execution speed. For instance, a matrix multiplication kernel can be launched with many different parameters, which are highly sensitive to the size of the matrices and the hardware. Using the wrong configuration could reduce the speed of execution by a large factor (10 times or even more in extreme cases), so choosing the right kernels becomes a priority.
With our home-made backends, we run benchmarks automatically and choose the best configuration for the current hardware and matrix sizes with a reasonable caching strategy.
This adds a small overhead by increasing the warmup execution time, but stabilizes quickly after a few forward and backward passes, saving lots of time in the long run. Note that this feature isn't mandatory, and can be disabled when cold starts are a priority over optimized throughput.
Hardware specific features 🔥
It is no secret that deep learning is mosly relying on matrix multiplication as its core operation, since this is how fully-connected neural networks are modeled.
More and more, hardware manufacturers optimize their chips specifically for matrix mutiliplication workloads. For instance, Nvidia has its Tensor Cores and today most cellphones have AI specialized chips. As of this moment, we support Tensor Cores with our LibTorch and Candle backends, but not other accelerators yet. We hope this issue gets resolved at some point to bring support to our WGPU backend.
Custom Backend Extension 🎒
Burn aims to be the most flexible deep learning framework. While it's crucial to maintain compatibility with a wide variety of backends, Burn also provides the ability to extend the functionalities of a backend implementation to suit your personal modeling requirements.
This versatility is advantageous in numerous ways, such as supporting custom operations like flash attention or manually writing your own kernel for a specific backend to enhance performance. See this section in the Burn Book 🔥 for more details.

The whole deep learning workflow is made easy with Burn, as you can monitor your training progress with an ergonomic dashboard, and run inference everywhere from embedded devices to large GPU clusters.
Burn was built from the ground up with training and inference in mind. It's also worth noting how Burn, in comparison to frameworks like PyTorch, simplifies the transition from training to deployment, eliminating the need for code changes.
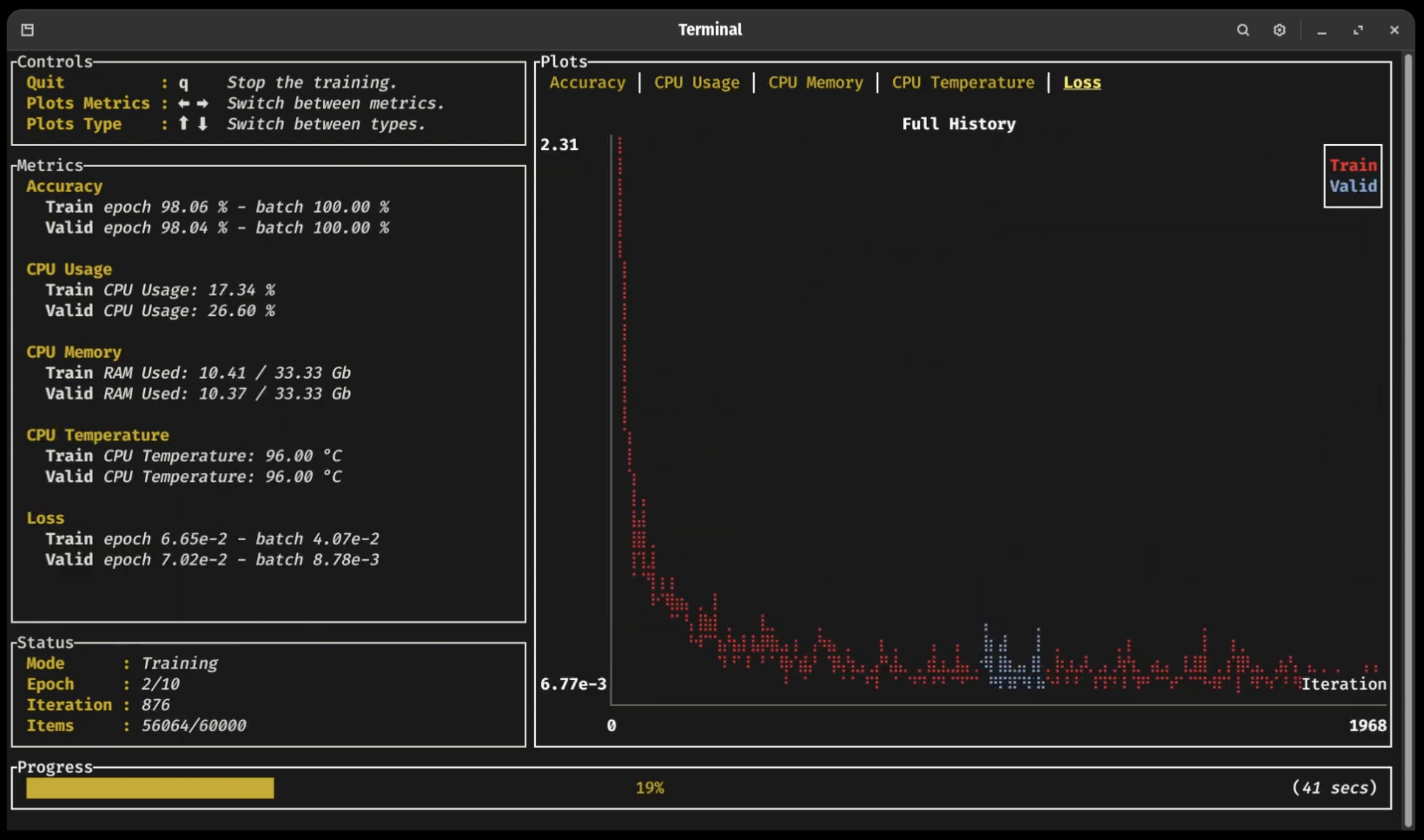
Click on the following sections to expand 👇
Training Dashboard 📈
As you can see in the previous video (click on the picture!), a new terminal UI dashboard based on the Ratatui crate allows users to follow their training with ease without having to connect to any external application.
You can visualize your training and validation metrics updating in real-time and analyze the lifelong progression or recent history of any registered metrics using only the arrow keys. Break from the training loop without crashing, allowing potential checkpoints to be fully written or important pieces of code to complete without interruption 🛡
ONNX Support 🐫
ONNX (Open Neural Network Exchange) is an open-standard format that exports both the architecture and the weights of a deep learning model.
Burn supports the importation of models that follow the ONNX standard so you can easily port a model you have written in another framework like TensorFlow or PyTorch to Burn to benefit from all the advantages our framework offers.
Our ONNX support is further described in this section of the Burn Book 🔥.
Note: This crate is in active development and currently supports a limited set of ONNX operators.
Importing PyTorch Models 🚚
Support for loading of PyTorch model weights into Burn’s native model architecture, ensuring seamless integration. See Burn Book 🔥 section on importing PyTorch
Inference in the Browser 🌐
Several of our backends can compile to Web Assembly: Candle and NdArray for CPU, and WGPU for GPU. This means that you can run inference directly within a browser. We provide several examples of this:
- MNIST where you can draw digits and a small convnet tries to find which one it is! 2️⃣ 7️⃣ 😰
- Image Classification where you can upload images and classify them! 🌄
Embedded: no_std support ⚙️
Burn's core components support no_std. This means it can run in bare metal environment such as embedded devices without an operating system.
As of now, only the NdArray backend can be used in a no_std environment.
 Burn strives to be as fast as possible on as many hardwares as possible, with robust implementations.
We believe this flexibility is crucial for modern needs where you may train your models in the cloud, then deploy on customer hardwares, which vary from user to user.
Burn strives to be as fast as possible on as many hardwares as possible, with robust implementations.
We believe this flexibility is crucial for modern needs where you may train your models in the cloud, then deploy on customer hardwares, which vary from user to user.
Compared to other frameworks, Burn has a very different approach to supporting many backends. By design, most code is generic over the Backend trait, which allows us to build Burn with swappable backends. This makes composing backend possible, augmenting them with additional functionalities such as autodifferentiation and automatic kernel fusion.
We already have many backends implemented, all listed below 👇
WGPU (WebGPU): Cross-Platform GPU Backend 🌐
The go-to backend for running on any GPU.
Based on the most popular and well-supported Rust graphics library, WGPU, this backend automatically targets Vulkan, OpenGL, Metal, Direct X11/12, and WebGPU, by using the WebGPU shading language WGSL. It can also be compiled to Web Assembly to run in the browser while leveraging the GPU, see this demo. For more information on the benefits of this backend, see this blog.
The WGPU backend is our first "in-house backend", which means we have complete control over its implementation details. It is fully optimized with the performance characteristics mentioned earlier, as it serves as our research playground for a variety of optimizations.
See the WGPU Backend README for more details.
Candle: Backend using the Candle bindings 🕯
Based on Candle by Hugging Face, a minimalist ML framework for Rust with a focus on performance and ease of use, this backend can run on CPU with support for Web Assembly or on Nvidia GPUs using CUDA.
See the Candle Backend README for more details.
Disclaimer: This backend is not fully completed yet, but can work in some contexts like inference.
LibTorch: Backend using the LibTorch bindings 🎆
PyTorch doesn't need an introduction in the realm of deep learning. This backend leverages PyTorch Rust bindings, enabling you to use LibTorch C++ kernels on CPU, CUDA and Metal.
See the LibTorch Backend README for more details.
NdArray: Backend using the NdArray primitive as data structure 🦐
This CPU backend is admittedly not our fastest backend, but offers extreme portability.
It is our only backend supporting no_std.
See the NdArray Backend README for more details.
Autodiff: Backend decorator that brings backpropagation to any backend 🔄
Contrary to the aforementioned backends, Autodiff is actually a backend decorator. This means that it cannot exist by itself; it must encapsulate another backend.
The simple act of wrapping a base backend with Autodiff transparently equips it with autodifferentiation support, making it possible to call backward on your model.
use burn::backend::{Autodiff, Wgpu};
use burn::tensor::{Distribution, Tensor};
fn main() {
type Backend = Autodiff<Wgpu>;
let x: Tensor<Backend, 2> = Tensor::random([32, 32], Distribution::Default);
let y: Tensor<Backend, 2> = Tensor::random([32, 32], Distribution::Default).require_grad();
let tmp = x.clone() + y.clone();
let tmp = tmp.matmul(x);
let tmp = tmp.exp();
let grads = tmp.backward();
let y_grad = y.grad(&grads).unwrap();
println!("{y_grad}");
}Of note, it is impossible to make the mistake of calling backward on a model that runs on a backend that does not support autodiff (for inference), as this method is only offered by an Autodiff backend.
See the Autodiff Backend README for more details.
Fusion: Backend decorator that brings kernel fusion to backends that support it 💥
This backend decorator enhances a backend with kernel fusion, provided that the inner backend supports it. Note that you can compose this backend with other backend decorators such as Autodiff. For now, only the WGPU backend has support for fused kernels.
use burn::backend::{Autodiff, Fusion, Wgpu};
use burn::tensor::{Distribution, Tensor};
fn main() {
type Backend = Autodiff<Fusion<Wgpu>>;
let x: Tensor<Backend, 2> = Tensor::random([32, 32], Distribution::Default);
let y: Tensor<Backend, 2> = Tensor::random([32, 32], Distribution::Default).require_grad();
let tmp = x.clone() + y.clone();
let tmp = tmp.matmul(x);
let tmp = tmp.exp();
let grads = tmp.backward();
let y_grad = y.grad(&grads).unwrap();
println!("{y_grad}");
}Of note, we plan to implement automatic gradient checkpointing based on compute bound and memory bound operations, which will work gracefully with the fusion backend to make your code run even faster during training, see this issue.
See the Fusion Backend README for more details.

Just heard of Burn? You are at the right place! Just continue reading this section and we hope you can get on board really quickly.
The Burn Book 🔥
To begin working effectively with Burn, it is crucial to understand its key components and philosophy. This is why we highly recommend new users to read the first sections of The Burn Book 🔥. It provides detailed examples and explanations covering every facet of the framework, including building blocks like tensors, modules, and optimizers, all the way to advanced usage, like coding your own GPU kernels.
The project is constantly evolving, and we try as much as possible to keep the book up to date with new additions. However, we might miss some details sometimes, so if you see something weird, let us know! We also gladly accept Pull Requests 😄
Examples 🙏
Let's start with a code snippet that shows how intuitive the framework is to use! In the following, we declare a neural network module with some parameters along with its forward pass.
use burn::nn;
use burn::module::Module;
use burn::tensor::backend::Backend;
#[derive(Module, Debug)]
pub struct PositionWiseFeedForward<B: Backend> {
linear_inner: nn::Linear<B>,
linear_outer: nn::Linear<B>,
dropout: nn::Dropout,
gelu: nn::Gelu,
}
impl<B: Backend> PositionWiseFeedForward<B> {
pub fn forward<const D: usize>(&self, input: Tensor<B, D>) -> Tensor<B, D> {
let x = self.linear_inner.forward(input);
let x = self.gelu.forward(x);
let x = self.dropout.forward(x);
self.linear_outer.forward(x)
}
}We have a somewhat large amount of examples in the repository that shows how to use the framework in different scenarios. For more practical insights, you can clone the repository and run any of them directly on your computer!
Pre-trained Models 🤖
We keep an updated and curated list of models and examples built with Burn, see the tracel-ai/models repository for more details.
Don't see the model you want? Don't hesitate to open an issue, and we may prioritize it. Built a model using Burn and want to share it? You can also open a Pull Request and add your model under the community section!
Why use Rust for Deep Learning? 🦀
Deep Learning is a special form of software where you need very high level abstractions as well as extremely fast execution time. Rust is the perfect candidate for that use case since it provides zero-cost abstractions to easily create neural network modules, and fine-grained control over memory to optimize every detail.
It's important that a framework be easy to use at a high level so that its users can focus on innovating in the AI field. However, since running models relies so heavily on computations, performance can't be neglected.
To this day, the mainstream solution to this problem has been to offer APIs in Python, but rely on bindings to low-level languages such as C/C++. This reduces portability, increases complexity and creates frictions between researchers and engineers. We feel like Rust's approach to abstractions makes it versatile enough to tackle this two languages dichotomy.
Rust also comes with the Cargo package manager, which makes it incredibly easy to build, test, and deploy from any environment, which is usually a pain in Python.
Although Rust has the reputation of being a difficult language at first, we strongly believe it leads to more reliable, bug-free solutions built faster (after some practice 😅)!

If you are excited about the project, don't hesitate to join our Discord! We try to be as welcoming as possible to everybody from any background. You can ask your questions and share what you built with the community!
Contributing
Before contributing, please take a moment to review our code of conduct. It's also highly recommended to read the architecture overview, which explains some of our architectural decisions. Refer to our contributing guide for more details.
Burn is currently in active development, and there will be breaking changes. While any resulting issues are likely to be easy to fix, there are no guarantees at this stage.
Burn is distributed under the terms of both the MIT license and the Apache License (Version 2.0). See LICENSE-APACHE and LICENSE-MIT for details. Opening a pull request is assumed to signal agreement with these licensing terms.