Project source - udacity
This end-to-end data modeling project entails designing and implementing a data warehouse solution for a music streaming industry. The core responsibility is to model an analytical database for the data analytics team interested in understanding users' activity to improve business decisions. The current data available is operational data, JSON metadata files on the songs in the app.
The project objective includes
- The design of an optimized data ingestion pipeline architecture
- The design of the data warehouse ERD (Entity Relationship Diagram) for the data analytics team.
- The implementation of Data Extraction, Transformation and Loading (ETL).
for architecture design - https://app.diagrams.net/
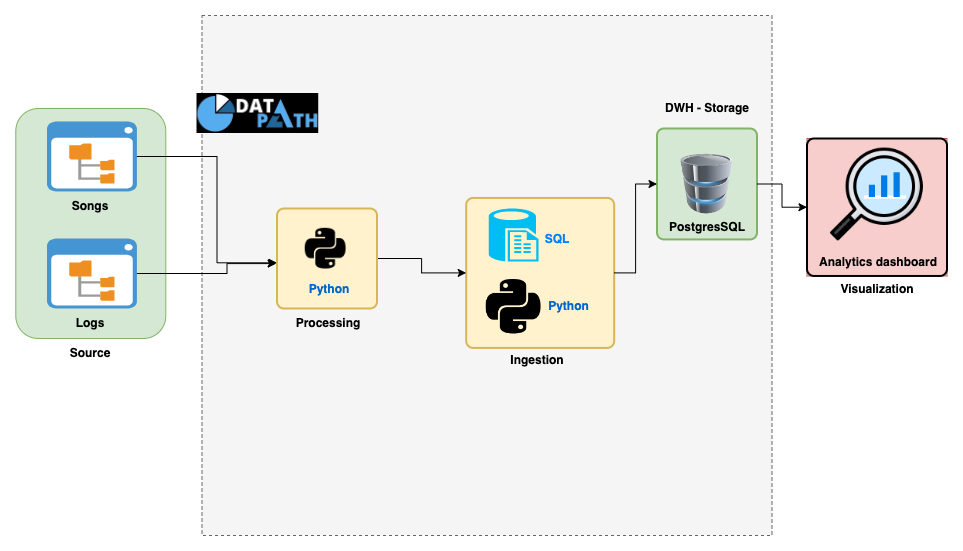
The architecture is purposely designed to achieve the project objective:
Data Source: User log and song data are archived in file directories.Processing: The data are loaded into pandas for data extraction and transformationIngestion: Since the DWH is in Postgres, SQL insert commands together with python are used to load the data in DWH because of SQL readability and simplicity across the data team.Storage: Data is stored in PostgreSQL for analytical purposesVisualization: Analytics dashboard for business decisions.
The data model below shows a star schema optimized for queries on the song play analysis utilizing 3 levels of normalization (1NF, 2NF, and 3NF), where appropriate, using the song and log datasets.
songplays — records in log data associated with song plays i.e. records with page NextSong
songplay_id, start_time, user_id, level, song_id, artist_id, session_id, location, user_agent
users — users in the app user_id, first_name, last_name, gender, level
songs — songs in the music database song_id, title, artist_id, year, duration
artists — artists in the music database artist_id, name, location, latitude, longitude
time — timestamps of records in songplays broken down into the specific unit start_time, hour, day, week, month, year, weekday

In addition to the data files, the project workspace includes five files:
test.ipynbdisplays the first few rows of each table to check the database.create_tables.pydrops and creates the postgres table. This drops (if exists) and create tables. Run at the start of the projectetl.ipynbreads and processes a single file from song_data and log_data and loads the data into the tables. It contains a detailed explanation of the ETL process to the tables.etl.pyreads and processes files from song_data and log_data and loads them into the tables.sql_queries.pycontains all the SQL queries used to perform all SQL command to ingest data to DB