GC micro-optimizations #1919
GC micro-optimizations #1919
Conversation
|
Thanks for your pull request, @rainers! Bugzilla referencesYour PR doesn't reference any Bugzilla issue. If your PR contains non-trivial changes, please reference a Bugzilla issue or create a manual changelog. |
|
Do we have a set of benchmark tests for the GC? How feasible would it be to walk through all history of the GC implementation, running these tests after every change and pushing that out to a statistics / analysis tool. I'm not convinced that we can really accurately gauge performance of the GC in the current way these sort of PRs are done - usually by comparing the difference between A and B. |
They are in druntime/benchmark/gcbench
That's what https://blog.thecybershadow.net/2015/05/05/is-d-slim-yet/ did, though not for the GC benchmarks. Unfortunately it is currently broken because the data set has grown too large. |
? We do run those comparisons for every GC change, so we should keep getting better, at least regarding the GC implementation. |
src/gc/impl/conservative/gc.d
Outdated
|
|
||
| //if (log) debug(PRINTF) printf("\tmark %p\n", p); | ||
| if (p >= minAddr && p < maxAddr) | ||
| if (cast(size_t)(p - minAddr) < rngAddr) |
There was a problem hiding this comment.
Would be better named memRange or memSize, it's not an address.
src/gc/impl/conservative/gc.d
Outdated
| // local stack is full, push it to the global stack | ||
| assert(stackPos == stack.length); | ||
| toscan.push(ScanRange(p1, p2)); | ||
| if (p1 + 1 < p2) |
There was a problem hiding this comment.
That would be better added in the above loops where we break without incrementing the pointer.
In fact you can just factor this out as common code between all branches.
if (bin < B_PAGE)
{
// ...
biti = offsetBase >> pool.shiftBy;
base = pool.baseAddr + offsetBase;
top = base + binsize[bin];
}
else if (bin == B_PAGE)
{
// ...
if(!pointsToBase && pool.nointerior.nbits && pool.nointerior.test(biti))
continue;
}
else
{
// ...
}
if (!pool.mark.set(biti) && !pool.noscan.test(biti))
{
stack[stackPos++] = ScanRange(base, top);
if (stackPos == stack.length)
{
// local stack is full, push it to the global stack
if (++p1 < p2)
toscan.push(ScanRange(p1, p2));
break;
}
}Could help a bit to better fit the normal loop body in the µop-cache.
There was a problem hiding this comment.
That would be better added in the above loops where we break without incrementing the pointer.
Incrementing could be done unconditionally, but I think having a simple common subexpression here might be better than writing back the value to p1.
In fact you can just factor this out as common code between all branches.
That way you have to calculate top unconditionally. I guess it could be slightly better to also move the calculation of base into the conditional.
There was a problem hiding this comment.
Could help a bit to better fit the normal loop body in the µop-cache.
toscan.push() increases the loop size quite a bit because ScanRange.grow() is inlined. Disabling that with pragma(inline, false) didn't have any impact on performance, though.
| if (!pool.mark.set(biti) && !pool.noscan.test(biti)) | ||
| { | ||
| top = base + binsize[bin]; | ||
| goto LaddRange; |
src/gc/impl/conservative/gc.d
Outdated
| // continue with last stack entry | ||
| p1 = cast(void**)base; | ||
| p2 = cast(void**)top; | ||
| goto LnextBody; // skip increment and check |
There was a problem hiding this comment.
That's a second loop around/inside the loop, can we keep reusing the Lagain part for that?
Maybe by hoisting the next variable and setting it here next = ScanRange(base, top), then jumping to the p1 = cast(void**)next.pbot; part.
Seems a bit cleaner to me and the case of the local stack overflowing is rare enough to not worry about 2 cycles or so.
src/gc/impl/conservative/gc.d
Outdated
| p2 = cast(void**)next.ptop; | ||
| // printf(" pop [%p..%p] (%#zx)\n", p1, p2, cast(size_t)p2 - cast(size_t)p1); | ||
| goto Lagain; | ||
| goto LnextBody; |
src/gc/impl/conservative/gc.d
Outdated
|
|
||
| enum shiftBySmall = 4; | ||
| enum shiftByLarge = 12; | ||
| uint shiftBy; // shift count for the divisor used for determining bit indices. |
There was a problem hiding this comment.
Nice, how about using an enum.
enum ShiftBy : ubyte
{
small = 4,
large = 12,
}
ShiftBy shiftBy;
src/gc/impl/conservative/gc.d
Outdated
| size_t pn = offset / PAGESIZE; | ||
| Bins bin = cast(Bins)pool.pagetable[pn]; | ||
| void* base = void; | ||
| void* top = void; |
There was a problem hiding this comment.
Nesting loops is really just a bad habit ;).
src/gc/impl/conservative/gc.d
Outdated
| // because it's ignored for small object pools anyhow. | ||
| auto offsetBase = offset & notbinsize[bin]; | ||
| biti = offsetBase >> pool.shiftBySmall; | ||
| base = pool.baseAddr + offsetBase; |
There was a problem hiding this comment.
Common code, less icache/uop-cache pressure :).
|
Just reran the tests, haven't seen that OOM error before. |
The autotester also hangs rather consistently for Linux_32. I wasn't able to reproduce both failures locally, though. No idea what could be causing this. |
|
Off-topic: How does GC performance compare between DMD, GDC and LDC? |
According to my recent tests LDC seems about 40% faster, both in overall time and GC time. I don't have a reasonable GDC version on Windows. |
|
Addressed all comments but the loop changes. I'll try another simplification. |
8f1cf64 to
8063d22
Compare
8063d22 to
3db208f
Compare
3db208f to
3de7c0e
Compare
no idea why this is necessary but the dyaml test fails without it in commit f658df8
|
Finally figured the cause of the failures, though I don't get why clearing The mark loop is now simplified to only use forward jumps and standard backward continuation. I also noticed a few more redundant operations. |
Just guess from me after looking at the loop. Could it happen that you have two ranges next to each other? - ie: pcache is both the end of the previous and start of the current range. Clearing seems reasonable anyway if you are already altering p1/p2 pointers. |
Hihi, changing sth. w/o understanding why doesn't count as "figuring out" ;).
No I merely preserved the existing semantics. Actually it looks confusing that we don't make a small 16-byte bin druntime/src/gc/impl/conservative/gc.d Line 2010 in 4ee4569 just because it's on the same page (4KB) as the previous element. druntime/src/gc/impl/conservative/gc.d Lines 1982 to 1983 in 4ee4569 Am I misreading this? |
|
Ah, a bit easier to see that |
| // For the NO_INTERIOR attribute. This tracks whether | ||
| // the pointer is an interior pointer or points to the | ||
| // base address of a block. | ||
| bool pointsToBase = (base == sentinel_sub(p)); |
There was a problem hiding this comment.
Was it necessary to remove that name?
Even dmd should be able to optimize this and deciphering base != sentinel_sub(p) isn't that trivial.
There was a problem hiding this comment.
Even dmd should be able to optimize
Unfortunately, it it doesn't just use the comparison in the following if, but stores the result to a byte with sete and uses that, adding a number of gratuitious instructions.
|
I don't see why |
|
Thanks @ibuclaw and @MartinNowak for looking into this.
I don't see how For my own sanity: |
I think it's not so bad, as this shortcuts tests that point to the same page even if it is already marked. Otherwise it would only work for subsequent references of the first hit.
I'm not sure it is so bad. Last time I checked the GC was faster for manually managed memory than C's malloc/free on Windows (not considering the additional benefit of not having to call addRange/removeRange). My actual motivation was improving the precise GC, though, so that it would pass your review ;-) Adding these seemingly simple optimizations there only would bias the benchmark results if not applied to the standard GC, too. |
|
Here's a graph of new benchmarks of the time spent in the GC [ms] for master, the version of the initial PR (intermediate) and the current PR (microopt):
|
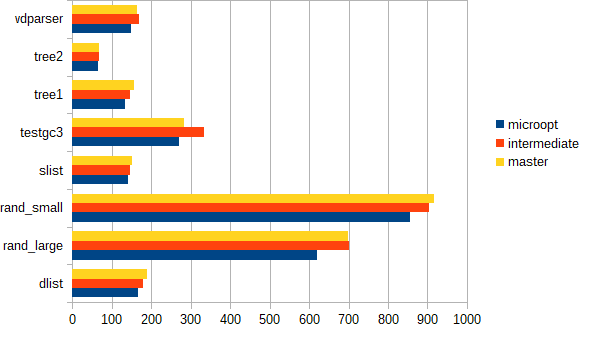
Are you comparing that against dmc's libc malloc/free? |
|
BTW, I've recently started to use plots with error intervals for benchmarks, should I write a short R plot script for the runbench tool as well? |
The requirements for that remain straightforward, only very little performance decrease for existing programs, and only small API/maintainability commitments. |
That's why I meant I should have left these micro-optimzations for the precise GC to compensate for some performance losses ;-) |
That comparison is some time ago, this is the respective comment: #739 (comment). I'm not sure whether the dmc lib was already just a wrapper for the Windows HeapAllocate functions as with the MS libraries. The Windows functions might have improved in the meantime, too. |
These are a few optimizations I recently noticed while staring at the precise GC.
Benchmarks are not very stable, but show an improvement of 1 to 5 %. The graph shows the incremental performance change from bottom to top in percent, unfortunately not in the order of the commits: