Home
![]()
d:swarm is an open-source data management platform for knowledge workers. It can be used for lossless transformation of data from heterogeneous sources into a generic and flexible data model. The result can be utilised for feeding search engine indices or publishing it as open data.
d:swarm is a middle ware solution. It forms the basis of all data management processes in a library or any other (cultural) institution dedicated to the handling of data and metadata. Structurally, d:swarm goes in between existing data management systems (e.g. Integrated Library Systems) and existing front end applications (e.g. a library catalogues or discovery systems).

Finally, d:swarm is an ETL tool with a GUI intended for knowledge workers, e.g., system librarians. Librarians do not need to write scripts, however can create complex transformations by Drag and Drop from a functions library and configuring them in the d:swarm Back Office. Following the concept of community sharing, transformations, mappings and almost any other entity in d:swarm that could be helpful to others is designed for reuse (see, e.g., Springer Journal mappings from SLUB).
d:swarm is realized as a web application that runs in all modern web browsers. The current release of our web application is available at http://demo.dswarm.org. We are looking forward to your feedback, your ideas, your opinions and your contributions at our mailing list or issue tracker. If you want to get in touch with us, drop us a note or reach out via chat, please. We are glad to assist you in evaluating d:swarm.
Start watching these two (#1, #2) presentations, which summarize the vision, motivation and goals of d:swarm on an abstract level.
D:SWARM - A Modern Data Management Approach for Library Automation is our latest talk (at ELAG 2015). See also this record of the presentation.
With d:swarm in its current state you can ...
- import and configure (example) CSV, XML and JSON data resources for further processing
- create projects, define mappings, transformations and filters
- transform data
- export data in JSON, RDF or XML (e.g., for feeding Solr indices).

Configuring data resources, creating mappings to target schemata and exporting the transformation result can be done with the d:swarm Back Office web application. See our user guide for a brief manual of how to utilise the d:swarm Back Office. Example data sets (i.e. small data sets) can directly be processed within the Back Office.
Besides you can ...
- explore the graph data model of your imported and transformed data
Batch-processing large amounts of data can be done with the Task Processing Unit for d:swarm (TPU). This part of the d:swarm data management platform was initially developed by UB Dortmund. You have the choice between two options - the Streaming and the Data Hub variant - when processing data with d:swarm via the TPU.
The d:swarm Streaming variant offers fast processing of large amounts of data and is applicable for many scenarios. You can already utilise it today. The Streaming variant simply processes the source data into our generic data format when processing the transformations and directly outputs the transformation result (as XML or various RDF serialization formats). Unlike in the Data Hub variant this processing variant do not support versioning/archiving (i.e. the data hub is not involved in this processing). See how SLUB Dresden employs d:swarm for transforming and integrating bibliographic data sources.
The Data Hub variant intends to store all data (versioned) in a generic data format (incl. provenance etc.) in the data hub. Archiving and versioning of data is only possible with this processing variant. It could also form the basis for upcoming functionality such as deduplication, FRBR-ization and other data quality improvements. Currently, the Data Hub variant tackles some scalability issues. That's why, we do not recommend to utilise it right now for large amounts of data.

As shown below, the overall architecture consists of three major parts: the BackOffice web application, the TPU, and the back end. The back end, in turn, consists of three modules:
- a controller module that controls the program flow and provides a HTTP API
- a converter that encapsulates Metafacture to transform data
- and a persistence layer to access the metadata repository (currently a relational database; MySQL) and the data hub (currently a graph database; Neo4j).
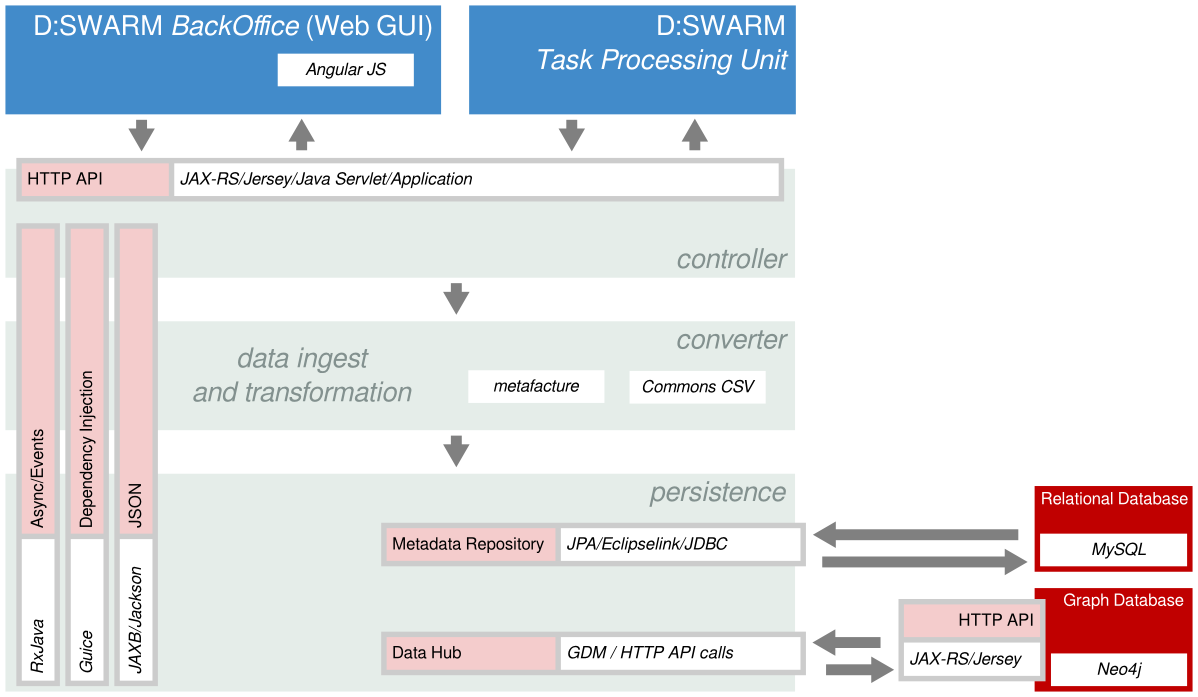
Knowledge workers, e.g., system librarians, usually interact with the BackOffice web application and may use the data hub browser to inspect or visualize the data stored by d:swarm. Administrators or advanced knowledge workers may make use of the TPU to execute data processing tasks on larger amounts of data. Both parts (Back Office + TPU) communicate with the d:swarm backend via the its HTTP API. A documentation of this API is provided via Swagger. Hence it can be simply explored via the Swagger UI. This is a very convenient way to discover and test the back end's functionality.
Just go to http://demo.dswarm.org and try it out or follow the material (incl. VM) of our d:swarm workshop at SWIB16. Finally you can also setup your own local installation and run it from there.
It might be a good idea to run d:swarm locally to get a full insight into the design and workflow of our application. Installation instructions can be found in the Server Install guide (for production and testing the application) or Developer Install guide (for participating in d:swarm development). The d:swarm Configuration provides details on how to configure the system. (For productive use of d:swarm see Server Install.)
Once installed, the Back Office (usually) runs at http://localhost:9999. The local data hub browser may be accessed at http://localhost:7474/browser/. Hint: see Cypher Cheat Sheet for details on Neo4j. You may want to have a look at the MySQL Cheat Sheet for our metadata repository schema (see also our domain model) and use a tool of your choice to explore the database.
You like to contribute? Awesome!
- Code Repository Structure
- Code Repository Handling
- Issue Tracker (register here)
- Mailing List
- @dswarm at Twitter
- d:swarm at Google+
- team contact
- d:swarm at Gitter
- d:swarm at Slack (you can request an invitation over here)
All code from the repositories that belong to our project (see here) is published under APL2 license (except of the d:swarm Neo4j unmanaged extension, which is published under GPL3 license).