New server features #139
New server features #139
Conversation
Also update setup.py to work on debian stable, add wget
Uses new database scheme documented here: https://docs.google.com/document/d/1YTMNmMiU2n_1CMJHeNqWXVlStgYdLX2r2b5XeJWwk5c/edit?usp=sharing util.py has a function which generates the relevant tables in postgres
|
looks like tests caught a problem |
|
My bad, I moved a file and didn't delete an associated .pyc, which made the tests pass on my machine. Fixed. |
| if not os.path.exists(self.answers['rdf_library']): | ||
| os.makedirs(self.answers['rdf_library']) | ||
| with util.cd(self.answers['rdf_library']): | ||
| bz2_rdf = wget.download(RDF_URL) |
There was a problem hiding this comment.
do we need a dependency to wget? We already use requests.
There was a problem hiding this comment.
I didn't realize that before. Looking into it now, wget still does look like a simpler answer, requests doesn't seem to have a single function which downloads a file, and forces you to manually make sure too much memory isn't used while downloading. But I could switch to requests if the extra dependency is an issue.
There was a problem hiding this comment.
Oh, so it's because its a big file, I get it.
wget looks harmless.
https://stackoverflow.com/questions/16694907/how-to-download-large-file-in-python-with-requests-py
| finally: | ||
| os.chdir(prevdir) | ||
|
|
||
| def makeTables(connection, cursor, makeBook=True, makeAuthor=True, makeCover=True, makeExternalLink=True): |
There was a problem hiding this comment.
gitberg has not depended on having a database, and is loaded as a module by projects that do have a database. Giten_site and unglue.it use modules from gitberg, this added dependency could break them, or the db structure might conflict with what they want. so maybe it's better to add this as a module to giten_site, and you can use the django ORM to make this code simpler.
There was a problem hiding this comment.
We agreed on the new database schema for gitensite with the others on the team, so this db structure doesn't conflict with what they want.
The idea is that this will run independently of the web server, as a python process which updates the database whenever the github repos are modified. Perhaps packaging this with gitberg isn't ideal, I'm not sure, but certainly the plan has been to have it not running on django. It isn't exactly part of the command line suite of tools that gitberg provides either.
For now, that's why I had updateDb in a separate folder. Maybe I should put makeTables into that separate folder as well, not sure how it's best to organize it. But really makeTables is just a nice function for duplicating the database setup locally, it's not actually necessary, I just found it convenient.
There was a problem hiding this comment.
what's the reason for not using the django orm? Do you contemplate giten_site talking to this database?
There was a problem hiding this comment.
This database is planned as the database giten_site will talk to, yes. The plan has been to not use django for this just because this isn't going to be part of the webserver. I think it's a lot more straightforward (and lightweight) not to get entangled with django. I don't see any benefit of using django for this.
There was a problem hiding this comment.
if it's not part of the webserver, where is it? How is it configured? Also, if it's not connected to a webserver, I don't understand what it's for.
There was a problem hiding this comment.
We discussed this previously, it's in the shared google doc weekly deliverables under data processing design.
The purpose of this code is to update the database when any git repo is updated. The webserver is connected to the database, but this process is not directly part of it. It also handles turning rdf into yaml. I will add cover generation here also.
There was a problem hiding this comment.
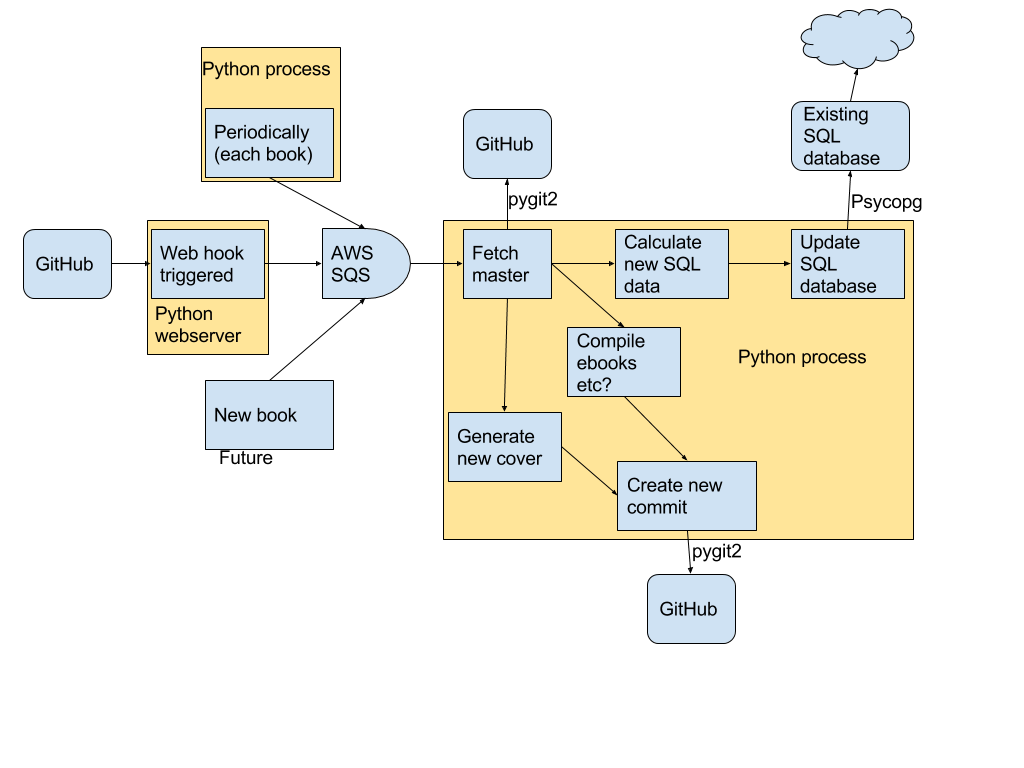
So I guess we need to flesh out some things.
There are 3 yellow boxes. the one marked "python web server" has to be running continuously. is that to run in a separate server/container from the django web server running the website? If so, how will it be administered?
The "periodically each book" process. Is that to be running somewhere else, locally perhaps? and it won't access the db, only SQS? What is it to be doing?
There is a "new book" box. Why is that treated differently from "periodically each book"?
And the big box, is it talking to two different github repos?
It looks like all the arrow point to the database, which seem to imply that we can't use it it the other direction. is that the intent?
Assuming that the django website will want to use information in the database, we'll need ORM models for the tables in the database. I'm not sure its a good idea to have db tables managed in two places.
There was a problem hiding this comment.
just to bring this current: maketables and db dependency should be removed from gitberg
|
|
||
| # Ensure we get a y/n answer |
There was a problem hiding this comment.
Thanks for adding this! It's definitely something that's been needed here.
| sqlCur.execute(sqlInsertAuthor, authorRecord) | ||
| # TODO update author | ||
|
|
||
| def createMetaFile(book): |
There was a problem hiding this comment.
the workflow for metadata file creation was not well documented, mostly because the strategy was not clear. Have you thought out a workflow for creating the metadata files? Note that "enrich" is an expensive operation because it queries wikipedia data. That's why it's an option elsewhere- you want do it infrequently.
There was a problem hiding this comment.
The idea is that this will happen only once per book, when there is a git repo which has only rdf metadata and not yaml. This function is intended to be called via a queuing service, so it will not be called too often, all in all this will be used infrequently, but we do want to ensure that there is a description for every book, as much as possible.
I can add more documentation for the workflow, but it mainly uses existing functionality, it seemed fairly straightforward.
There was a problem hiding this comment.
well the existing workflow was ad hoc. The idea was to create the metadata file it during the process of creating the repo. rsync the pg files locally, add the metadata, then push to github. The problem was what to do when updating/enhancing the repo. You want to be sparing in the use of the github api, so instead we'd git pull, manipulate, then git push. Where it gets complicated is when you have things happening from different places- command line, website, etc. So thinking out and documenting the workflow is very important here. There was no workflow for a metadata-on-commit process, though I assume that will be needed.
There was a problem hiding this comment.
So would you like a separate file with documentation for that? The full workflow uses the other process which handles git hooks and the queuing service, so it shouldn't be only part of this code file I think.
|
Brian can give you more details on the first few questions. The gist of it
is that that the process left of SQS will use git hooks to push updates
into the queue, while the process on the right will read the repos and
update the database. The "periodically each book" process will issue an
update for each book periodically, regardless of whether the git hook was
triggered, in case the git hook was triggered while the server was down, or
some other issue arises. This will also be used for the initial data
loading.
The big box is talking to one github repo, sorry that was unclear, just for
convenience drawing it.
This process does make some queries to the database. However the database
never induces changes in the git repos, which is the intent, in that sense
data does flow in one direction. It's also intended that the django website
will only read from the database, not modify it, or at least, no direct
modification to any book's metadata will be made by the website.
…On Thu, Nov 30, 2017 at 3:28 PM, eshellman ***@***.***> wrote:
***@***.**** commented on this pull request.
------------------------------
In gitenberg/util/util.py
<#139 (comment)>:
> +from contextlib import contextmanager
+import psycopg2
+
+# an exception safer wrapper around cd
+# maybe there's a better place in the code base for this
+# from stackoverflow
***@***.***
+def cd(newdir):
+ prevdir = os.getcwd()
+ os.chdir(os.path.expanduser(newdir))
+ try:
+ yield
+ finally:
+ os.chdir(prevdir)
+
+def makeTables(connection, cursor, makeBook=True, makeAuthor=True, makeCover=True, makeExternalLink=True):
[image: weekly deliverables]
<https://user-images.githubusercontent.com/926513/33452599-befe7dca-d5e0-11e7-9959-42bceebd28f9.png>
So I guess we need to flesh out some things.
There are 3 yellow boxes. the one marked "python web server" has to be
running continuously. is that to run in a separate server/container from
the django web server running the website? If so, how will it be
administered?
The "periodically each book" process. Is that to be running somewhere
else, locally perhaps? and it won't access the db, only SQS? What is it to
be doing?
There is a "new book" box. Why is that treated differently from
"periodically each book"?
And the big box, is it talking to two different github repos?
It looks like all the arrow point to the database, which seem to imply
that we can't use it it the other direction. is that the intent?
Assuming that the django website will want to use information in the
database, we'll need ORM models for the tables in the database. I'm not
sure its a good idea to have db tables managed in two places.
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#139 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AQoQGpl_cjLpy8P51wlnJ1ywTpdr9dR5ks5s7w_rgaJpZM4QvyEv>
.
|
|
will the "periodic" box also manage repo creation and updates? I'm guessing it needs to know about repo status. The current design contemplates use of the website to track and mange this. |
|
suppose we want to use the website to do some sort of metadata crowdsourcing. is there any thing in the design that would make this hard? |
|
The big box looks like it should be a spun up machine, or maybe a lambda process. In case, it might be awkward from a security management view to have it talking directly to a the sql database. If all that its doing is saving the yaml files, then maybe it could put the yaml file to the queing service and have a task update the db via the django server. |
|
Excellent discussion, thanks.
Sorry for getting so much inside the design, but remember I have to live with the code after you all graduate (with high honors, I'm assuming). |
Add functionality to update database when told a git repo has been updated. Uses new database schema.