how to turn off timestamps in exported metrics #2526
Comments
|
Removing timestamps makes many metrics unusable, since we collect metrics out-of-band. I don't think we should support turning off timestamps. |
|
Thanks for the reply.
Is there any way i can integrate cadvisor metrics with pushgateway?
Pushgateway rejects the metrics for the sole reason that it has timestamps.
The authors of pushgateway are adamant that metrics should not have
timestamps. Even if timestamp is ignored, it will work for me but they send
back 400 error.
Any ideas how can i make it work?
…On Wed, Apr 29, 2020, 11:51 PM David Ashpole ***@***.***> wrote:
Removing timestamps makes many metrics unusable, since we collect metrics
out-of-band. I don't think we should support turning off timestamps.
—
You are receiving this because you authored the thread.
Reply to this email directly, view it on GitHub
<#2526 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AE3S5IMQFDAD4J6DYVLR353RPBZKFANCNFSM4MTXUVWA>
.
|
|
I'm not aware of any ways to make that work. |
|
Timestamps in Prometheus metrics cause more problems than just the pushgateway. For example, exposing timetsamps breaks staleness handling. This causes containers that have been removed to be still visible in the data for 5 minutes. I don't know why you think the metrics are "unusable" without timestamps. For Prometheus monitoring, we expect no timestamps for metrics for almost every use case. The metric scrape is intended to be "When Prometheus last saw this data". Exposing timestamps is causing problems for Kubernetes users. |
|
At scrape time, the metrics returned may be up to 15 seconds old. Rates (e.g. cpu usage) didn't really work without timestamps. We might be able to drop timestamps if the metrics are collected "on demand", which was added a few releases back: #1989. |
|
On demand would be much preferred, but exposing timestamps, even a few minutes stale, is just fine. I'm not sure what you did to determine "didn't work", but what cAdvisor is doing right now is much worse. Exposing timestamps is a violation of Prometheus metrics best practices and should not be done. The linked Kubernetes operator issue describes this well. |
|
See #2059. CPU rates can be inaccurate by +- 50%, which most users consider "unusable". Can you link to the best practices documentation which states that timestamps should never be done? |
|
Pre-compute rates shouldn't be exposed on a Promteheus endpoint. They're not useful for Prometheus users. cAdvisor should only expose the raw container CPU counters. I will try and find the documentation on timestamps. |
|
These aren't precomputed. These are the raw CPU counters. That is exactly the problem. If the "real" time at which a counter is collected differs significantly from the scrape time, the rate won't be correct. For example, if we are collecting (in the background) and caching: t0: 0 If we then scrape at t0, t9, t11, t24, t26 (I know prometheus does regular intervals, but this problem still occurs, just not as dramatically), we get rates: t0-t9: 0/9 = 0 The correct rate is 1 for the entire interval, but prometheus would graph numbers that are dramatically incorrect. From my understanding, it is a best practice to perform collection at scrape time, and thus not expose timestamps. However, given that we do not perform collection at scrape time, it seems like we must attach timestamps so that rate computations are correct. Collecting all metrics at once causes problems when running a non-trivial number of containers (e.g. 100), which is why we don't do that by default. However, we did recently add the ability to trigger collection at scrape time. For users that are running low pod density, this could be a good option, and we could remove timestamps in that case. Keep in mind that prometheus server isn't the only consumer of cAdvisor metrics. Not attaching timestamps for cached metrics would break rate calculations for all backends, so doing that across the board doesn't seem like a viable option. |
|
I will have to look at the other issue more closely, but what you're describing is not how Prometheus does calculations. I will have to go over the linked issue, but the conclusions of the linked PR are incorrect. There is not enough information in that PR to show what's going on for real. They have one graph with 6 hours data, and one with 1 hour of data. This means that the default view is going to have a step of 14 seconds in the 1 hour view, and 86 seconds in the 6 hour view. My first guess with #2059 based on what they're showing is that they've configured a scrape interval of 30 seconds. This is going to lead to the weird +- 50% artifacts when you have a miss-matched collection to the scrape. Then when you combine 14 second steps and Prometheus rate extrapolation, you're going to see this +-50% problem. Basically, they've got a self-induced problem, and it's neither cAdvisors or Prometheus that is the cause. |
|
Another thing that is relevant here is that cAdvisor jitters the interval to spread out load. Collection occurs every 10-15 seconds. I'm not entirely sure if that matters for this problem. |
Yes, you're very right about this. The best practice is to collect at scrape time.
No, this is not likely a problem.
No, this shouldn't be a problem. |
Adds a `send_timestamps` option to the prometheus exporter to allow it to send scrape timestamps. By default, when scraping, Prometheus records data assuming that the presented sample is at the instant of the scrape. For data sources that cache the underlying information and do not refresh on scrape, this can lead to metric samples being recorded at the wrong timestamp. For ex, cadvisor caches for many seconds (4-20 in our experience), and so a sample taken "now" may actually be a sample from 20s ago. To handle this situation, the exposition format allows an exporter to advise the Prometheus server of the timestamp of the underlying scrape. OpenTelemetry is aware of the timestamp of the scrape. This change adds an option to have OpenTelemetry send the timestamps of underlying samples out with the Prometheus exporter. Visually, the image shows existing behavior prior to 9.45am and with `send_timestamps: true` set from 9.45am onwards. This is metrics for a job using a single CPU. 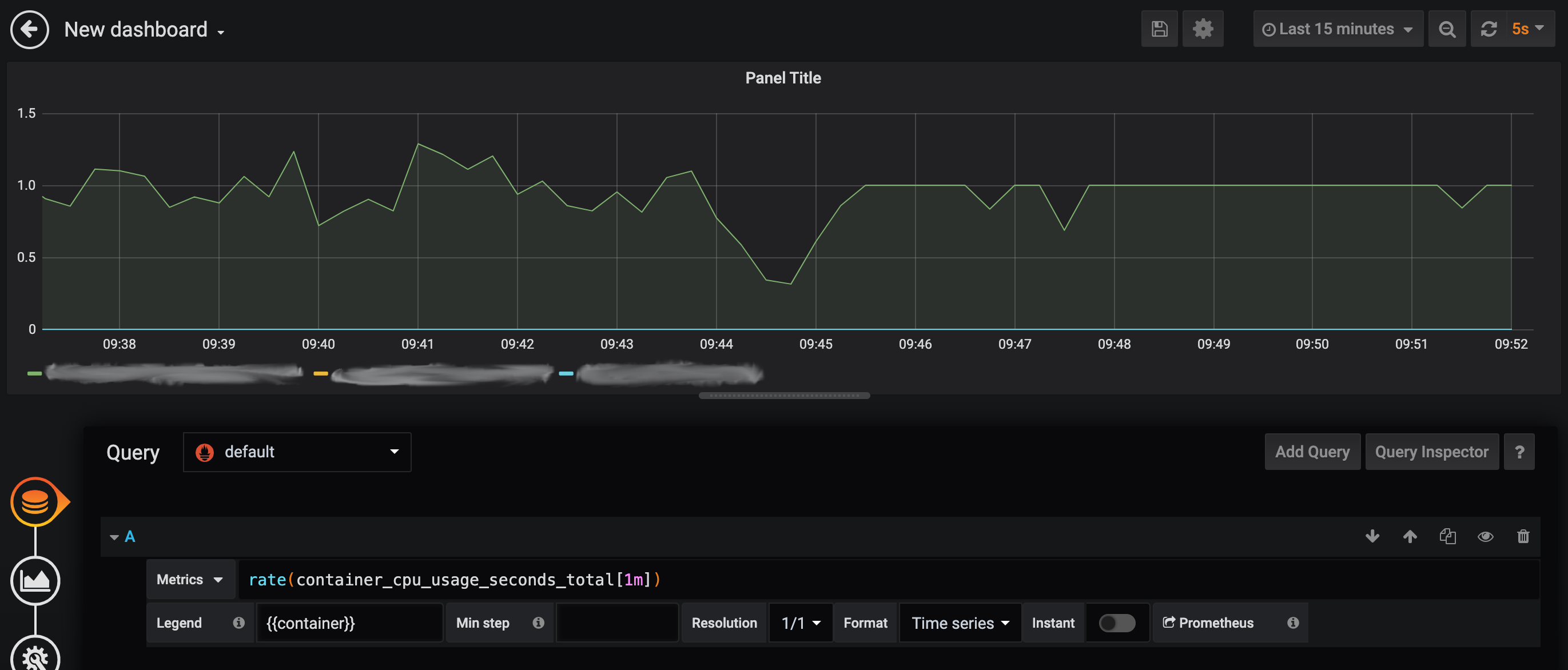 **Related issues:** google/cadvisor#2526 orijtech/prometheus-go-metrics-exporter#11 **Testing:** Test cases have been added. In addition, for e2e test, see screenshot from our environment above. **Documentation:** The `prometheusexporter` README has been updated.
|
I also encountered the same confusion, is there a solution to this problem now? Does cadvisor support turn off timestamps in exported metrics? |
|
@Wayde2014 no i didn't find anything else. But i suppose that was like 2 years ago. Cadvisor might have improved considerably during this time. I ended up running a regexp and dropping time field (as far i can remember). |
|
@Wayde2014 actually, if you look just above your comment, it seems jasonk000 attempted to fix it here
|

{kind=link}
Do you still remember how the regular expression was written, thank you very much. below is the command and its execution result:
|
I have seen these, and I have searched online for nearly 2 days, but there is still no good solution. Thank you for your enthusiastic help. |
@Wayde2014 i don't exactly remember. I remember figuring out the pattern of time stamps i wanted to avoid. My regexp was looking for a bunch of digits e.g I must add that i didn't care much about compute complexity for my application. consider for your application. |
|
@muzammil360 Hi, would you share your regexp rule? thank you. |
|
|
Thanks, that works for me too. |
|
I actually think this can be closed in cadvisor side, since Prometheus supports |
Hi. I am using cadvisor with pushgateway. It so happens that cadvisor exports timestamps along with metrics. This is a problem with pushgateway as it doesn't accept metrics with timestamps. Following is the error returned if I push the metrics using curl
It seems that pushgateway doesn't seem to honor time stamps. Is there anyway I can turn them off in cadvisor? Or if you know an option where pushgateway will ignore the time stamp, even that is acceptable.
NOTE: I know that pushing cadvisor metrics to pushgateway is an anti-pattern but for the time being, I don't have much option.
The text was updated successfully, but these errors were encountered: