https://github.com/gridgentoo/gentoo-tensorflow-overlay
Как Uber масштабировал свою инфраструктуру в реальном времени до [триллиона событий] в день используя Экосистему Hadoop & Spark
Как Uber Engineering проводит аудит Kafka
[uber.com] Introducing Chaperone: How Uber Engineering Audits Kafka End-to-End [Chaperone] - это система аудита Kafka, разработанная в Uber
https://docs.google.com/document/d/1AvkvJjnbjGmMY0GnnwrCGPdhBEfEeG5khL1N9iYwQaE/
[github.com] Chaperone - это система аудита Kafka, разработанная в Uber
https://github.com/gridgentoo/ChaperoneUber

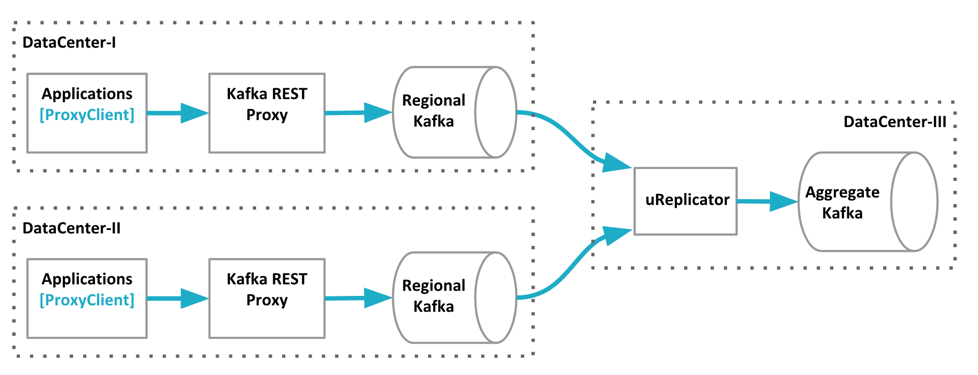
[github.com] uReplicator: Uber Engineering’s Robust Kafka Replicator
https://github.com/gridgentoo/uReplicatorUber
[uber.com] uReplicator: Uber Engineering’s Robust Kafka Replicator https://docs.google.com/document/d/1jxMeu3ctc5UD2MfaurShfi1BiNwtLeUvzkw2VEye3II/edit#heading=h.v1nll5cd1ml6
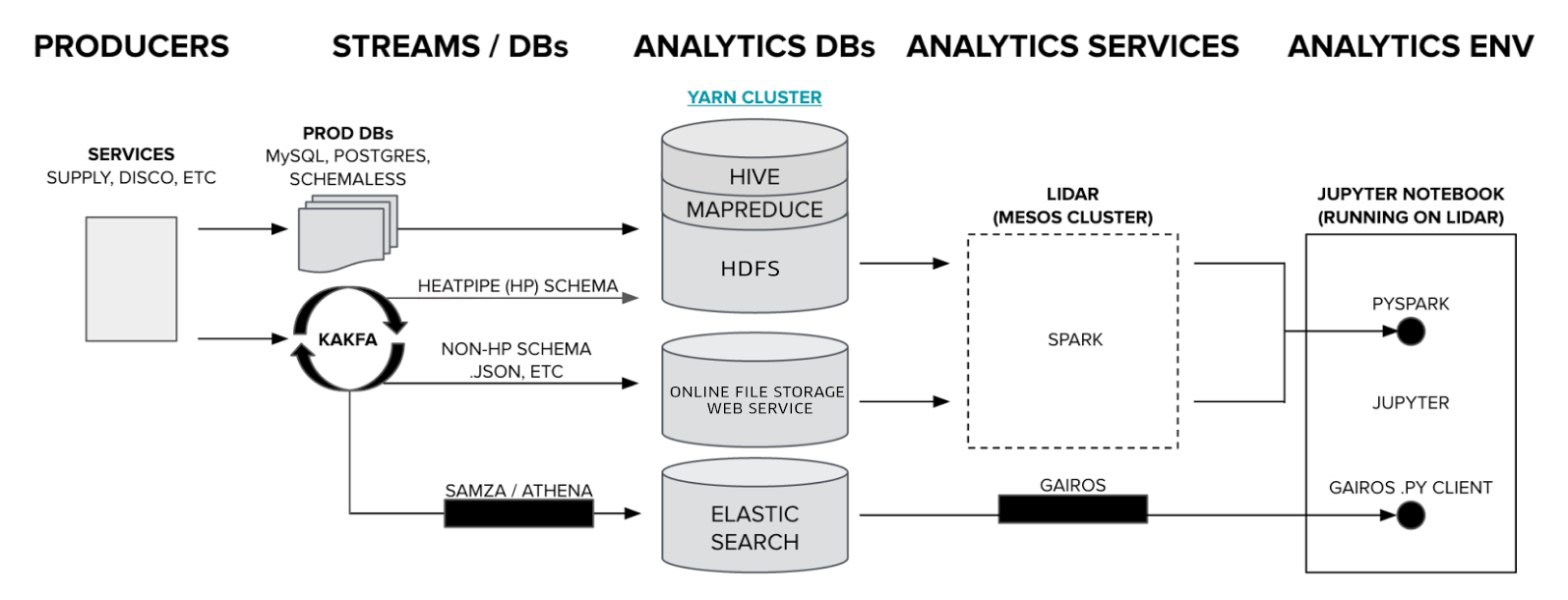
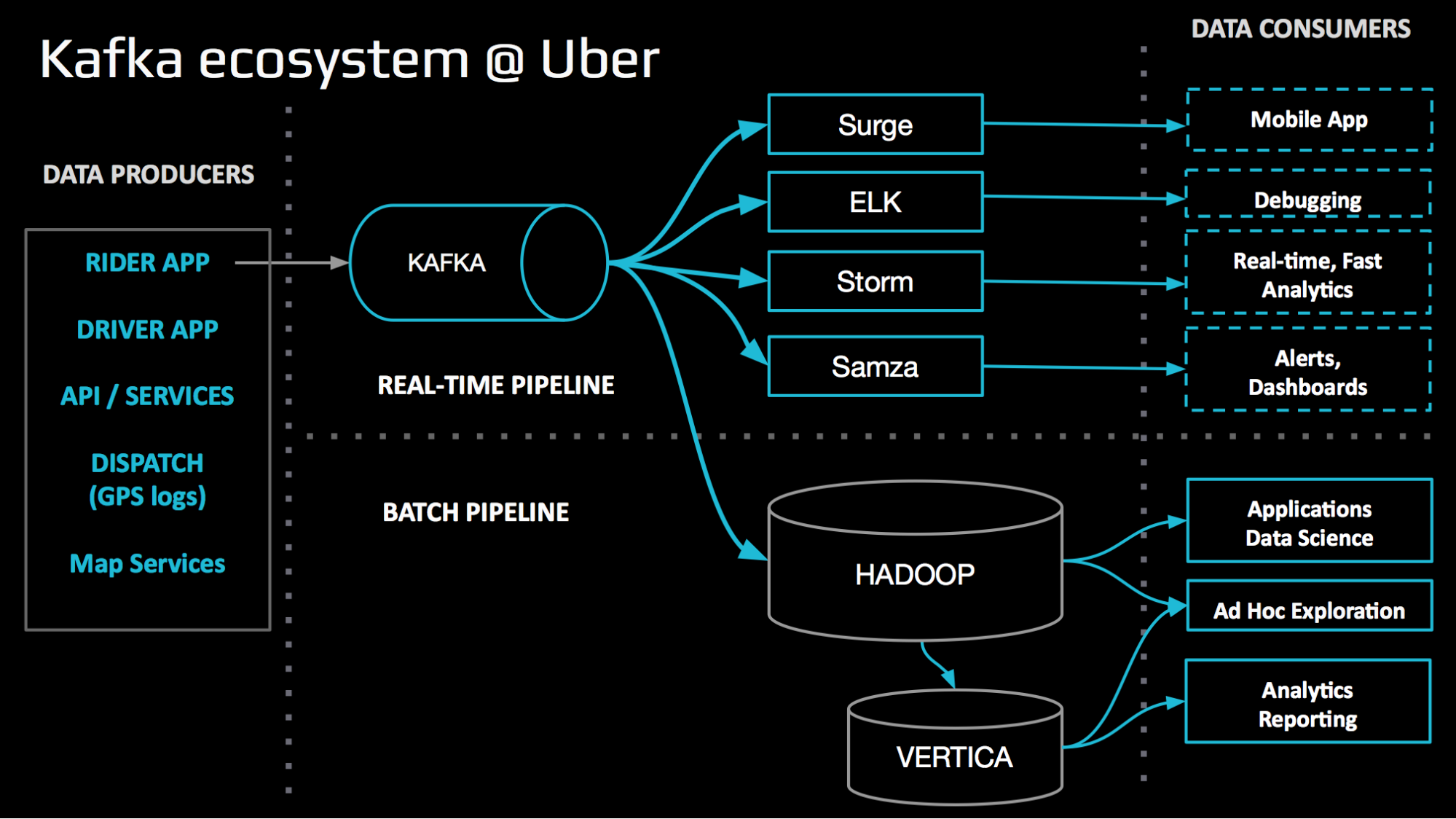
- Как Uber масштабировал свою инфраструктуру в реальном времени до [триллиона событий] в день
- How Uber scaled its Real Time Infrastructure to [Trillion events] per day
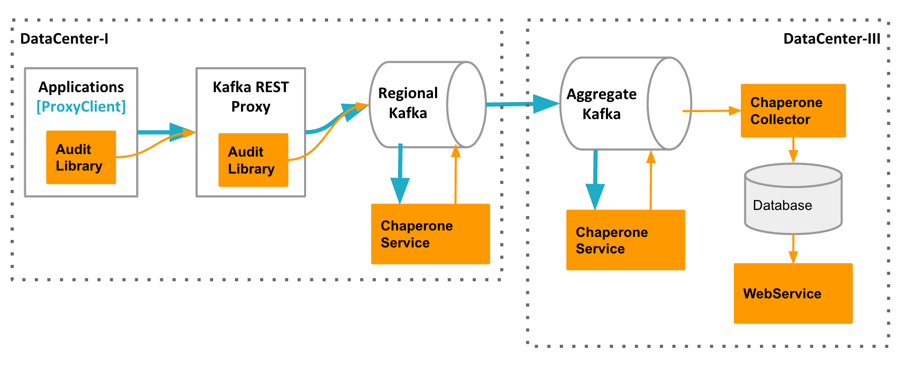
As Kafka audit system, Chaperone monitors the completeness and latency of data stream. The audit metrics are persisted in database for Kafka users to quantify the loss of their topics if any.
Basically, Chaperone cuts timeline into 10min buckets and assigns message to corresponding bucket according to its event time. The stats of the bucket are updated accordingly, like the total message count. Periodically, the stats are sent out to a dedicated Kafka topic, say 'chaperone-audit'. ChaperoneCollector consumes those stats from this topic and persists them into database.
============ Chaperone is made of several components:
- ChaperoneClient is a library that can be put in like Kafka Producer or Consumer to audit messages as they flow through. The audit stats are sent to a dedicated Kafka topic, say 'chaperone-audit'.
- ChaperoneCollector consumes audit stats from 'chaperone-audit' and persists them into database.
- ChaperoneService audits messages kept in Kafka. Since it's built upon uReplicator, it consists of two subsystems: ChaperoneServiceController to auto-detect topics in Kafka and assign the topic-partitions to workers to audit; ChaperoneServiceWorker to audit messages from assigned topic-partitions. In particular, ChaperoneService and ChaperoneCollector together ensure each message is audited exactly once.
Check out the Chaperone project:
git clone git@github.com:uber/chaperone.git
cd chaperone
This project contains everything you’ll need to run Chaperone.
Before you can run Chaperone, you need to build a package for it.
mvn clean package
Or command below to skip tests
mvn clean package -DskipTests
To test Chaperone locally, you need two systems: Kafka, and ZooKeeper. The script “grid” is to help you set up these systems.
- The command below will download, install, and start ZooKeeper and Kafka (named cluster1)
bin/grid bootstrap
- Start ChaperoneService Controller
./ChaperoneDistribution/target/ChaperoneDistribution-pkg/bin/start-chaperone-controller.sh
- Start ChaperoneService Worker
./ChaperoneDistribution/target/ChaperoneDistribution-pkg/bin/start-chaperone-worker.sh
- Create a dummyTopic in Kafka and produce some dummy data:
./bin/produce-data-to-kafka-topic-dummyTopic.sh
- Check if the data is successfully produced to Kafka by console-consumer as below:
./deploy/kafka/bin/kafka-console-consumer.sh --zookeeper localhost:2181/cluster1 --topic dummyTopic
You should get this data:
Kafka topic dummy topic data 1
Kafka topic dummy topic data 2
Kafka topic dummy topic data 3
Kafka topic dummy topic data 4
…
In this example, the topic dummyTopic will be auto-detected and assigned to worker to audit. Periodically, the audit stats are sent to a topic called 'chaperone-audit'.
./deploy/kafka/bin/kafka-console-consumer.sh --zookeeper localhost:2181/cluster1 --topic chaperone-audit
One can also manually add topic to audit by command below:
curl -X POST -d '{"topic":"dummyTopic", "numPartitions":"1"}' http://localhost:9000/topics
To start ChaperoneCollector, MySQL is required and Redis is optional. MySQL is used to persist audit stats and Redis is used to deduplicate. Deduplication can be turned off. The configuration file for ChaperoneCollector is ./config/chaperonecollector.properties, which might be updated to connect to MySQL and Redis.
- Start ChaperoneCollector
./ChaperoneDistribution/target/ChaperoneDistribution-pkg/bin/start-chaperone-collector.sh