Cronicle is a multi-server task scheduler and runner, with a web based front-end UI. It handles both scheduled, repeating and on-demand jobs, targeting any number of worker servers, with real-time stats and live log viewer. It's basically a fancy Cron replacement written in Node.js. You can give it simple shell commands, or write Plugins in virtually any language.
- Single or multi-server setup.
- Automated failover to backup servers.
- Auto-discovery of nearby servers.
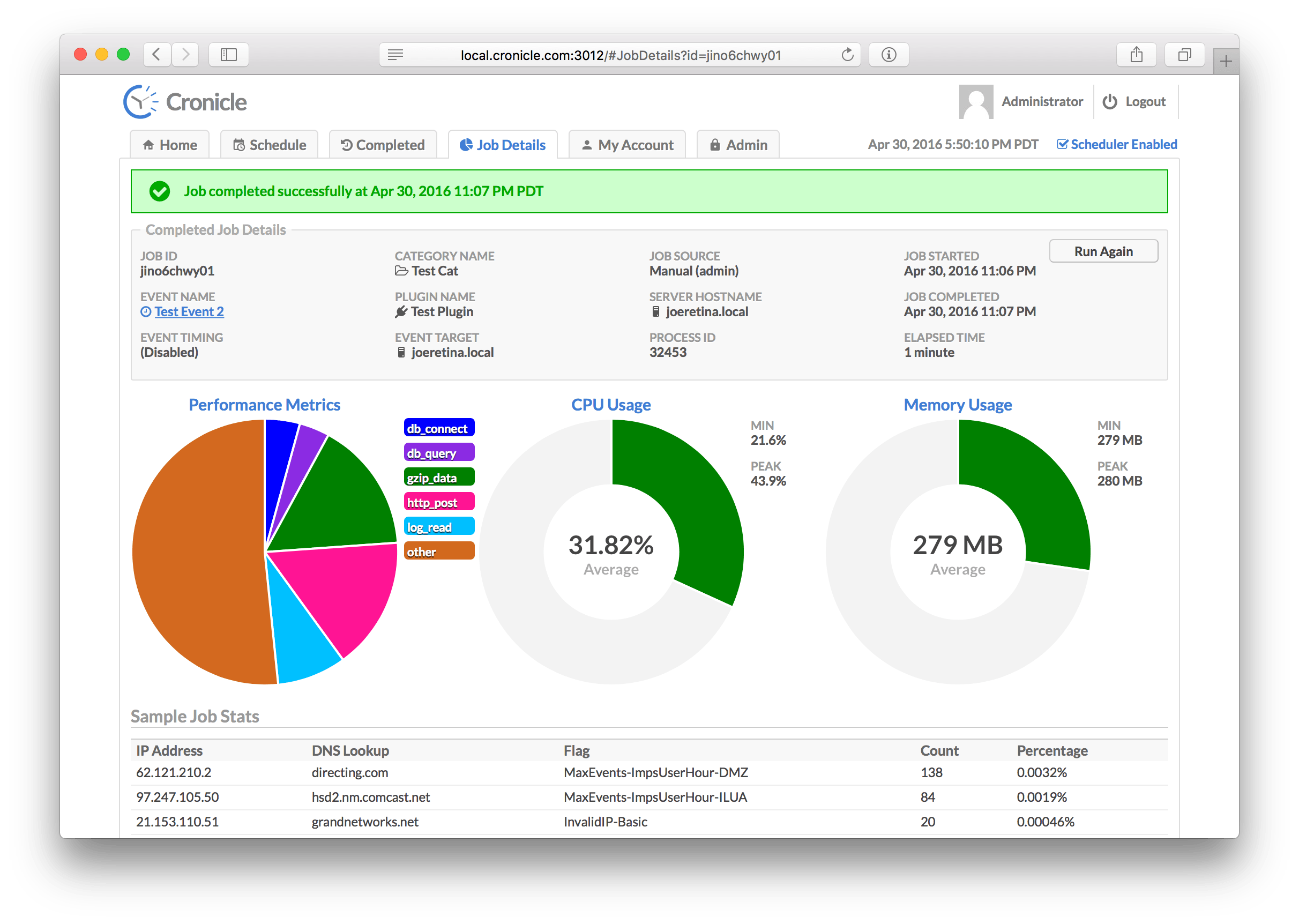
- Real-time job status with live log viewer.
- Plugins can be written in any language.
- Schedule events in multiple timezones.
- Optionally queue up long-running events.
- Track CPU and memory usage for each job.
- Historical stats with performance graphs.
- Simple JSON messaging system for Plugins.
- Web hooks for external notification systems.
- Simple REST API for scheduling and running events.
- API Keys for authenticating remote apps.
The Cronicle documentation is split up across these files:
- → Installation & Setup
- → Configuration
- → Web UI
- → Plugins
- → Command Line
- → Inner Workings
- → API Reference
- → Development
A quick introduction to some common terms used in Cronicle:
| Term | Description |
|---|---|
| Primary Server | The primary server which keeps time and runs the scheduler, assigning jobs to other servers, and/or itself. |
| Backup Server | A worker server which will automatically become primary and take over duties if the current primary dies. |
| Worker Server | A server which sits idle until it is assigned jobs by the primary server. |
| Server Group | A named group of servers which can be targeted by events, and tagged as "primary eligible", or "worker only". |
| API Key | A special key that can be used by external apps to send API requests into Cronicle. Remotely trigger jobs, etc. |
| User | A human user account, which has a username and a password. Passwords are salted and hashed with bcrypt. |
| Plugin | Any executable script in any language, which runs a job and reads/writes JSON to communicate with Cronicle. |
| Schedule | The list of events, which are scheduled to run at particular times, on particular servers. |
| Category | Events can be assigned to categories which define defaults and optionally a color highlight in the UI. |
| Event | An entry in the schedule, which may run once or many times at any interval. Each event points to a Plugin, and a server or group to run it. |
| Job | A running instance of an event. If an event is set to run hourly, then a new job will be created every hour. |
We stand on the shoulders of giants. Cronicle was built using these awesome Node modules:
| Module Name | Description | License |
|---|---|---|
| async | Higher-order functions and common patterns for asynchronous code. | MIT |
| bcrypt-node | Native JS implementation of BCrypt for Node. | BSD 3-Clause |
| chart.js | Simple HTML5 charts using the canvas element. | MIT |
| daemon | Add-on for creating *nix daemons. | MIT |
| errno | Node.js libuv errno details exposed. | MIT |
| font-awesome | The iconic font and CSS framework. | OFL-1.1 and MIT |
| form-data | A library to create readable "multipart/form-data" streams. Can be used to submit forms and file uploads to other web applications. | MIT |
| formidable | A Node.js module for parsing form data, especially file uploads. | MIT |
| glob | Filesystem globber (*.js). |
ISC |
| jstimezonedetect | Automatically detects the client or server timezone. | MIT |
| jquery | JavaScript library for DOM operations. | MIT |
| mdi | Material Design Webfont. This includes the Stock and Community icons in a single webfont collection. | OFL-1.1 and MIT |
| mkdirp | Recursively mkdir, like mkdir -p. |
MIT |
| moment | Parse, validate, manipulate, and display dates. | MIT |
| moment-timezone | Parse and display moments in any timezone. | MIT |
| netmask | Parses and understands IPv4 CIDR blocks so they can be explored and compared. | MIT |
| node-static | A simple, compliant file streaming module for node. | MIT |
| nodemailer | Easy as cake e-mail sending from your Node.js applications. | MIT |
| shell-quote | Quote and parse shell commands. | MIT |
| socket.io | Node.js real-time framework server (Websockets). | MIT |
| socket.io-client | Client library for server-to-server socket.io connections. | MIT |
| uglify-js | JavaScript parser, mangler/compressor and beautifier toolkit. | BSD-2-Clause |
| zxcvbn | Realistic password strength estimation, from Dropbox. | MIT |
Cronicle is known to be in use by the following companies:
The MIT License (MIT)
Copyright (c) 2015 - 2023 Joseph Huckaby
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.