- GraphQL is probably 50% about creating a good Schema and 50% about writing good queries
- To start JSON server - represents an outside API server npm run json:server
- To start express server - represents our internal server npm run dev
-
npm install json-server
-
npm run json:server
-
Getting started
Install JSON Server npm install -g json-server Create a db.json file with some data { "posts": [ { "id": 1, "title": "json-server", "author": "typicode" } ], "comments": [ { "id": 1, "body": "some comment", "postId": 1 } ], "profile": { "name": "typicode" } } Start JSON Server json-server --watch db.json Now if you go to http://localhost:3000/posts/1, you'll get { "id": 1, "title": "json-server", "author": "typicode" }
-
User
- Property Name - Type
- id : Id
- firstName : String
- company_id : Id
- position_id : Id
- users [Id]
- Property Name - Type
-
Company
- Property Name - Type
- id : Id
- name : String
- description : String
- Property Name - Type
-
Position
- Property Name - Type
- id : Id
- name : String
- description: String
- Property Name - Type
- Given a collection of records on a server, there should be a uniform URL and HTTP request method tused to utilize and access that collection of records
-
- how to structure the method calls to access very particular data - gets very tough when we have heavily nested relationships between data
-
- When fetching complexly-related, heavily nested data we can easily run into situations where we are making 5 or 10 HTTP REST calls to get a single piece of data
-
-
as databases grow larger and hold more data - it's more efficient for them to store data in large, many property structures - we may only need a company name to display a component but we get back a whole bunch of other stuff in the process we dont need
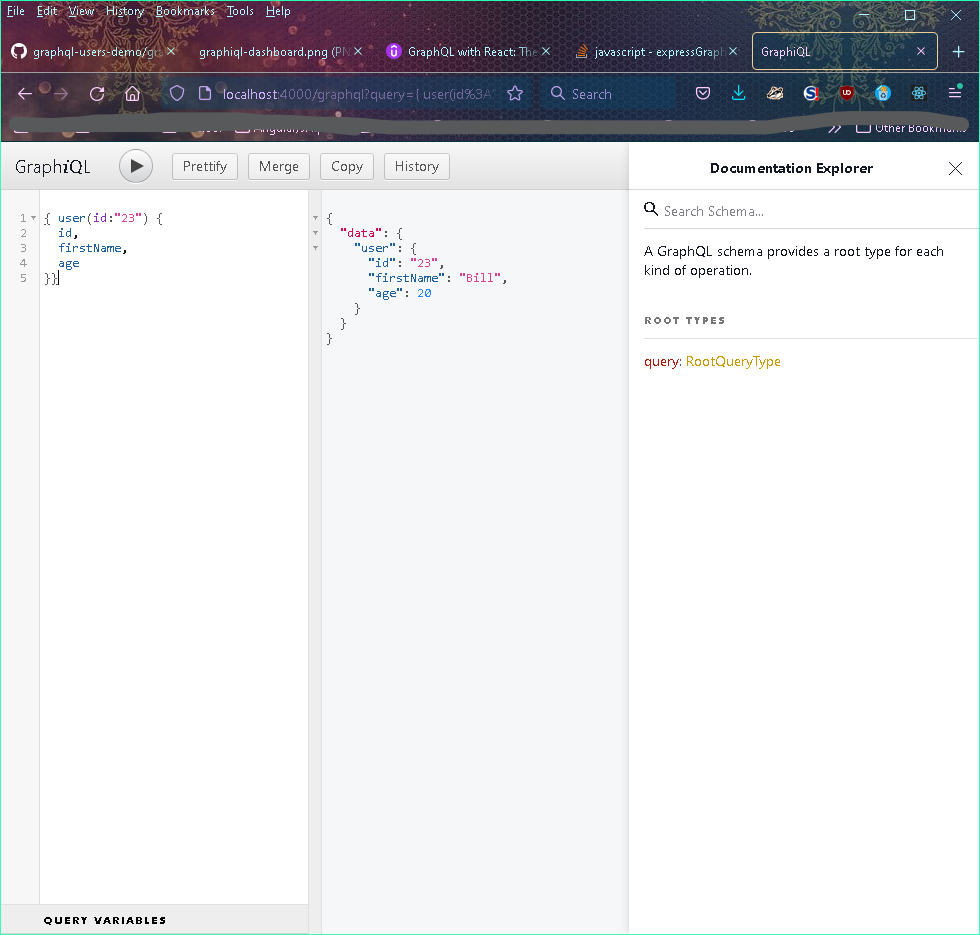
query { user(id: '23') { friends() { company { name } } } }
-
npm install --save express express-graphql graphql lodash

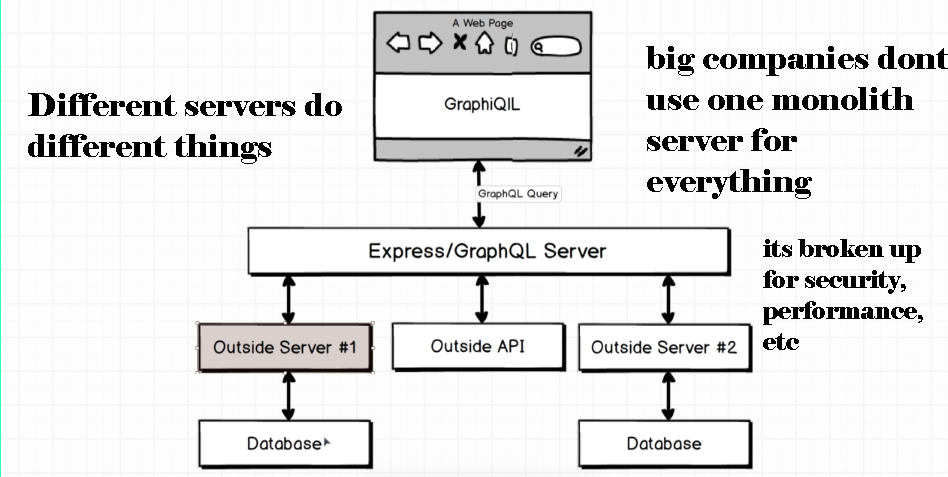
The majority of Production Environment GraphQL queries will be asynchronous requests to other servers or APIs
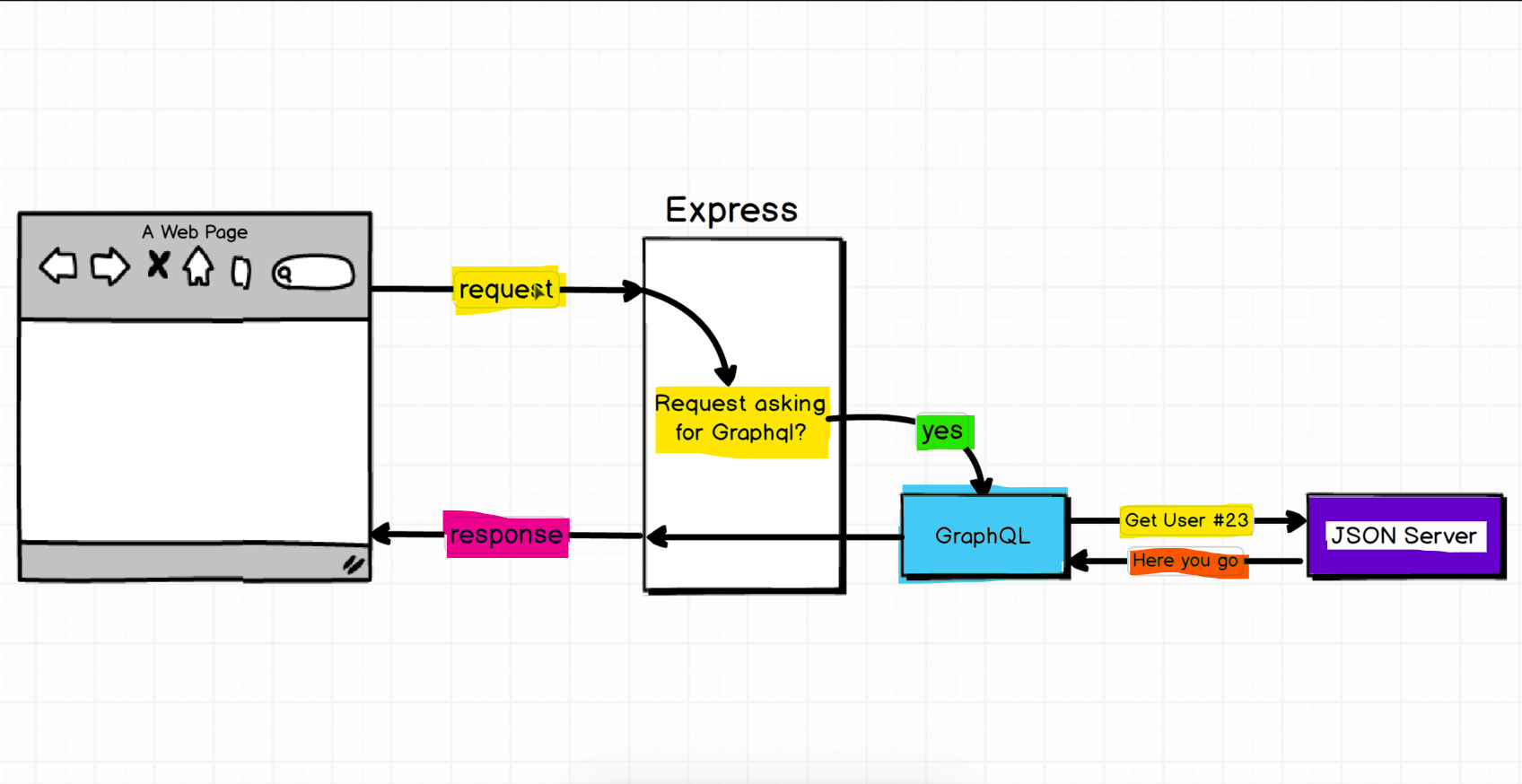
-
File: schema.js
const RootQuery = new GraphQLObjectType({ name: "RootQueryType", fields: { user: { type: UserType, args: { id: { type: GraphQLString } }, resolve(parentValue, args) { return axios.get(`http://localhost:3000/users/${args.id}`) .then((response) => response.data); }, }, }, });
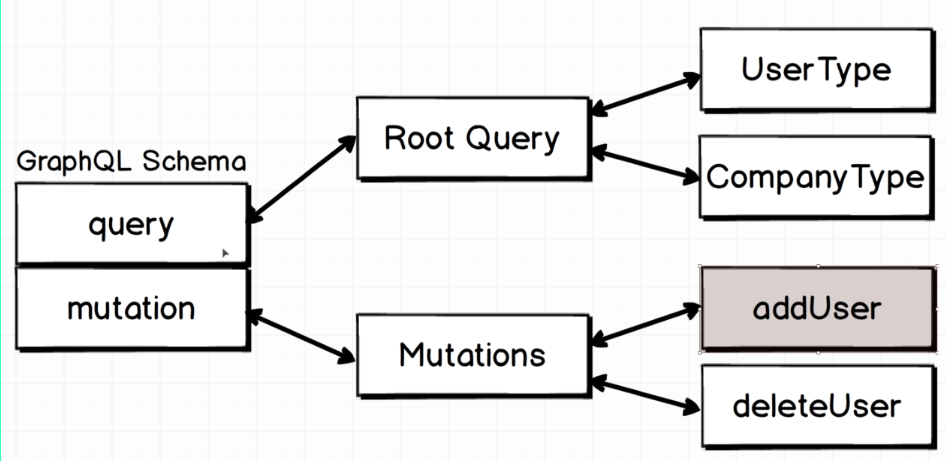
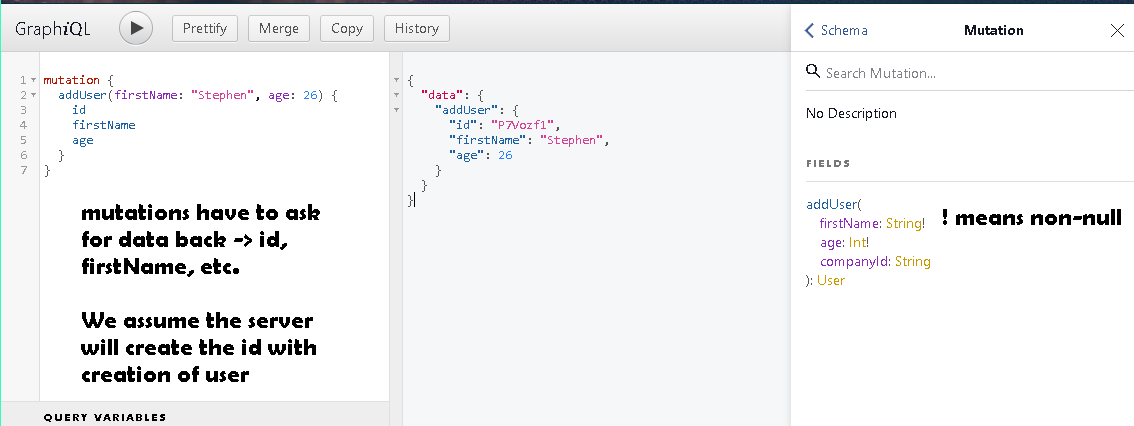
- Mutations are used to change the data stored on are server
- Create, Update, Delete
- Mutations can be difficult to work with so proper form and syntax are key
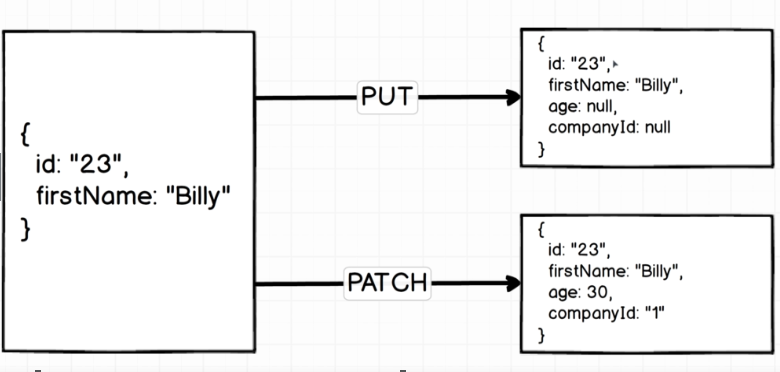
- PUT replaces the entire record with whatever properties are provided - this can lead to losing pre-existing properties that weren't explicitly entered
- PATCH only updates the explicit properties listed in the request, it makes no other changes
-
Remember: The purpose of each of these is to make a request to our GraphQL Server, get the response back and forward it to our React front-end
-
- As simple as possible. Basic queries, mutations. Some simple caching.
-
-
Produced by same people as MeteorJS. Good balance between features and complexity.
-
9 times out of 10 Apollo is the best fit for the problem re: GraphQL Clients
-
-
GraphQL-Express contains the entire Schema in one file - it contains both data Types and queries/mutations
- GraphQL-Express lists Data Type Resolvers (create, update, delete) WHERE the Data Types are defined
- GraphQL-Express syntax is very stable, not going to change but more verbose
-
Apollo splits this out into two files
-
Apollo syntax is less stable, but easier to read
-
Types File
type User { id: String! firstName: String age: Int ... } ... -
Resolvers File
const resolveFunctions = { Query: { users() { return users } } }
-
-
-
-
- Amazing performance for mobile. - Relay was built for mobile.
- By far the most insanely complex, especially re: mutations, like 10x more complex
- Facebook uses Relay because they have the budget to afford the complexity
- Startups should veer away from Relay on a cost-benefit analysis