Adding Utility to Detokenize as list of Strings to Tokenizer Base Class #119
Conversation
|
@mattdangerw Since I also need to test the Unicode tokenizer all it's commits will reflect here too. Should I close the other PR then? |
|
@mattdangerw The PR is ready for review. |
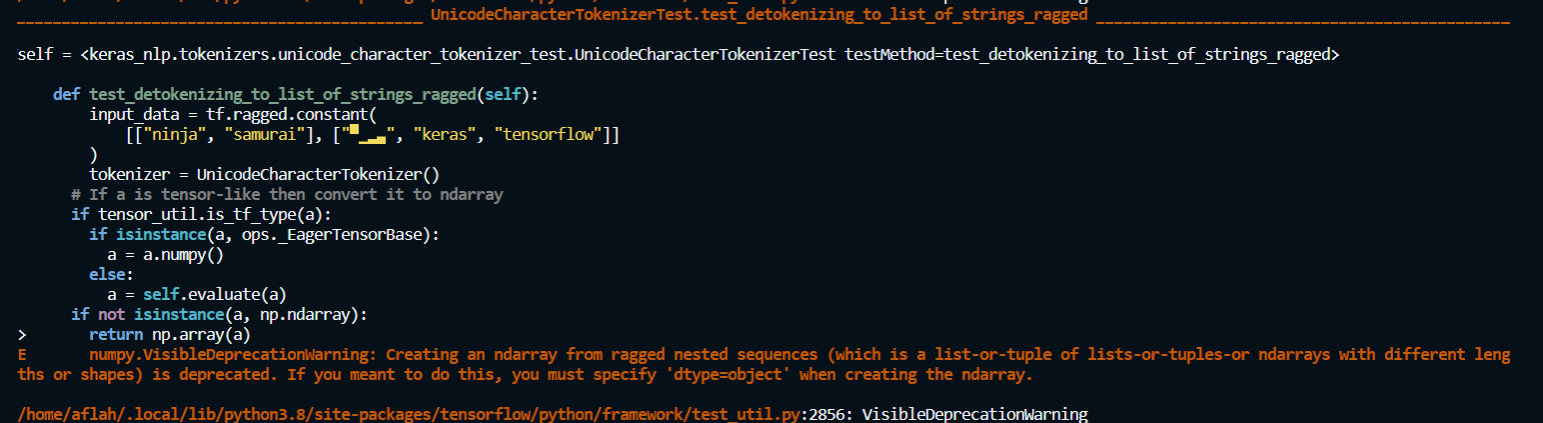
|
@aflah02 sorry missed this comment. We should land this as a follow up to the other PR. Can you rebase this so we can review just this change? Also I would add your tests to the base tokenizer as a that's where the functionality is. You may need to make a new simple subclass of the Tokenizer base class in the unit test. Re that error, I am not sure what is going on there, it may be a incompatibility between tensorflow and numpy when you call ragged.to_list(). If so we probably don't need to fix that here. |
|
@mattdangerw |
Fixes #113
Opening this PR so that we can discuss the name of the utility
I'll write tests as discussed in the issue and fix some problems currently in the meanwhile